
面试-进程与线程
都是操作系统管理的对象,比较容易混淆,但是又是两样完全不同的东西,因此区别很多。从他们区别也可以发散出很多关于操作系统比较重要的知识。所以面试比较常问。
1. 进程到底是什么?
翻了一下书:《操作系统概念》第三章中提及了进程的概念。他是这样说的:
进程是执行中的程序,这是一种非正式说法。进程不只是程序代码(代码块),进程还包含了当前活动,通过程序计数器的值和处理器寄存器的内容来表示。此外,进程还包含进程堆栈段(包括临时数据,如函数参数、返回地址和局部变量)和数据段(包括全局变量)。进程还可能包含堆,是在进程运行期间动态分配的内存。
程序本身不是进程。程序只是被动实体,如存储在磁盘上包含一系列指令的文件内容。而进程是活动实体,它有一个程序计数器来表示下一个要执行的命令和相关资源集合。当一个可执行文件被装入内存时,一个程序才能成为进程。
总结一下进程是什么,是我个人理解:它是一个活动实体,运行在内存上。然后它占用很多独立的资源,比如:内存资源、程序运行肯定涉及CPU计算、占用的端口资源(公共的)、文件资源(公共的)、网络资源(公共的)等等等。要想执行这个进程,首先要有一个可执行文件,有了这个可执行文件,还要有相应的执行需要的资源。所以将可执行文件、当前进程的上下文、内存等资源结合起来,才是一个真正的进程。
那么,我们就可以理解一句话:进程是资源分配的基本单位。
进程中的内存空间(虽然空间大小都一样,下文会说明)是独立的,否则就会出现一种情况:修改自己程序中的某个指针就可以指向其他程序中的地址,然后拿到里面的数据,岂不是很恐怖的场景?

如上图,进程中包含了线程。操作系统可能会运行几百个进程,进程中也可能有几个到几百个线程在运行。
文件和网络句柄是所有进程共享的,多个进程可以去打开同一个文件,去抢占同一个网络端口。
图中还有个内存。这个内存不是我们经常说的内存条,即物理内存,而是虚拟内存,是进程独立的,大小与实际物理内存无关。
2. 寻址空间
比如8086只有20根地址线,那么它的寻址空间就是1MB,我们就说8086能支持1MB的物理内存,及时我们安装了128M的内存条在板子上,我们也只能说8086拥有1MB的物理内存空间。
以前叫卖的32位的机子,32位是指寻址空间为2的32次方。32位的386以上CPU就可以支持最大4GB的物理内存空间了。
3. 为什么会有虚拟内存和物理内存的区别
正在运行的一个进程,他所需的内存是有可能大于内存条容量之和的,比如你的内存条是256M,你的程序却要创建一个2G的数据区,那么不是所有数据都能一起加载到内存(物理内存)中,势必有一部分数据要放到其他介质中(比如硬盘),待进程需要访问那部分数据时,在通过调度进入物理内存。
所以,虚拟内存是进程运行时所有内存空间的总和,并且可能有一部分不在物理内存中,而物理内存就是我们平时所了解的内存条。
关键的是不要把虚拟内存跟真实的插在主板上的内存条相挂钩,虚拟内存它是“虚拟的”不存在,假的啦,它只是内存管理的一种抽象!
4. 虚拟内存地址和物理内存地址是如何映射呢
假设你的计算机是32位,那么它的地址总线是32位的,也就是它可以寻址0 ~ 0xFFFFFFFF(4G)的地址空间,但如果你的计算机只有256M的物理内存0x~0x0FFFFFFF(256M),同时你的进程产生了一个不在这256M地址空间中的地址,那么计算机该如何处理呢?回答这个问题前,先说明计算机的内存分页机制。
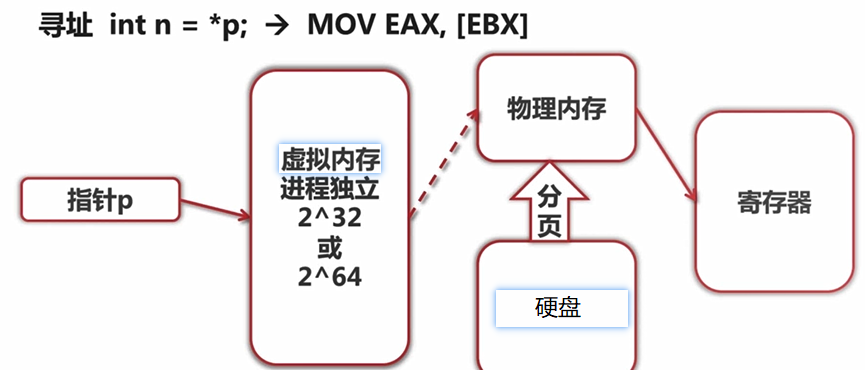
计算机会对虚拟内存地址空间(32位为4G)分页产生页(page),对物理内存地址空间(假设256M)分页产生页帧(page frame),这个页和页帧的大小是一样大的,所以呢,在这里,虚拟内存页的个数势必要大于物理内存页帧的个数。
在计算机上有一个页表(page table),就是映射虚拟内存页到物理内存页的,更确切的说是页号到页帧号的映射,而且是一对一的映射。但是问题来了,虚拟内存页的个数 > 物理内存页帧的个数,岂不是有些虚拟内存页的地址永远没有对应的物理内存地址空间?
不是的,操作系统是这样处理的。操作系统有个页面失效(page fault)功能。操作系统找到一个最少使用的页帧,让他失效,并把它写入磁盘,随后从磁盘中把把需要访问的数据所在的页放到最少使用的页帧中,并修改页表中的映射(即修改页号指向当前页帧),这样就保证所有的页都有被调度的可能了。这就是处理虚拟内存地址到物理内存的步骤。
至于里面如何实现的细节,我没有过多去探究。
5. 什么是虚拟内存地址和物理内存地址
虚拟内存地址由页号和偏移量组成。页号就是上面所说的。偏移量就是我上面说的页(或者页帧)的大小,即这个页(或者页帧)到底能存多少数据。
举个例子,有一个虚拟地址它的页号是4,偏移量是20,那么他的寻址过程是这样的:首先到页表中找到页号4对应的页帧号(比如为8),如果找不到对应的页桢,则用失效机制调入页。如果存在,把页帧号和偏移量传给MMU(CPU的内存管理单元)组成一个物理上真正存在的地址,接着就是访问物理内存中的数据了。
6. 线程里面有什么
写到这里,好像还与本标题无关,即进程和线程到底是什么关系和区别等。但是我们要知道,面试或者学习一个知识点,不是为了学习这个区别而学习, 我们应该学习为什么有进程和线程,有了进程还需要线程吗?有了线程还要进程吗?你说进程是资源分配的单位,分配的是什么资源呢?进程中的内存是咋管理的呢?虚拟内存和物理内存是什么?什么是虚拟内存地址和物理内存地址?等等等,所以面试是千变万化的,重要的是我们尽可能地多问自己几个为什么,然后从为什么开始去逐个击破,形成一个体系。
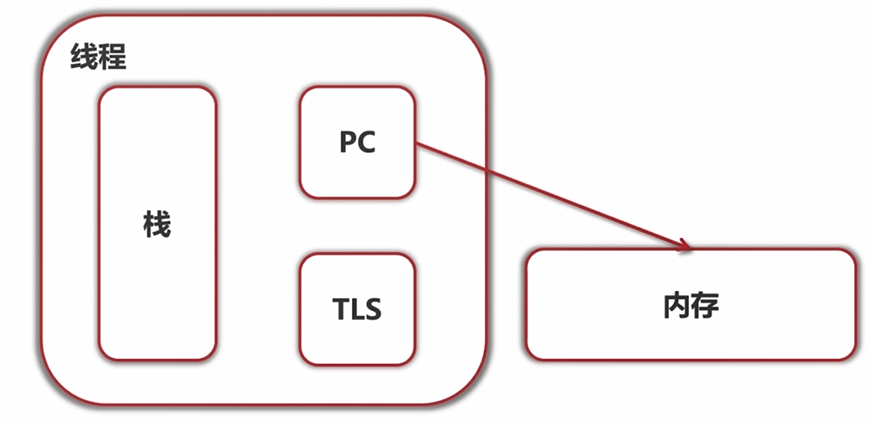
说说这个栈,我们知道,执行程序从主程序入口进入开始,可能会调用很多的函数,那么这些函数的参数和返回地址都会被压入栈中,包括这些函数中定义的临时局部变量都会压入栈中,随着函数的执行完毕,再逐层地弹出栈,回到主函数运行的地方,再继续执行。
PC(program counter),就是程序计数器,指向的下一条指令执行的地址。
由此可见,操作系统运行的其实是一个一个的线程,而进程只是一个隔离资源的容器。
上面说到,PC是指向下一条指令执行的地址。而这些指令是放在内存中的。
我们的计算机大多数是存储程序型的。就是说数据和程序是同时存储在同一片内存里的。
所以我们经常会听到一个漏洞叫做“缓冲区溢出”:比如有一个地方让用户输入用户名,但是黑客输入很长很长的字符串进去,那么很有可能就会超出存放这个用户名的一片缓冲区,而直接侵入到存放程序的地方,那么黑客就可以植入程序去执行。解决方案就是限制输入的用户名长度,不要超过缓冲区大小。
还有一块是TLS(thread local storage),我们知道进程有自己独立的内存,那么我们的线程能不能也有一小块属于自己的内存区域呢?
这个东西,其实很简单,就是说,比如new一个对象,往往是在堆中开辟空间的,但是现在的情况是:在一个函数内,new出来一个对象,这个对象不引用外部对象,也不会被外部引用,是纯粹属于这个函数段,可以理解为这个对象是属于这个函数的局部临时变量。
此时,new这个对象就不需要再去堆中开辟空间了,因为一方面不需要共享,另一方面是在堆中开辟是比较慢的,并且可能有很多函数,这种局部对象零零总总加起来还是很多的,在堆中开辟会浪费空间。
所以,能不能在栈中就可以new出这个对象,反正用完就扔。TLS可以是现在这个。栈中直接new多方便多快,因为不需要走垃圾回收机制,还避免了线程安全问题。可以去搜索:栈上分配和逃逸分析
7. 线程VS进程
到这里,就清晰了很多。我们也可以多多少少理解他们的区别。
可以做个简单的比喻,便于记忆:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-“互斥锁”
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
再补充几句。
- 线程是调度的基本单位,进程是资源分配的基本单位
- 进程间没有共享内存,所以交互要通过TCP/IP端口的等方式来实现。线程间由于有共享内存,所以交互比较方便。
- 线程占用很多资源,而线程只需要分配栈和PC即可。
8. 针对虚拟内存和物理内存的总结
- 每个进程都有自己独立的4G(32位系统下)内存空间,各个进程的内存空间具有类似的结构
- 一个新进程建立的时候,将会建立起自己的内存空间,此进程的数据,代码等从磁盘拷贝到自己的进程空间(建立一个进程,就要把磁盘上的程序文件拷贝到进程对应的内存中去,对于一个程序对应的多个进程这种情况,浪费内存!),哪些数据在哪里,都由进程控制表中的task_struct记录
- 每个进程的4G内存空间只是虚拟内存空间,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址
- 所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。
- 进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,需要用页表来记录
- 页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
- 当进程访问某个虚拟地址,去看页表,如果发现对应的数据不在物理内存中,则缺页异常
- 缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果内存已经满了,没有空地方了,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,需要将此页写回磁盘
9. 关于进程和线程更深的认识
关于为什么要分进程和线程,先抛出结论:
- 进程process:进程就是时间总和=执行环境切换时间+程序执行时间------>CPU加载执行环境->CPU执行程序->CPU保存执行环境
- 线程thread:线程也是时间总和=执行环境切换时间(共享进程的)+程序模块执行时间------>CPU加载执行环境(共享进程的)->CPU执行程序摸块->CPU保存执行环境(共享进程的)
- 进程和线程都是描述CPU工作的时间段,线程是更细小的时间段。
那么,如果CPU时间片临幸本进程,那么这个进程在恢复执行环境之后,执行里面的若干线程就不需要再不停地切换执行环境了,所以说,线程相比于进程是比较轻量的。
在CPU看来所有的任务都是一个一个的轮流执行的,具体的轮流方法就是:先加载程序A的上下文,然后开始执行A,保存程序A的上下文,调入下一个要执行的程序B的程序上下文,然后开始执行B,保存程序B的上下文。。。。
进程就是包换上下文切换的程序执行时间总和 = CPU加载上下文+CPU执行+CPU保存上下文
线程是什么呢?进程的颗粒度太大,每次都要有上下的调入,保存,调出。如果我们把进程比喻为一个运行在电脑上的软件,那么一个软件的执行不可能是一条逻辑执行的,必定有多个分支和多个程序段,就好比要实现程序A,实际分成 a,b,c等多个块组合而成。那么这里具体的执行就可能变成:程序A得到CPU =》CPU加载上下文,开始执行程序A的a小段,然后执行A的b小段,然后再执行A的c小段,最后CPU保存A的上下文。
这里a,b,c的执行是共享了A的上下文,CPU在执行的时候没有进行上下文切换的。这里的a,b,c就是线程,也就是说线程是共享了进程的上下文环境、更为细小的CPU时间段。
进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同。
整理自: