大多数情况下,只要不涉及线程安全问题, Map 基本都可以使用 HashMap ,不过 HashMap 有一个问题,就是迭代 HashMap 的顺序并不是 HashMap 放置的顺序,也就是无序。 HashMap 的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的 Map。
篇幅有点长,但是在理解了HashMap之后就比较简单了。
这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是可以解决有排序需求的场景。
它的底层是继承于 HashMap 实现的,由一个双向循环链表 所构成。
LinkedHashMap 的排序方式有两种:
其中根据访问顺序排序时,每次 get 都会将访问的值移动到链表末尾,这样重复操作就能得到一个按照访问顺序排序的链表。
一、LinkedHashMap数据结构
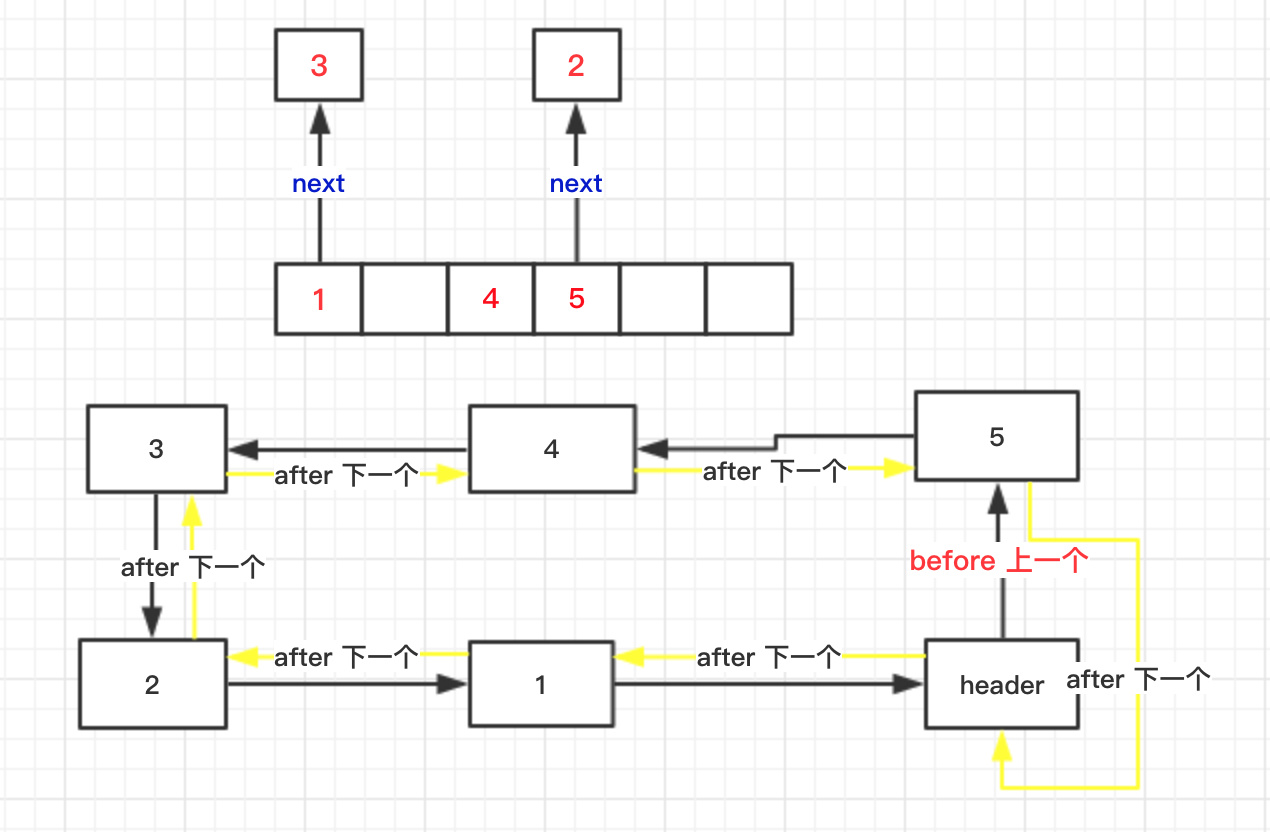
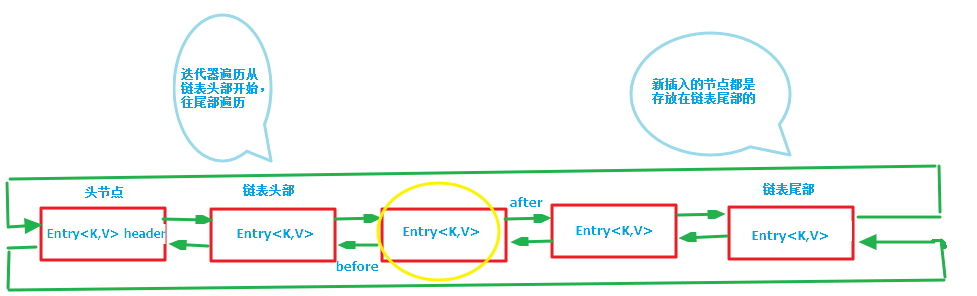
LinkedHashMap是通过哈希表和双向循环链表实现的,它通过维护一个双向循环链表来保证对哈希表迭代时的有序性,而这个有序是指键值对插入的顺序。
我们可以看出,遍历所有元素只需要从header开始遍历即可,一直遍历到下一个元素是header结束。
另外,当向哈希表中重复插入某个键的时候,不会影响到原来的有序性。也就是说,假设你插入的键的顺序为1、2、3、4,后来再次插入2,迭代时的顺序还是1、2、3、4,而不会因为后来插入的2变成1、3、4、2。(但其实我们可以改变它的规则,使它变成1、3、4、2)
LinkedHashMap的实现主要分两部分,一部分是哈希表,另外一部分是链表。哈希表部分继承了HashMap,拥有了HashMap那一套高效的操作,所以我们要看的就是LinkedHashMap中链表的部分,了解它是如何来维护有序性的。
二、demo示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 public static void main (String[] args) System.out.println("----------HashMap插入数据--------" ); Map<String, String> map = new HashMap<String, String>(); map.put("apple" , "a" ); map.put("watermelon" , "b" ); map.put("banana" , "c" ); map.put("peach" , "d" ); Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); System.out.println(entry.getKey() + "=" + entry.getValue()); } System.out.println("----------LinkedHashMap插入数据,按照插入顺序进行排序--------" ); Map<String, String> linkedHashMap = new LinkedHashMap<>(); linkedHashMap.put("apple" , "a" ); linkedHashMap.put("watermelon" , "b" ); linkedHashMap.put("banana" , "c" ); linkedHashMap.put("peach" , "d" ); Iterator<Map.Entry<String, String>> iterator = linkedHashMap.entrySet().iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } System.out.println("----------LinkedHashMap插入数据,accessOrder=true:按照访问顺序进行排序--------" ); Map<String, String> linkedHashMap2 = new LinkedHashMap<String, String>(16 ,0.75f ,true ); linkedHashMap2.put("apple" , "aa" ); linkedHashMap2.put("watermelon" , "bb" ); linkedHashMap2.put("banana" , "cc" ); linkedHashMap2.put("peach" , "dd" ); linkedHashMap2.get("banana" ); linkedHashMap2.get("apple" ); Iterator iter2 = linkedHashMap2.entrySet().iterator(); while (iter2.hasNext()) { Map.Entry entry = (Map.Entry) iter2.next(); System.out.println(entry.getKey() + "=" + entry.getValue()); } System.out.println("-----------" ); linkedHashMap2.put("watermelon" , "bb" ); linkedHashMap2.put("stawbarrey" , "ee" ); linkedHashMap2.put(null , null ); Iterator iter3 = linkedHashMap2.entrySet().iterator(); while (iter3.hasNext()) { Map.Entry entry = (Map.Entry) iter3.next(); System.out.println(entry.getKey() + "=" + entry.getValue()); } }
输出结果是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ----------HashMap插入数据-------- banana=c apple=a peach=d watermelon=b ----------LinkedHashMap插入数据,按照插入顺序进行排序-------- apple=a watermelon=b banana=c peach=d ----------LinkedHashMap插入数据,按照访问顺序进行排序-------- watermelon=bb peach=dd banana=cc apple=aa ----------- peach=dd banana=cc apple=aa watermelon=bb stawbarrey=ee null =null
三、属性
LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序
3.1 继承关系
1 2 3 public class LinkedHashMap <K ,V > extends HashMap <K ,V > implements Map <K ,V >
LinkedHashMap是HashMap的子类,自然LinkedHashMap也就继承了HashMap中所有非private的方法。所以它已经从 HashMap 那里继承了与哈希表相关的操作了,那么在LinkedHashMap中,它可以专注于链表实现的那部分,所以与链表实现相关的属性如下。
3.2 属性介绍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static class Entry <K ,V > extends HashMap .Node <K ,V > Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super (hash, key, value, next); } } transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;final boolean accessOrder;
五、构造方法
1 2 3 4 public LinkedHashMap () super (); accessOrder = false ; }
其实就是调用的 HashMap 的构造方法:
HashMap 实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public HashMap (int initialCapacity, float loadFactor) if (initialCapacity < 0 ) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this .loadFactor = loadFactor; threshold = initialCapacity; init(); }
可以看到里面有一个空的 init(),具体是由 LinkedHashMap 来实现的:
1 2 3 4 5 @Override void init () header = new Entry<>(-1 , null , null , null ); header.before = header.after = header; }
其实也就是对 header 进行了初始化。
六、添加元素
LinkedHashMap并没有重写任何put方法。但是其重写了构建新节点的newNode()方法.
newNode() 会在HashMap的putVal() 方法里被调用,putVal() 方法会在批量插入数据putMapEntries(Map<? extends K, ? extends V> m, boolean evict) 或者插入单个数据public V put(K key, V value)时被调用。
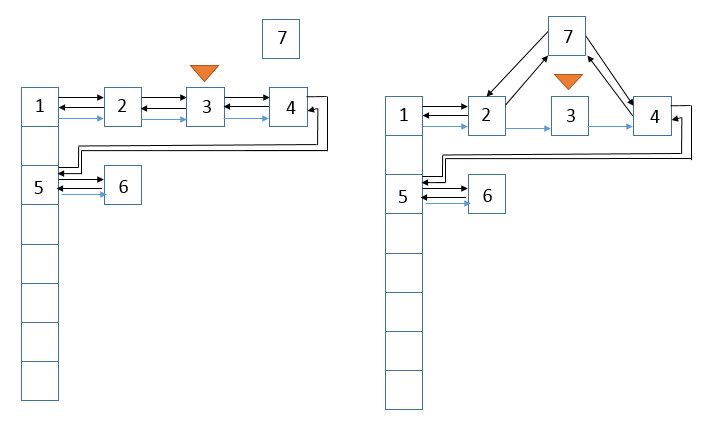
LinkedHashMap重写了newNode(),在每次构建新节点时,通过linkNodeLast(p);将新节点链接在内部双向链表的尾部。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Node<K,V> newNode (int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); linkNodeLast(p); return p; } private void linkNodeLast (LinkedHashMap.Entry<K,V> p) LinkedHashMap.Entry<K,V> last = tail; tail = p; if (last == null ) head = p; else { p.before = last; last.after = p; } }
以及HashMap专门预留给LinkedHashMap的afterNodeAccess() 、afterNodeInsertion() 、afterNodeRemoval() 方法。
1 2 3 4 void afterNodeAccess (Node<K,V> p) void afterNodeInsertion (boolean evict) void afterNodeRemoval (Node<K,V> p)
如果你没有注意到注释的解释的话,你可能会很奇怪为什么会有三个空方法,而且有不少地方还调用过它们。其实这三个方法表示的是在访问、插入、删除某个节点之后,进行一些处理,它们在LinkedHashMap有各自的实现。LinkedHashMap正是通过重写这三个方法来保证链表的插入、删除的有序性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void afterNodeInsertion (boolean evict) LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null , false , true ); } } protected boolean removeEldestEntry (Map.Entry<K,V> eldest) return false ; }
void afterNodeInsertion(boolean evict)以及boolean removeEldestEntry(Map.Entry<K,V> eldest) 是构建LruCache需要的回调,在这可以忽略它们。
七、删除元素
LinkedHashMap也没有重写remove() 方法,因为它的删除逻辑和HashMap并无区别。afterNodeRemoval() 这个回调方法。该方法会在Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) 方法中回调,removeNode() 会在所有涉及到删除节点的方法中被调用,上文分析过,是删除节点操作的真正执行者。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void afterNodeRemoval (Node<K,V> e) LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null ; if (b == null ) head = a; else b.after = a; if (a == null ) tail = b; else a.before = b; }
八、查询元素
LinkedHashMap重写了get()和getOrDefault() 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public V get (Object key) Node<K,V> e; if ((e = getNode(hash(key), key)) == null ) return null ; if (accessOrder) afterNodeAccess(e); return e.value; } public V getOrDefault (Object key, V defaultValue) Node<K,V> e; if ((e = getNode(hash(key), key)) == null ) return defaultValue; if (accessOrder) afterNodeAccess(e); return e.value; }
对比HashMap中的实现,LinkedHashMap只是增加了在成员变量(构造函数时赋值)accessOrder为true的情况下,要去回调void afterNodeAccess(Node<K,V> e) 函数。
1 2 3 4 public V get (Object key) Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }
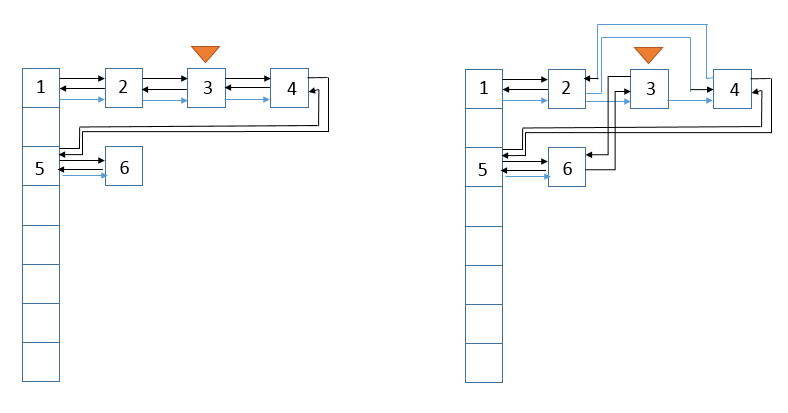
在afterNodeAccess() 函数中,会将当前被访问到的节点e,移动至内部的双向链表的尾部。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void afterNodeAccess (Node<K,V> e) LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null ; if (b == null ) head = a; else b.after = a; if (a != null ) a.before = b; else last = b; if (last == null ) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }
图示(注意这个图,1和6也应该是连在一起的,因为是双向循环链表,所以视为一个小错误):
说明:从图中可以看到,结点3链接到了尾结点后面。
值得注意的是,afterNodeAccess() 函数中,会修改modCount,因此当你正在accessOrder=true的模式下,迭代LinkedHashMap时,如果同时查询访问数据,也会导致fail-fast,因为迭代的顺序已经改变。
九、判断元素是否存在
它重写了该方法,相比HashMap的实现,更为高效。
1 2 3 4 5 6 7 8 9 public boolean containsValue (Object value) for (LinkedHashMap.Entry<K,V> e = head; e != null ; e = e.after) { V v = e.value; if (v == value || (value != null && value.equals(v))) return true ; } return false ; }
对比HashMap,是用两个for循环遍历,相对低效。
1 2 3 4 5 6 7 8 9 10 11 12 13 public boolean containsValue (Object value) Node<K,V>[] tab; V v; if ((tab = table) != null && size > 0 ) { for (int i = 0 ; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null ; e = e.next) { if ((v = e.value) == value || (value != null && value.equals(v))) return true ; } } } return false ; }
十、替换某个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private void transferLinks (LinkedHashMap.Entry<K,V> src, LinkedHashMap.Entry<K,V> dst) LinkedHashMap.Entry<K,V> b = dst.before = src.before; LinkedHashMap.Entry<K,V> a = dst.after = src.after; if (b == null ) head = dst; else b.after = dst; if (a == null ) tail = dst; else a.before = dst; }
十二、总结
LinkedHashMap相对于HashMap的源码比,是很简单的。因为大树底下好乘凉。它继承了HashMap,仅重写了几个方法,以改变它迭代遍历时的顺序。这也是其与HashMap相比最大的不同。
accessOrder默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序。为true时,可以在这基础之上构建一个LruCache.
LinkedHashMap并没有重写任何put方法。但是其重写了构建新节点的newNode()方法.在每次构建新节点时,将新节点链接在内部双向链表的尾部
accessOrder=true的模式下,在afterNodeAccess()函数中,会将当前被访问到的节点e,移动至内部的双向链表的尾部。值得注意的是,afterNodeAccess()函数中,会修改modCount,因此当你正在accessOrder=true的模式下,迭代LinkedHashMap时,如果同时查询访问数据,也会导致fail-fast,因为迭代的顺序已经改变。
nextNode() 就是迭代器里的next()方法 。该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。
而双链表节点的顺序在LinkedHashMap的增、删、改、查时都会更新。以满足按照插入顺序输出,还是访问顺序输出。
它与HashMap比,还有一个小小的优化,重写了containsValue()方法,直接遍历内部链表去比对value值是否相等。
整理自: