Linux重要的一些命令
很多命令之所以重要,是因为用它们会大幅提高工作效率。所以,熟悉它们是我们必须要做的一件事情。下面着重提取了find、grep、管道、wc、awk以及sed等几个命令来看看如何使用。
一、Linux体系结构
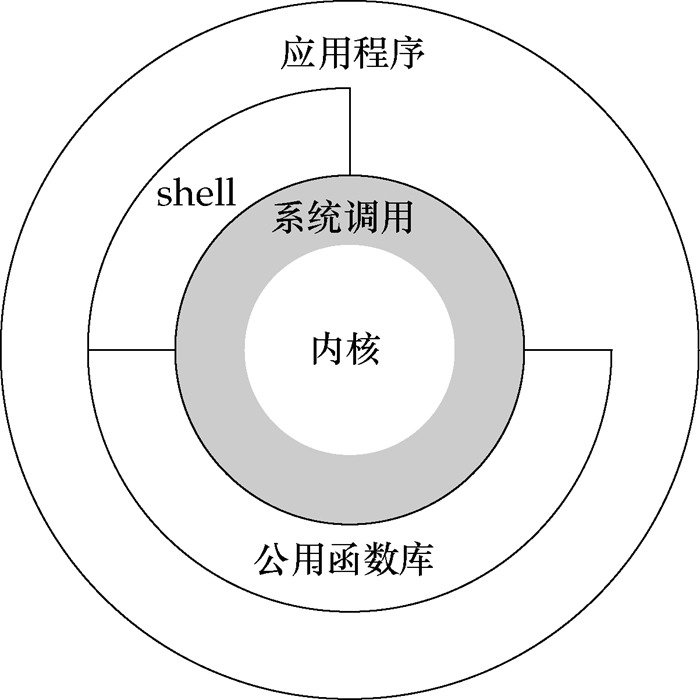
对这幅图进行详细说明一下。
- 体系结构主要分为用户态(用户上层活动)和内核态
- 内核:本质是一段管理计算机硬件设备的程序,这个程序直接管理硬件:包括CPU、内存空间、硬盘接口、网络接口等。所有的计算机操作都要通过内核来操作。
- 系统调用:内核的访问接口,是一种不能再简化的操作(可以认为系统调用已经是最小的原子操作,上层完成一个功能要依托于若干系统调用才能完成)
- 由于系统调用比较基础,要完成一个功能需要很多系统调用组合才能实现,对于程序员来说比较复杂。这个时候怎么办呢?我们可以调用公共函数库:系统调用的组合拳。简化程序员操作。
Shell也是一种特殊的应用程序,是一个命令解释器,可以编程。Shell下通系统调用,上通各种应用,是上层和下层之间粘合的胶水,让不同程序可以偕同工作。- 在没有图形界面之前,用户通过
shell命令行或者可编程的shell脚本可以完成很多事情。
二、如何根据文件名检索文件
- find
- 在指定目录下查找文件
语法 find path [options] params
2.1 精确查找文件
比如我在当前目录(可能在子目录下)下找一个文件叫做test.java:
1 | find -name "test.java" |
这个指令就可以在本目录以及子目录下递归查找这个文件了。
实例:精确查询名字叫snailmall-api-gateway-8080.jar这个文件:

2.2 全局搜索
如果是全局查找,也很简单,无非是从根目录开始递归查找。
1 | find / -name "test.java" |
实例:我对这台服务器全局查找文件名以snailmall开头的所有文件:

2.3 模糊查询
如果找以test打头的文件:
1 | find -name "test*" |
即用 * 通配符就可以模糊查询到以 test 打头的文件。
实例,我的这台服务器上部署了几个关于商城的服务,这个目录下我放了jar包和相应的启动信息文件。我对其进行模糊查询:
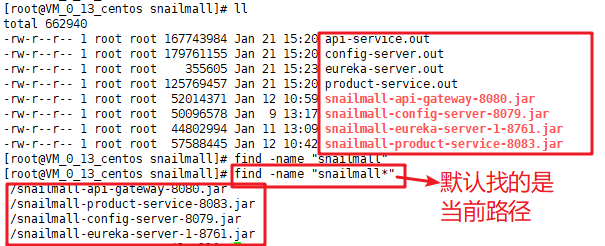
2.4 忽略大小写
1 | find -iname "test*" |
三、如何根据文件内的内容进行检索
3.1 grep命令
- grep
- 查找文件里符合条件的字符串
语法:grep [options] pattern file
比如 test.java 中有一句话是:
1 | System.out.println("i love java"); |
那么如何查找 test.java 中的 java 呢?
1 | grep "java" test* |
这句话意思就是查找以 test 打头的文件中的包含 java 字符串所在的行。
直接输入:
1 | grep "hello" |
会等待用户输入文本。然后再对输入的内容进行检索。
3.2 管道操作符 |
可将指令连接起来,前一个指令的输出作为后一个指令的输入。
1 | find / | grep "test" |
作用同:
1 | find / -name "test" |
注意:
只有前一个指令正确才会再处理。
管道右边命令必须能接收标准输入流,否则传递过程中数据会被抛弃
3.3 grep结合管道
1 | grep 'xxx' hello.info |
可以将 xxx 所在的行全部筛选出来,但是还是特别多,我比如关心这每一行中某个字段的信息,比如是 param[xx12]这种信息。如何实现筛选呢?
1 | grep 'xxx' hello.info | grep -o 'param\[[0-9a-z]*\]' |
这样就只把类似于 param[xx12] 这样的信息清晰地展现出来。
如何过滤掉不要的信息呢?可以用:
1 | grep -v |
比如我们查询 tomcat 进程信息:
1 | ps -ef | grep tomcat |
我们会发现,不仅 tomcat 的信息展现出来了,执行 grep 命令本身的进程信息也展示出来了。我们要将这个 grep 命令过滤掉,只展现 tomcat 进程信息,可以:
1 | ps -ef | grep tomcat | grep -v "grep" |
这样就把 grep 进程信息过滤掉了。
四、如何对文件内容做统计
- awk
- 一次读取一行文本,按输入分隔符进行切片,切成多个组成部分
- 将切片直接保存再内建的变量中,$1$2…($0表示行的全部)
- 支持对单个切片的判断,支持循环判断,默认分隔符为空格
语法:awk [options] ‘cmd’ file
有这样一个文件text1.txt:
1 | proto Recv-Q Send-Q Local Address Foreign Address state |
列出切分出来的第一列和第二列:
1 | awk '{print $1,$2}' test1.txt |
结果:

筛选出第一列为tcp和第二列为1的所在行,将这些行数据全部打印出来:
1 | awk '$1="tcp" && $2==1{print $0}' test1.txt |
结果:

打印带有表头的数据:
1 | awk '($1="tcp" && $2==1) || NR==1 {print $0}' test1.txt |

默认是以空格分隔,那么以逗号或者其他符号可以吗?答案当然是可以。对于这样的文件text2.txt:
1 | adas,123 |
1 | awk -F "," '{print $2}' text2.txt |
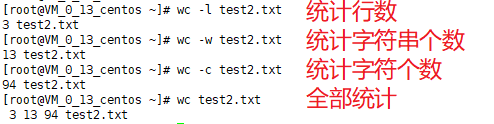
五、WC统计
有一个文件test2.txt,里面的内容是:
1 | swg123eh shwf |
六、sed命令
sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作
sed [-n/e/f/r/i] ‘command’ 输入文本
常用选项:
- -n∶使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
- -e∶直接在指令列模式上进行 sed 的动作编辑;
- -f∶直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作;
- -r∶sed 的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
- -i∶直接修改读取的档案内容,而不是由萤幕输出。
常用命令:
- a ∶新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c ∶取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d ∶删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i ∶插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p ∶列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~
- s ∶取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
这里我就主要看一下批量替换这个功能。
如果只是给一个文件中的若干字符串批量替换,只需要:
1 | sed -i "s/oldstring/newstring/g" filename |
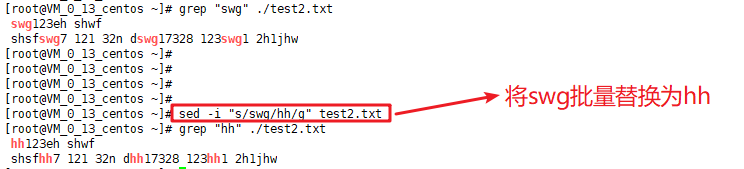
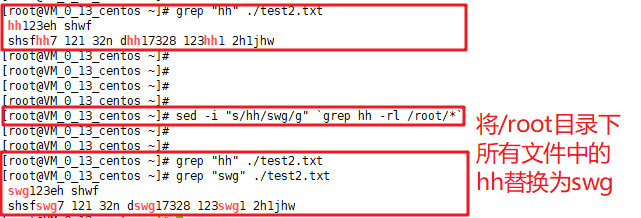
如果是对某一路径下很多的文件批量替换:
1 | sed -i "s/oldstring/newstring/g" `grep oldstring -rl path` |
其中,oldstring是待被替换的字符串,newstring是待替换oldstring的新字符串,grep操作主要是按照所给的路径查找oldstring,path是所替换文件的路径;
- -i选项是直接在文件中替换,不在终端输出;
- -r选项是所给的path中的目录递归查找;
- -l选项是输出所有匹配到oldstring的文件;
这里只是模拟一下,将目录下的所有文件进行批量修改: