
ConcurrentHashMap
对于并发场景下,推荐使用线程安全的 concurrentHashMap ,而不是 HashMap 或者是 HashTable .concurrentHashMap在JDK7和JDK8中的实现原理是不一样的。本文分别对其核心思想和方法进行阐述。
一、JDK7实现
ConcurrentHashMap 的内部细分了若干个小的 HashMap ,称之为段( SEGMENT )。 ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment ,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
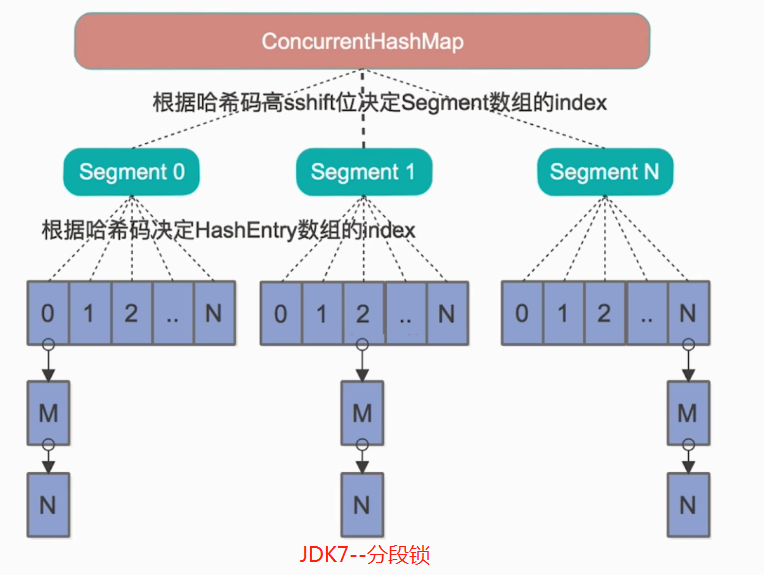
如图所示,是由 Segment 数组、HashEntry 数组组成,和 HashMap 一样,仍然是数组加链表组成。
ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel ( Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
1.1 get方法
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值.
内部 HashEntry 类 :
1 | static final class HashEntry<K,V> { |
1.2 put方法
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。
首先也是通过 Key 的 Hash 定位到具体的 Segment,在 put 之前会进行一次扩容校验。这里比 HashMap 要好的一点是:HashMap 是插入元素之后再看是否需要扩容,有可能扩容之后后续就没有插入就浪费了本次扩容(扩容非常消耗性能)。
而 ConcurrentHashMap 不一样,它是在将数据插入之前检查是否需要扩容,之后再做插入操作。
1.3 size方法
每个 Segment 都有一个 volatile 修饰的全局变量 count ,求整个 ConcurrentHashMap 的 size 时很明显就是将所有的 count 累加即可。但是 volatile 修饰的变量却不能保证多线程的原子性,所有直接累加很容易出现并发问题。
但如果每次调用 size 方法将其余的修改操作加锁效率也很低。所以做法是先尝试两次将 count 累加,如果容器的 count 发生了变化再加锁来统计 size。
在 JDK7 中,第一种方案他会使用不加锁的模式去尝试多次计算 ConcurrentHashMap 的 size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的。
第二种方案是如果第一种方案不符合,他就会给每个 Segment 加上锁,然后计算 ConcurrentHashMap 的 size 返回。其源码实现:
1 | public int size() { |
其中
1 | // 锁之前重试次数 |
二、JDK8实现
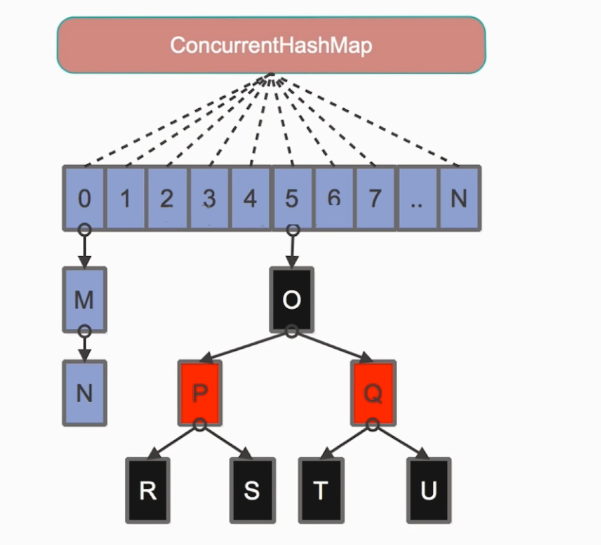
jdk8 中的 ConcurrentHashMap 数据结构和实现与 jdk7 还是有着明显的差异。
其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
也将 jdk7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。
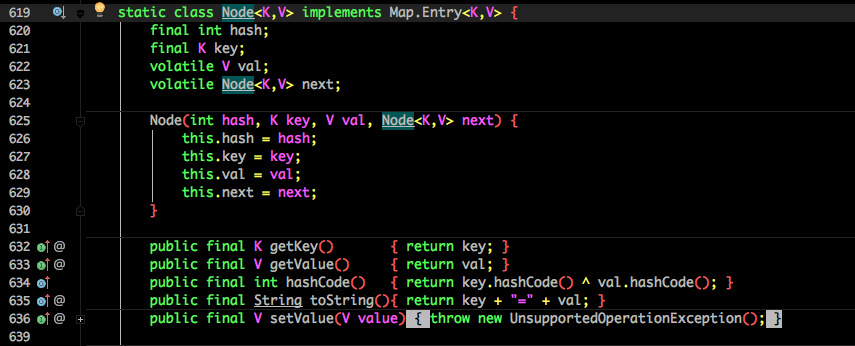
其中的 val next 都用了 volatile 修饰,保证了可见性。
2.1 put方法
重点来看看 put 函数:
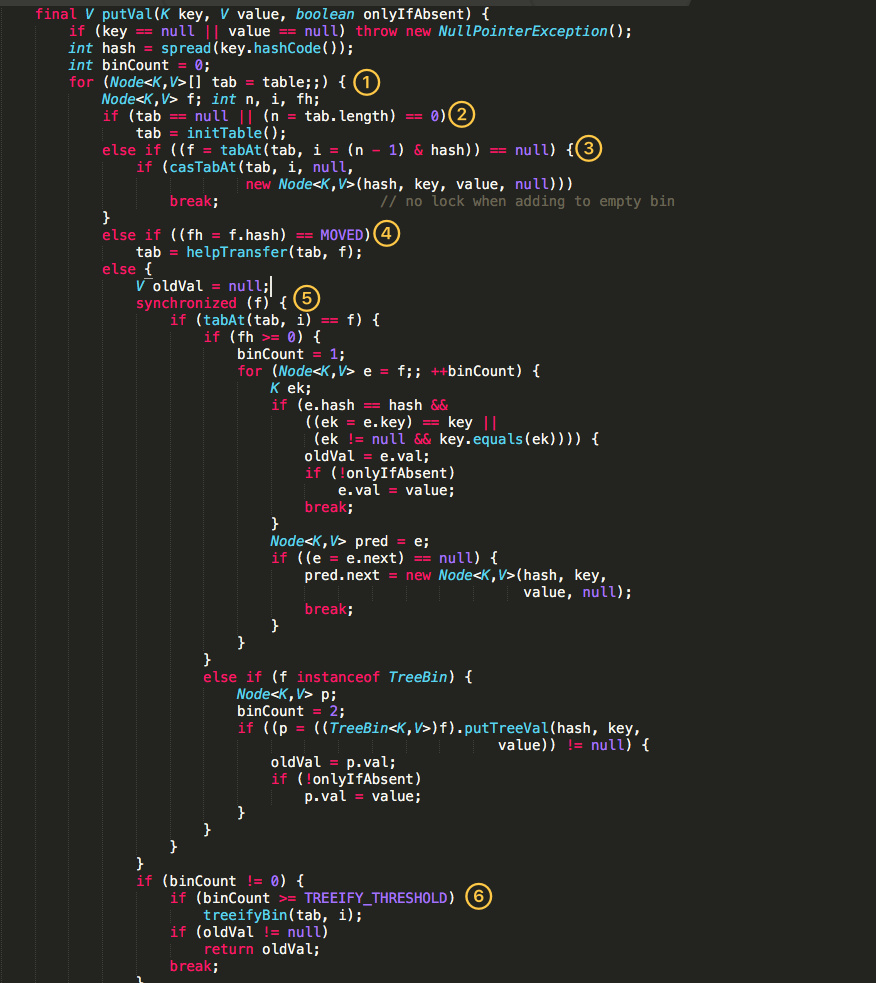
- 根据
key计算出hashcode。 - 判断是否需要进行初始化。
f即为当前key定位出的Node,如果为空表示当前位置可以写入数据,利用CAS尝试写入,失败则自旋保证成功。- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足(不需要初始化、Node不为空、不需要扩容),则利用
synchronized锁写入数据。 - 如果数量大于
TREEIFY_THRESHOLD则要转换为红黑树。
2.2 get方法
- 根据计算出来的
hashcode寻址,如果就在桶上那么直接返回值。 - 如果是红黑树那就按照树的方式获取值。
- 都不满足那就按照链表的方式遍历获取值。
2.3 size方法
JDK8 实现相比 JDK7 简单很多,只有一种方案,我们直接看 size() 代码:
1 | public int size() { |
可能你会有所疑问,ConcurrentHashMap 中的 baseCount 属性不就是记录的所有键值对的总数吗?直接返回它不就行了吗?
之所以没有这么做,是因为我们的 addCount 方法用于 CAS 更新 baseCount,但很有可能在高并发的情况下,更新失败,那么这些节点虽然已经被添加到哈希表中了,但是数量却没有被统计。
还好,addCount 方法在更新 baseCount 失败的时候,会调用 fullAddCount 将这些失败的结点包装成一个 CounterCell 对象,保存在 CounterCell 数组中。那么整张表实际的 size 其实是 baseCount 加上 CounterCell数组中元素的个数。
三、总结
- 并发情况下请使用
concurrentHashMap - 在
jdk7中,用的是分段锁,默认是12段,那么并发量最多也就12.get不加锁,第一次hash定位到segment,第二次hash定位到元素,元素值是用volatile保证内存可见性put需要加锁,hash定位到segment后,先检查是否需要扩容再插入。size先使用不加锁的模式去尝试多次计算size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入;如果不一致,给每个Segment加上锁再依次去计算个数
- 在
jdk8中,采用了CAS+synchronized来保证并发安全性put的过程比较复杂,简单来说是:先计算hash定位到node—》判断是否初始化—》如果node为空则表示可以插入,用cas插入—》判断是否需要扩容—》如果不需要初始化、Node不为空、不需要扩容,则利用synchronized锁写入数据—》判断是否需要转换为红黑树get就比较简单,直接根据hash定位到node,然后以链表或者红黑树的方式拿到size方法就一种方案:baseCount+CounterCell[]中所有元素
整理自: