
数据库事务核心问题
本文从事务引出了Mysql InnoDB RR隔离级别下是如何防止幻读的。
1. 数据库事务的四大特性
最重要的是ACID特性。
- 原子性(Atomicity):事务要么都成功要么都失败
- 一致性(Consistency):关系型数据库有很多约束,事务前后都要满足这些约束(不仅仅是数据库物理约束,还包括内部逻辑上的一些假设)
- 隔离性(Isolation):两个事务互相独立,不能互相干扰
- 持久性(Durability):事务执行成功之后结果可以持久化,永久存储下来(redo日志)
对于一致性,可能解释比较抽象,他的实际含义是:数据库的数据应满足完整性约束。拿转账业务来说,假设用户A和用户B一共有2000块钱,那么他们之间无论如何转账,总共的钱应该都是2000.
2. 事务并发访问引起的问题
- 更新丢失-mysql所有事务隔离级别在数据库层面均可避免
| 取款事务 | 存款事务 |
|---|---|
| 开始事务 | 开始事务 |
| 查询余额为100元 | 无 |
| 无 | 查询余额为100元 |
| 无 | 存入20,余额变为120元 |
| 无 | 提交事务 |
| 取出10元,余额改为90元 | 无 |
| 回滚事务,余额恢复为100元 | 更新丢失 |
- 脏读问题-一个事务读到另一个事务未提交的数据
- 不可重复读-事务A多次读取数据,未提交数据,此时事务B提交新的数据,导致A多次读取数据期间数据不一致,不满足隔离性
- 幻读-事务A受到另一个事务插入新的一行或者删除一行的影响,导致幻觉
不可重复读的重点是修改:
同样的条件的select, 你读取过的数据, 再次读取出来发现值不一样了
幻读的重点在于新增或者删除:
同样的条件的select, 第1次和第2次读出来的记录数不一样
具体可以自己设置不同的隔离级别进行演示。
3. 事务的隔离级别
- Read uncommitted:读到其他事务未commit的值
- Read committed:解决了脏读问题,但是会读到其他事务commit的值,读两次可能会读到两个值,所以又叫不可重复读
- Repeatable Read:解决了不可重复读问题,可重复读,别人commit对我没有影响,但是对于别的事务插入操作,可能会产生幻读
- Serializable:串行化,当发生两个事务同时提交,结果只可能有一个,相当于串行执行后的某个结果
级别越来越高,安全性也越来越高,但是但是性能越来越低。说明一下,出现幻读只是针对这种Repeatable Read隔离级别,但是InnoDB已经不存在幻读问题了,如何解决的呢?主要是用next-key锁来解决,下文会讲到。
4. 当前读和快照读
4.1 当前读
读取的都是当前数据的最新版本,并且在读的时候对其加锁,不允许其他事务进行修改操作。
select ... lock in share mode(共享锁)以及
select ... for update、update、delete、insert(排他锁)这些操作都是当前读。
为什么将 插入/更新/删除 操作,都归为当前读?可以看看下面这个 更新 操作,在数据库中的执行流程:

从图中,可以看到,一个Update操作的具体流程。当Update SQL被发给MySQL后,MySQL Server会根据where条件,发出current read 读取第一条满足条件的记录,然后InnoDB引擎会将第一条记录返回,并加锁 (current read)。
待MySQL Server收到这条加锁的记录之后,会再发起一个Update请求,更新这条记录。
一条记录操作完成,再读取下一条记录,直至没有满足条件的记录为止。因此,Update操作内部,就包含了一个当前读。
4.2 快照读
不加锁的非阻塞读,简单的select(前提是事务级别不是serializable,因为在serializable级别下都是串行读,普通的select也会退化为当前读即select ... lock in share mode)
快照读的实现是基于多版本并发控制(MVCC)实现,旨在提高性能。有可能读到的不是数据的最新版本。(创建快照的时机决定了读到的数据的版本,如果事务A先快照读,事务B修改,那么事务A再快照读就还是更新前的版本,事务A的当前读会读到最新的数据;而当事务B先更新,事务A再快照读,就会读到数据最新版本了)
4.3 MVCC
MVCC在MySQL的InnoDB中的实现 在InnoDB中,会在每行数据后添加两个额外的隐藏的值来实现MVCC,这两个值一个记录这行数据何时被创建,另外一个记录这行数据何时过期(或者被删除)。 在实际操作中,存储的并不是时间,而是事务的版本号,每开启一个新事务,事务的版本号就会递增。 在可重读Repeatable reads事务隔离级别下:
- SELECT时,读取创建版本号<=当前事务版本号,删除版本号为空或>当前事务版本号。
- INSERT时,保存当前事务版本号为行的创建版本号
- DELETE时,保存当前事务版本号为行的删除版本号
- UPDATE时,插入一条新纪录,保存当前事务版本号为行创建版本号,同时保存当前事务版本号到原来删除的行
通过MVCC,虽然每行记录都需要额外的存储空间,更多的行检查工作以及一些额外的维护工作,但可以减少锁的使用,大多数读操作都不用加锁,读数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行,也只锁住必要行。
说白了,就是乐观锁的一种实现。免去了加锁解锁的过程,对于读多写少的场景特别适用。
5. RC,RR级别下的InnoDB非阻塞读(快照读)如何实现
- 通过数据行里的
DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID这三个字段
DB_TRX_ID,最后一次修改本行事务的ID
DB_ROLL_PTR,即回滚指针,与undo日志配合
DB_ROW_ID,随着新行插入而单调递增的行号(innoDB中如果既没有主键索引也没有唯一索引的时候,就会自动生成一个隐藏主键,就是这个玩意)
这三个字段结合undo日志,这个日志里面记录的都是老版本的数据,这样,快照读就可以读出适合的一个版本的数据出来。在数据库中,日志是非常重要的东西,可以说其重要性是大于数据本身的,因为数据丢失可以通过日志找回来,但是日志丢失了,那么以后数据库出现崩溃等就麻烦了。
6. 日志
数据库数据存放的文件称为data file;日志文件称为log file;数据库数据是有缓存的,如果没有缓存,每次都写或者读物理disk,那性能就太低下了。数据库数据的缓存称为data buffer,日志(redo)缓存称为log buffer;既然数据库数据有缓存,就很难保证缓存数据(脏数据)与磁盘数据的一致性。比如某次数据库操作:
1 | update driver_info set driver_status = 2 where driver_id = 10001; |
更新driver_status字段的数据会存放在缓存中,等待存储引擎将driver_status刷新data_file,并返回给业务方更新成功。如果此时数据库宕机,缓存中的数据就丢失了,业务方却以为更新成功了,数据不一致,也没有持久化存储。
上面的问题就可以通过事务的ACID特性来保证。
1 | BEGIN trans; |
这样执行后,更新要么成功,要么失败。业务方的返回和数据库data file中的数据保持一致。要保证这样的特性这就不得不说存储引擎innodb的redo和undo日志。
6.1 undo是啥
undo日志用于存放数据修改被修改前的值,假设修改 tba 表中 id=2的行数据,把Name=‘B’ 修改为Name = ‘B2’ ,那么undo日志就会用来存放Name='B’的记录,如果这个修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性。
对数据的变更操作,主要来自 INSERT UPDATE DELETE,而UNDO LOG中分为两种类型,一种是 INSERT_UNDO(INSERT操作,事务提交后可以立即丢弃),记录插入的唯一键值;一种是 UPDATE_UNDO(包含UPDATE及DELETE操作),记录修改的唯一键值以及old column记录。
6.2 redo是啥
存储引擎也会为redo undo日志开辟内存缓存空间,log buffer。磁盘上的日志文件称为log file,是顺序追加的,性能非常高,注:磁盘的顺序写性能比内存的写性能差不了多少。
redo日志记录事务执行后的状态,用来恢复未写入data file的已成功事务更新的数据。例如某一事务的事务序号为T1,其对数据X进行修改,设X的原值是5,修改后的值为15,那么Undo日志为<T1, X, 5>,Redo日志为<T1, X, 15>。
梳理下事务执行的各个阶段:
- 写undo日志到log buffer;
- 执行事务,并写redo日志到log buffer;
- 如果innodb_flush_log_at_trx_commit=1,则将redo日志写到log file,并刷新落盘。
- 提交事务。
那redo日志是写进去了,但是数据呢?
在数据库的世界里,数据从来都不重要,日志才是最重要的,有了日志就有了一切。
因为data buffer中的数据会在合适的时间 由存储引擎写入到data file,如果在写入之前,数据库宕机了,根据落盘的redo日志,完全可以将事务更改的数据恢复。好了,看出日志的重要性了吧。先持久化日志的策略叫做Write Ahead Log,即预写日志。
6.3 Undo + Redo事务的简化过程
假设有A、B两个数据,值分别为1,2,开始一个事务,事务的操作内容为:把1修改为3,2修改为4,那么实际的记录如下(简化):
- 事务开始.
- 记录A=1到undo log buffer.
- 修改A=3.
- 记录A=3到redo log buffer.
- 记录B=2到undo log buffer.
- 修改B=4.
- 记录B=4到redo log buffer.
- 将redo log写入磁盘。
- 事务提交
我们可以看到,2,4,5,7,8都是新增操作,但是2,4,5,7都是缓冲到buffer区,只有8是磁盘IO操作。为了保证Redo Log有较好的IO性能,设计一般有以下特点:
- 尽量保持
Redo Log存储在一段连续的空间上。因此在系统第一次启动时就会将日志文件的空间完全分配。 以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。 - 批量写入日志。日志并不是直接写入文件,而是先写入
redo log buffer.当需要将日志刷新到磁盘时 (如事务提交),将许多日志一起写入磁盘. - 并发的事务共享
Redo Log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起,
以减少日志占用的空间。例如,Redo Log中的记录内容可能是这样的: 记录1: <trx1, insert …> 记录2: <trx2, update …> 记录3: <trx1, delete …> 记录4: <trx3, update …> 记录5: <trx2, insert …>
- 因为上一条的原因,当一个事务将
Redo Log写入磁盘时,也会将其他未提交的事务的日志写入磁盘 Redo Log上只进行顺序追加的操作,当一个事务需要回滚时,它的Redo Log记录也不会从Redo Log中删除掉。
6.4 回滚
前面说到未提交的事务和回滚了的事务也会记录Redo Log,因此在进行恢复时,这些事务要进行特殊的的处理。有2种不同的恢复策略:
- 进行恢复时,只重做已经提交了的事务。
- 进行恢复时,重做所有事务包括未提交的事务和回滚了的事务。然后通过
Undo Log回滚那些未提交的事务。
MySQL数据库InnoDB存储引擎使用了第二个策略。
InnoDB可重复读隔离级别下如何避免幻读
表象原因:快照读(非阻塞读)–伪MVCC
内在原因:next-key锁(行锁+gap锁)
6.5 next-key锁
在 RR 级别下,如果查询条件能使用上唯一索引,或者是一个唯一的查询条件,那么仅加行锁,如果是一个范围查询,那么就会给这个范围加上 gap 锁或者 next-key锁 (行锁+gap锁)。
那么gap锁啥时候出现呢?
使用主键索引或者唯一索引时:
- 如果where条件全部命中,则不会用Gap锁,只会加记录锁
- 如果where条件部分命中或者全不命中,则会加Gap锁
在走非唯一索引或者不走索引的当前读中,也会出现Gap锁。对于不走索引的情况,那么就会锁住整张表。
总结一下:只有对唯一索引+全部命中才不会加gap锁。
具体来个例子说明间隙锁如何工作。
7. 例子-走唯一索引
7.1 准备工作
有这样一个表test,其中name为主键,id为唯一键。
1 | CREATE TABLE `test` ( |
| name | id |
|---|---|
| f | 1 |
| h | 2 |
| b | 3 |
| a | 5 |
| c | 6 |
| d | 9 |
首先验证一下使用主键索引或者唯一索引时会怎么样。
7.2 第一种情况:唯一索引+命中所有数据
session1执行
1 | delete from test where id = 3; |
session2执行:
1 | insert into test(name,id) values("swg",4); |
此时由于id是唯一索引,并且是命中的,所以只是对这一行加排他锁,而没有加gap锁,所以session2是可以正常执行的,不能被阻塞。
7.3 第一种情况:唯一索引+不命中数据
session1执行
1 | delete from test where id = 7; |
session2执行:
1 | insert into test(name,id) values("swg",8); |
此时session2会阻塞住,证明id=7周围加了gap锁。gap锁的范围遵从左开右闭的原则,这里就是(6,7)以及(7,9)都会被锁住。加上record锁组成next-key锁,所以next-key锁的范围是(6,7]以及(7,9]这个范围。
7.4 第三种情况:唯一索引+不命中所有数据
session1执行
1 | select * from test where id in (5,7,9) lock in share mode; |
这里是一个范围,5和9都是存在的,但是7不存在,即部分数据不存在。
session2执行:
1 | insert into test(name,id) values("swg",4);<!--可以--> |
那么对于(5,9]的范围内就阻塞住了,那么部分命中就是部分加gap锁。
7.5 第四种情况:唯一索引+命中所有数据
session1执行
1 | select * from test where id in (5,6,9) lock in share mode; |
这里全部命中,那么
session2执行:
1 | insert into test(name,id) values("swg",7);<!--可以--> |
这个时候就不会加gap锁了。
8. 例子-不走唯一索引或者不走索引
下面来看看不走非唯一索引的当前读是什么情况。
此时表的数据为:
| name | id |
|---|---|
| h | 2 |
| c | 6 |
| b | 9 |
| d | 9 |
| f | 11 |
| a | 15 |
把id上的唯一索引换成了普通索引。
8.1 第五种情况:非唯一索引
session1执行
1 | delete from test where id = 9; |
session2执行:
1 | insert into test(name,id) values("swg",9); |
此时session2是会被block住的。gap的范围是(6,9]以及(9,11].
1 | insert into test(name,id) values("swg",5);<!--可以--> |
上面的原理都是一样的,即只要是6和11之间的数,不包含临界值的时候,无论插入什么数据,都是会阻塞的。
但是关于临界值6和11,这里就比较特殊了,因为需要加上主键的值才能进行精准的判断。
1 | insert into test(name,id) values("bb",6);<!--可以--> |
这是什么原因呢?
我们将数据画成图:
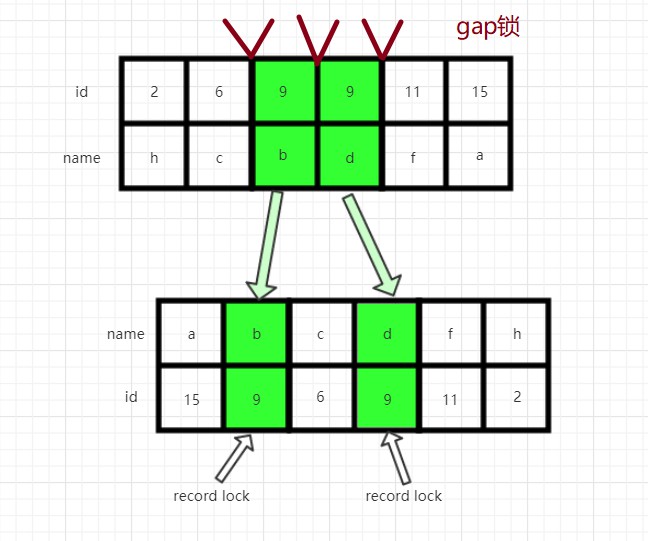
这里的gap区间可能是(负无穷,2],(2,6],(6,9],(9,11],(11,15],(15,正无穷)
我们可以看到,id为6的行,对应的name为c(不要忘记name是主键,主键按照顺序排序),那么主键中就是按照字母表的顺序进行排列的(ASCII码),如果插入的name小于c,那么就不在gap的范围内(c,),就可以插入,但是dd在gap的范围内,所以就会阻塞住。
8.2 第五种情况:不走索引
这个时候,所有的间隙都会加上间隙锁,那么就是锁表了。