
Redis其他的功能介绍
本文为redis学习笔记的第三篇文章,本文主要介绍redis一些其他的功能。遇到某些场景的时候可以想到redis是不是可以实现。
一、慢查询日志
1.1 什么是慢查询日志
慢查询日志帮助开发和运维人员定位系统存在的慢操作。慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(慢查询ID,发生时间戳,耗时,命令的详细信息)记录下来。
1.2 redis一条命令简单的生命周期
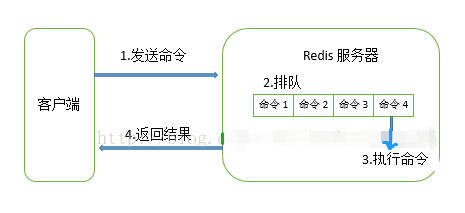
慢查询只会出现在【3.执行命令】这个阶段,即慢查询只记录命令执行时间,并不包括命令排队时间和网络传输时间。
1.3 慢查询配置参数
慢查询的预设阀值
slowlog-log-slower-than
slowlog-log-slower-than参数就是预设阀值,单位是微秒,默认值是10000,如果一条命令的执行时间超过10000微妙(10毫秒),那么它将被记录在慢查询日志中。- 如果
slowlog-log-slower-than的值是0,则会记录所有命令。 - 如果
slowlog-log-slower-than的值小于0,则任何命令都不会记录日志。 redis的操作一般是微妙级,slowlog-log-slower-than不要设置太大,一般设置为1毫秒。支持动态设置。
慢查询日志的长度
slowlog-max-len
slowlog-max-len只是说明了慢查询日志最多存储多少条。Redis使用一个列表来存储慢查询日志,showlog-max-len就是列表的最大长度。- 当慢查询日志已经到达列表的最大长度时,又有慢查询日志要进入列表,则最早插入列表的日志将会被移出列表,新日志被插入列表的末尾。
- 默认是128,但是
slowlog-max-len不要设置太小,可以设置为1000以上.
慢查询日志是一个先进先出队列,慢查询较多的情况下,可能会丢失部分慢查询命令,可以定期执行slow get命令将慢查询日志持久化到其他存储中。然后制作可视化界面查询。
二、pipeline
2.1 为什么会出现Pipeline
用普通的get和set,如果同时需要执行大量的命令,那就是等待上一条命令应答后再执行,这中间不仅仅多了RTT(Round Time Trip),而且还频繁的调用系统IO,发送网络请求。
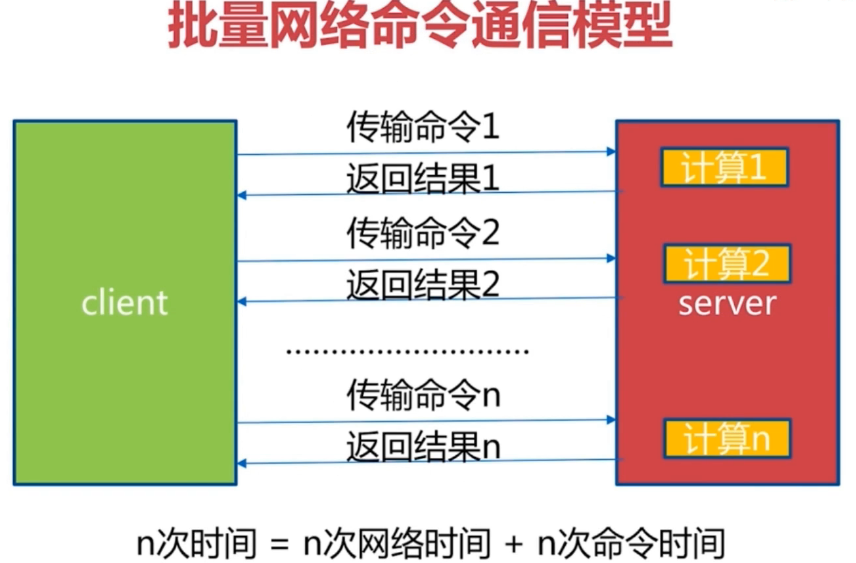
对于多条命令不是有mget和mset吗?确实对于一批的get和set可以用mget和mset,但是它的问题在于如果我们需要同时传输get和hget呢?此时pipeline(流水线)就出现了。
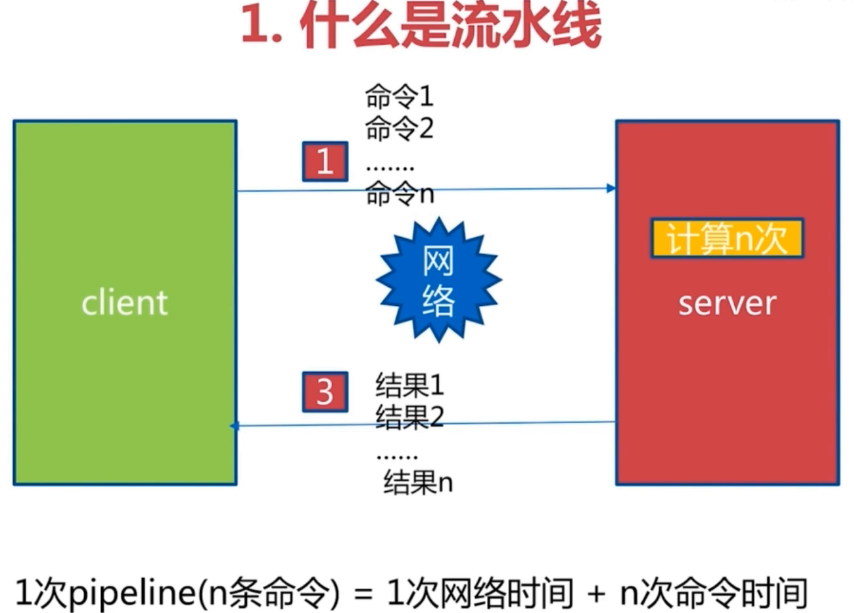
所以流水线解决的问题是N条命令网络通信的减少。

为什么说网络耗费时间大呢?这里给出一个极端的例子。
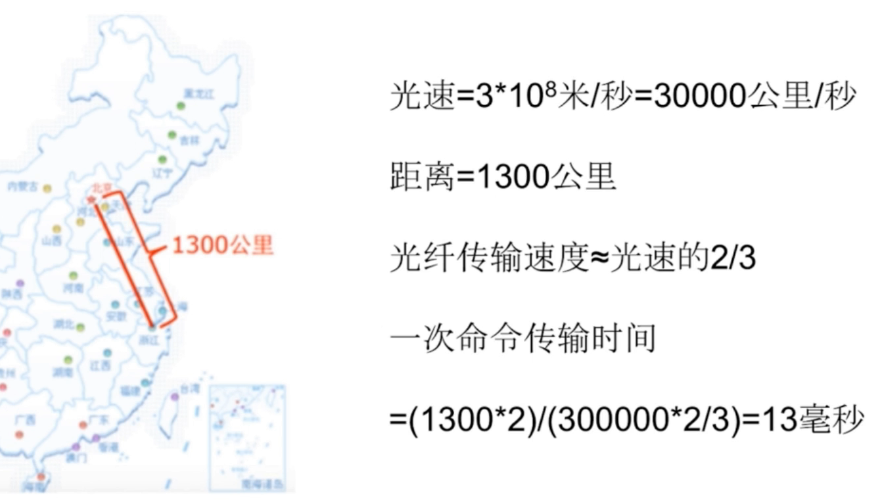
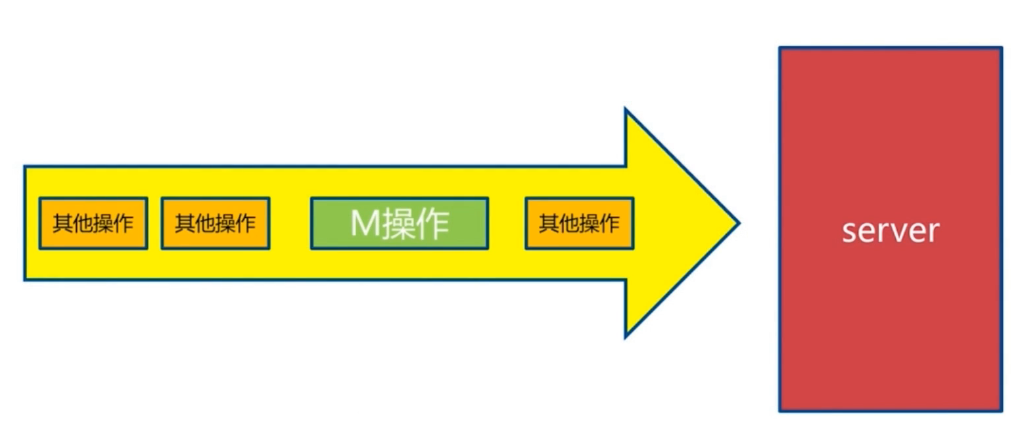
pipeline与原生M操作的对比。
- 原生M操作是一个原子操作。
pipeline非原子命令。
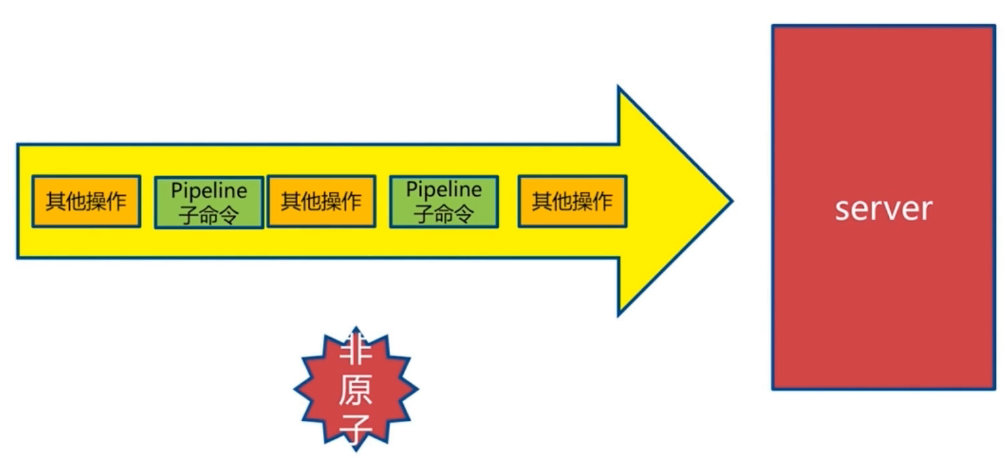
当某个命令的执行需要依赖前一个命令的返回结果时,无法使用pipeline。
1 | mset a “a1” b “b” c “c1” |
mget和mset命令也是为了减少网络连接和传输时间所设置的,其本质和pipeline的应用区别不大,但是在特定场景下只能用pipeline实现,例如:
1 | get a |
pipeline适合执行这种连续,且无相关性的命令。
2.2 一个demo
搭建一个quickstart的maven工程。过程略。
引入依赖:
1 | <dependency> |
直接再单元测试中进行测试:普通的直接hset 10000条数据:
1 |
|
运行结果:
一共耗时: 1526ms
但是用pipeline后:
1 |
|
运行结果:使用
pipeline一共耗时: 139ms
可以预见,对于更多的传输次数,pipeline的优势将越来越明显。但是pipeline每次只能作用在一个redis节点上。
三、发布订阅
3.1 角色
发布者----频道----订阅者
3.2 模型
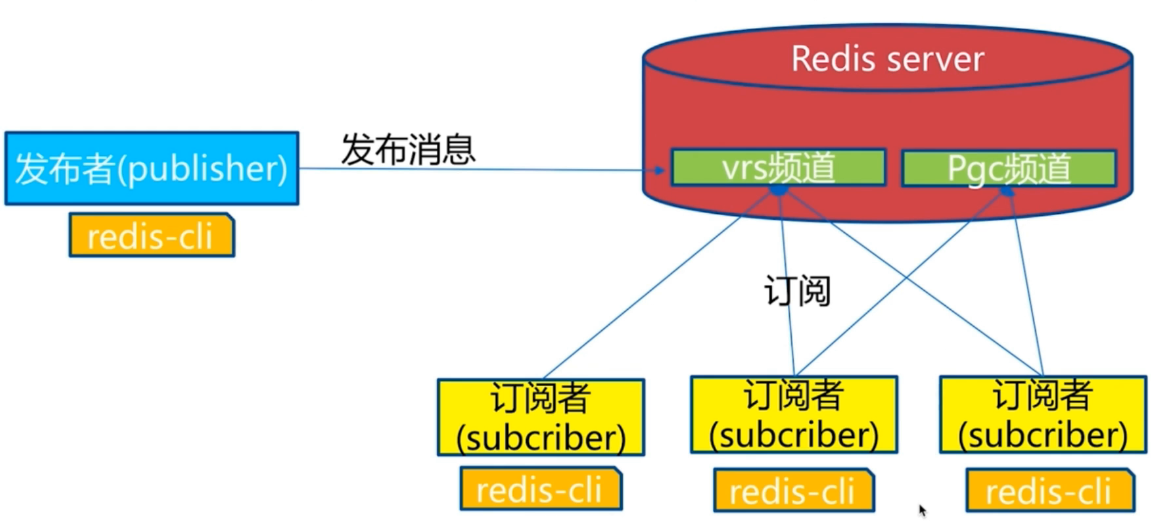
注意,新订阅的,是不能收到之前的消息的。
- 订阅者1:subscribe mytopic
- 订阅者2:subscribe mytopic
- 订阅者3:subscribe mytopic
- 发布者:publish mytopic “hello”
缺点是不能保证消息可达,所以还是用专业的消息队列传达比较保障。
与发布订阅模型很类似的是消息队列模型。
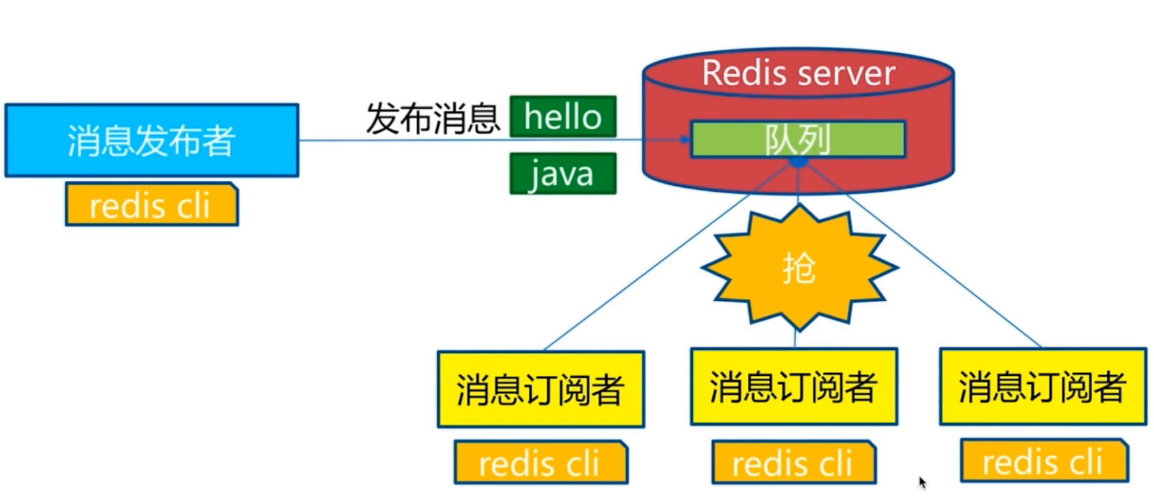
只有一个是可以收到消息的。
四、bitMap
4.1 位图是什么
就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省储存空间。
Bitmap不是一个确切的数据类型,而是基于String类型定义的一系列面向位操作的方法。因为String是二进制安全的并且它们的最大长度是512MB,
所以String类型很合适去作为一个2^32长度的位数组。
比如我们执行 set hello big
那么这个big其实是这个形态:

执行getbit hello 0 得到0; 执行getbit hello 1 得到1
setbit hello 7 1,那么再get hello 将得到cig
4.2 位图有什么用呢?
位图除了getbit和setbit之外,还有bitcount key [start end],就是获取执行范围内的1的个数。
bitop作用是做多个Bitmap的and,or,not,xor操作。
以一个场景为例:日活跃用户
每次用户登录时会执行一次redis.setbit(daily_active_users, user_id, 1)
因为日活跃用户每天都变化,所以需要每天创建一个新的bitmap。我们简单地把日期(年月日)添加到key后面,以后就可以根据年月日这个key找到某天活跃用户。实现了这个功能。
第二个场景:用户签到情况
将那天所代表的网站的上线日作为offset参数, 比如,如果今天是网站上线的第100天,而用户$uid=10001在今天阅览过网站, 那么执行命令SETBIT peter 100 1. 如果明天$uid=10001也继续阅览网站,那么执行命令SETBIT peter 101 1 ,以此类推.
仔细想想,用位图,一天签到一次只要占一个bit,8天才占一个字节。那么一年这个用户签到占的数据是365/8=45.625个字节.如果不用位图实现,保存一条记录将远远大于一个比特吧,那么当用户量很大的时候,差距将会特别大。
五、hyperLogLog
基于HyperLogLog算法:极小空间完成独立数量统计。本质还是字符串。
pfadd key element [element...]:向hyperloglog添加元素pfcount key [key...]:计算hyperloglog的独立总数pfmerge destkey sourcekey [sourcekey...]:合并多个hyperloglog
api例子
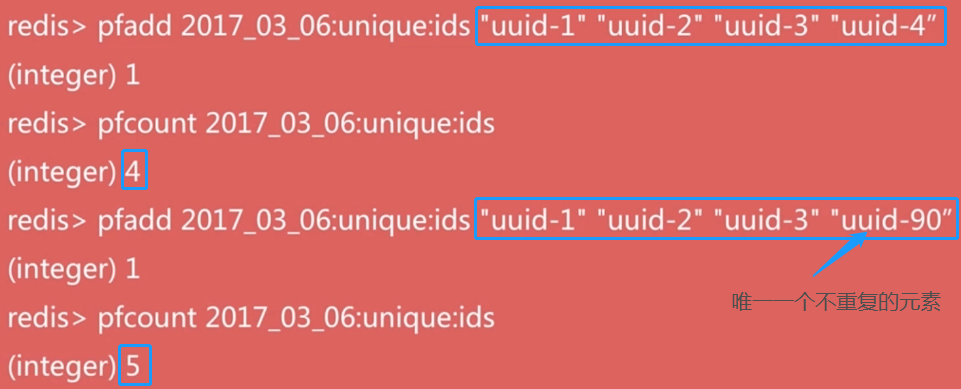
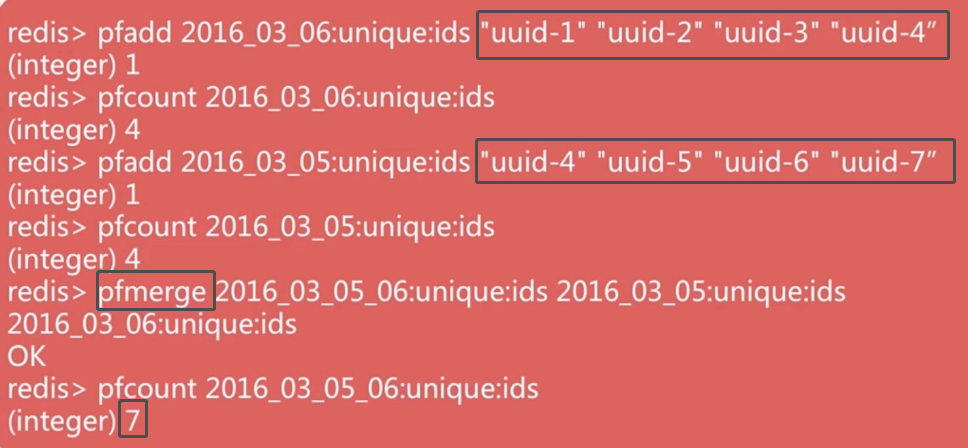
为什么要用hyperLogLog呢
我们上面例子可以看到,他的功能类似于去重,统计出所有不一样元素的个数。
他的优点是:占用内存极小。

缺点也有:
- 他可能会出错,错误率为0.81%,看你是否能够容忍错误了
- 不能拿到单条数据
六、geo
存储经纬度、计算两地距离、范围计算等。
提到LBS(Location Based Service),基于位置的服务。我立即想起Mongodb的GEO实现地理坐标查询等功能,具体介绍为地理位置附近查询的GEOHASH解决方案。
mongodb最大的特点是灵活,因为其数据是以json的格式存储,所以字段随时可以增加或减少;Redis的特点是快,适合单一的,简单的,大量数据的存储;HBase我没有做深入研究,它的特点是大,适合做离线缓存。在处理社交这种关系复杂的数据存储时,依然还是需要用mysql这种关系型数据库,nosql并不能完全替代。
七、总结
- 首先是慢查询日志,可以定时地持久化,并且用一个可视化页面进行监测。
- pipeline解决的是对没有相互依赖的操作的批量执行,减少网络传输和IO时间。但是呢,需要注意一般只能往一个节点放数据,面对集群的时候,就需要采取一些策略了。mset、mget,目前只支持具有相同slot值的key执行批量操作。后文再讲。
- 可以实现发布订阅模型以及消息队列,但是消息是无状态的,不能保证消息一定送达,所以需要用专业的MQ来实现。
- 位图,可以实现极小的空间完成对大量用户信息的统计。
- 地理坐标服务