
Redis为什么快
本文为redis学习笔记的第四篇文章,本文主要攻克面试题-Redis为什么这么快。这就涉及Redis的线程模型啦。
完全基于内存
Redis是纯内存数据库,相对于读写磁盘,读写内存的速度就不是几倍几十倍了,一般,hash查找可以达到每秒百万次的数量级。
多路复用IO
“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗)。
Redis为什么是单线程的?
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
为什么 Redis 中要使用 I/O 多路复用这种技术呢?
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
假设你是一个老师,让30个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。这中间如果有一个学生卡主,全班都会被耽误。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。
第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。。。
第三种就是IO复用模型,
Linux下的select、poll和epoll就是干这个的。将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。
所以,I/O多路复用的本质是通过一种机制(系统内核缓冲I/O数据),让单个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。
这里还涉及一个名词:fd文件描述符。
Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件,所有执行I/O操作的系统调用都会通过文件描述符。
redis的线程模型?
Redis 服务采用 Reactor 的方式来实现文件事件处理器。
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。
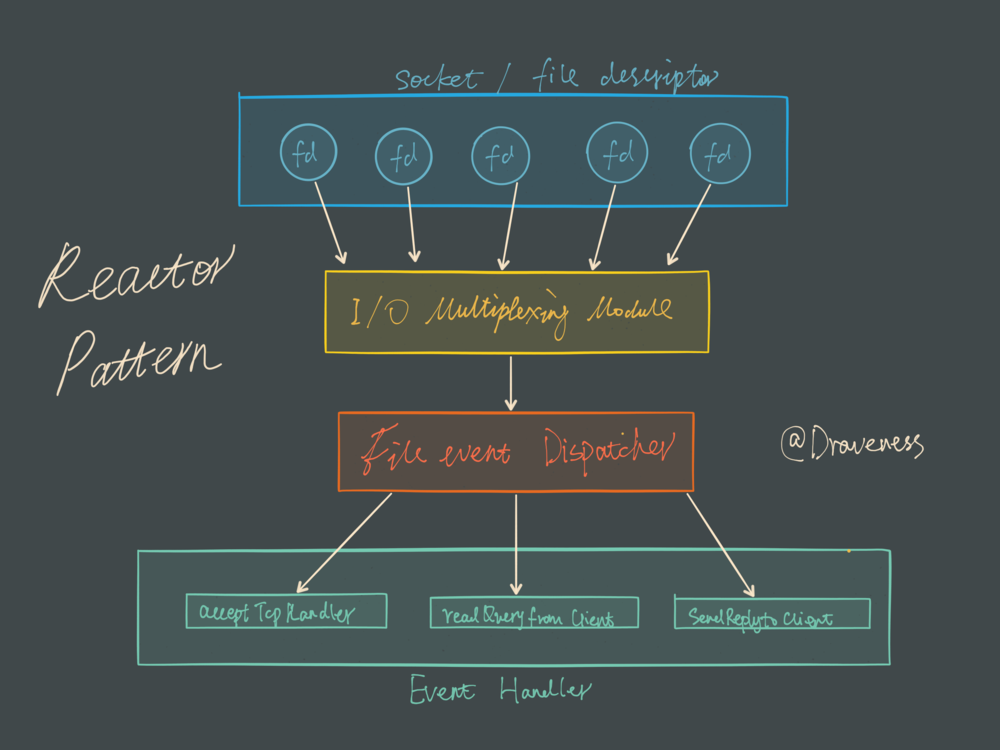
上面简单理解就是:多个网络连接并发读写redis的时候,先将对应的fd注册到epoll上,I/O多路复用模块会监听这些网络请求的情况,一旦有一个网络连接产生了accept、read、write 和 close 文件事件,I/O多路复用模块就会向文件事件分派器传送那些产生了事件的网络连接。

当然了,上面的文件事件可能会并发产生,这时的策略是,将所有产生事件的套接字(对应上面的网络连接)都入队到一个队列里面, 然后通过这个队列, 以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字: 当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕), I/O 多路复用程序才会继续向文件事件分派器传送下一个套接字。再看看下图,与上图使一样的:
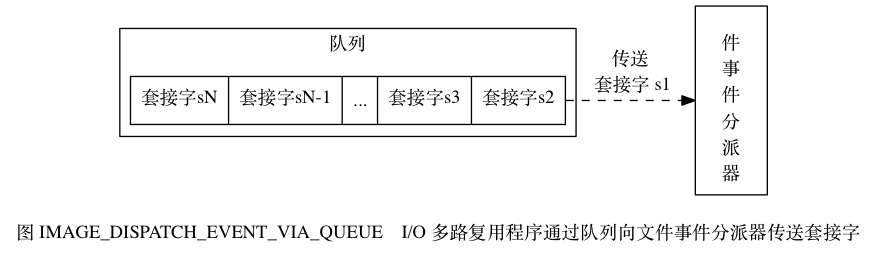
文件事件分派器接收 I/O 多路复用程序传来的套接字, 并根据套接字产生的事件的类型, 调用相应的事件处理器。
服务器会为执行不同任务的套接字关联不同的事件处理器, 这些处理器是一个个函数, 它们定义了某个事件发生时, 服务器应该执行的动作。
整个模块使 Redis 能以单进程运行的同时服务成千上万个文件描述符,避免了由于多进程应用的引入导致代码实现复杂度的提升,减少了出错的可能性,单线程还减少线程切换和调度,实现更加简单
最后总结一下,为什么redis比较快大概思路通俗的说就是:Redis是纯内存数据库,读取快,瓶颈在于IO上,如果使用阻塞式IO,因为是单线程的缘故,就会停止等待。所以采用IO多路复用监听文件描述符的状态,将对redis的开关读写换成事件,加入队列进行相应的事件处理,吞吐量比较大。
IO复用模型的选择
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口;
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:
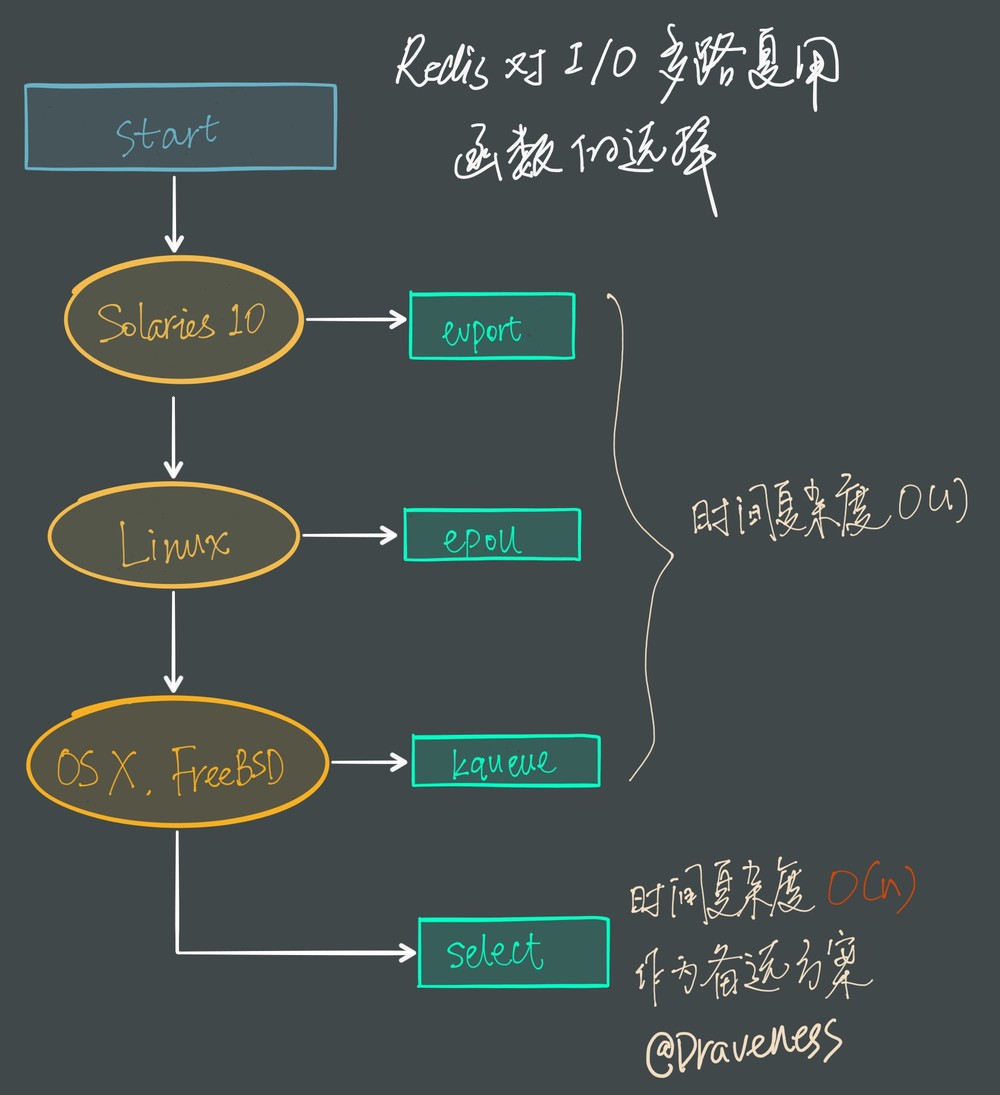
Redis 会优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 O(n),并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
reids在linux下的安装
Redis对于Linux是官方支持的,安装起来也非常地简单,直接编译源码然后进行安装即可。
这里以centos为例,大概说一下步骤:
下载redis编译工具:
yum install gcc和yum install g++
解压
redis.tar.gz文件,进去之后进行编译:make
然后安装:
make install PREFIX=/usr/local/redis
安装成功之后进入
/usr/local/redis/bin下启动redis
./redis-server