
Redis主从复制
本文为redis学习笔记的第六篇文章。介绍redis主从复制功能实现原理。作为高可用的基础,了解一下其中的门道是有必要的。
1.单机有什么问题
- 机器故障
- 容量瓶颈
- QPS瓶颈
2. 主从复制的作用
- 数据副本
- 扩展读性能,
slave专门用来读 - 一个
master可以有多个slave,一个salve只能有一个master
3. 两种实现方式
- 方式一:
slaveof命令slaveof masterIp masterPortslaveof no one(不会清除原来同步的数据,而是新的数据不会再同步给他)
- 方式二:配置
- 修改某一行的配置:
slaveof ip port - 从节点只做读操作:
slave-read-only yes
- 修改某一行的配置:
- 对比
- 命令的优点:不需要重启
- 命令的缺点:不便于管理
- 配置的优点:统一配置
- 配置的缺点:需要重启
一个场景,假如6380是6379的一个从节点,然后将6380执行salveof no one,然后插入一些新的数据;再重新变成6379的从节点,那么里面的新数据会被清除掉。
- 查看run_id
redis-cli -p 6379 info server | grep run
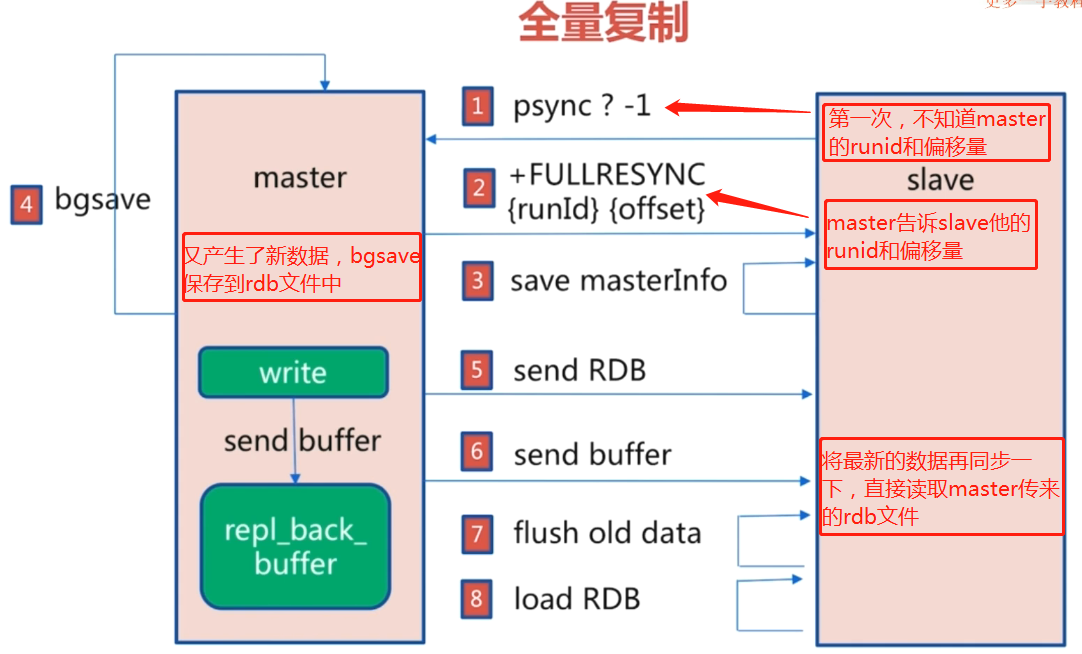
4. 全量复制
- 全量复制开销
- bgsave时间
- rdb网络传输时间
- 从节点清空数据的时间
- 从节点加载RDB的时间
- 可能的AOF重写时间
- 存在的问题
- 时间开销比较大
- 如果
master和slave之间网络扰动甚至断开,那么master此间更新的数据对于slave是不知道的,最简单的方法就是再进行一次全量复制,但是显然,消耗太大了。
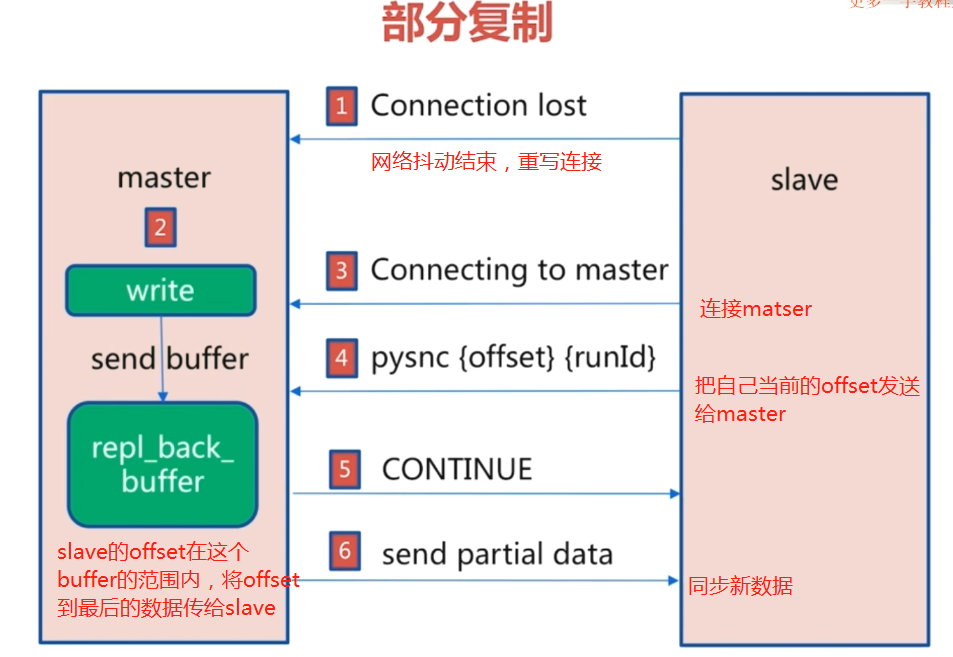
5. 部分复制
6. 开发与运维的问题
- 读写分离
master只做写操作,slave来做读操作,来分摊流量。但是会有一些问题:
复制数据延迟
读到过期数据
从节点故障
- 主从配置不一致
例如
maxmemory不一致:丢失数据数据结构优化参数:内存不一致
- 规避全量复制
第一次全量复制:不可避免—小主节点(
maxmemroy不要太大)或者在低峰时进行操作节点
run_id不匹配(主节点重启,那么master的run_id会发生变化,slave发现其run_id变化,会进行全量复制);我们可以用故障转移,例如哨兵或集群来避免全量复制。复制积压缓冲区不足(网络中断,部分复制无法满足),可以增大复制缓冲区配置
size,网络增强
- 规避复制风暴
概念:主节点宕机造成大量的全量复制
单主节点复制风暴:主节点重启,多从节点复制;解决:更换复制拓扑
单机器复制风暴:机器宕机后(该机器全是
Mater),大量全量复制。解决:master分散多机器。
说到底,还是需要有一种高可用的实现方式,在master出现故障之后,如何自动实现从slave晋升为master继续使用.而不是一直死守着原来老的master不放,因为老的master啥时候恢复不知道,恢复了可能会造成复制风暴,既然从节点本来是一直与master节点保持尽量的同步的,那么为什么不将数据最新的从节点升级为主节点呢?下一章继续来分析。