
Redis-Cluster理论详解
本文为redis学习笔记的第八篇文章。上一篇我们学习了redis sentinel,知道了它是redis高可用的一种实现方案。但是面对要求很高的场景,一台master是一定不能解决问题的,redis 3.0给我们带来了服务端集群方案,解决了这个问题。
1. 数据分区
集群,那么就会涉及到数据是如何分片的。有两种方式:顺序分区和哈希分区

两者对比:

直接hash取模进行数据分片时,当节点增加,会有很多数据命中不了,需要重新映射。如果大多数数据在增加或者减少节点之后进行迁移的话,对于性能影响是很大的,因为数据迁移,那么缓存中现在是无法命中的,必须去数据库取,是灾难性的行为。
早期的做法就是这样,在客户端hash取余节点个数来进行数据分片。如果非要这样,采取翻倍扩容会稍微好一点,迁移数据量会小一点。不过无论如何,这种方式在大数据量情况下是不可行的。
2. 一致性hash算法
对于上面提到的直接hash取余的方式,会导致大量数据的迁移。那么有没有一种方式,在增加或减少节点时,只有少部分数据迁移呢?
针对一致性hash算法,已经在简明理解一致性hash算法中详细说明了,不再赘述。
对于redis 3.0之前,客户端可以用这种方式来实现数据分片。在redis 3.0之后,就不需要客户端来实现分片算法了,而是直接给我们提供了服务端集群方案redis cluster.
3. 虚拟槽
redis cluster引入槽的概念,一定要与一致性hash的槽区分!这里每一个槽映射一个数据集。
CRC16(key) & 16383
这里计算结果发送给redis cluster任意一个redis节点,这个redis节点发现他是属于自己管辖范围的,那就将它放进去;不属于他的槽范围的话,由于redis之间是相互通信的,这个节点是知道其他redis节点的槽的信息,那么会告诉他去那个redis节点去看看。
那么就实现了服务端对于槽、节点、数据的管理。
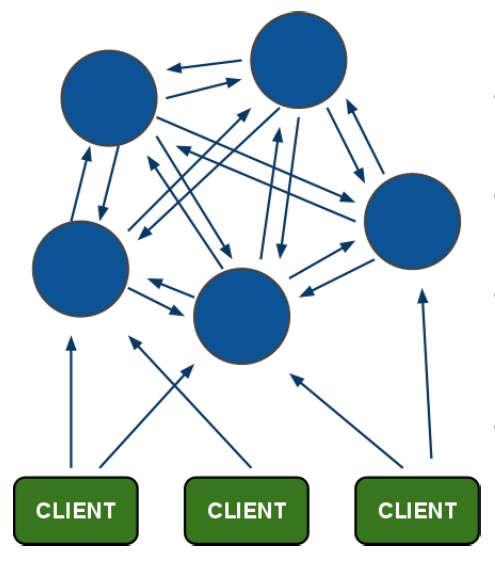
当master节点增加时,即扩容时,对于以上两种方案,都会出现数据迁移,那么只能作为缓存场景使用。但是redis cluster,由于每个节点维护的槽的范围是固定的,当有新加入的节点时,是不会干扰到其他节点的槽的,必须是以前的节点将使用槽的权利分配给你,并且将数据分配给你,这样,新的节点才会真正拥有这些槽和数据。这种实现还处于半自动状态,需要人工介入。-----主要的思想是:槽到集群节点的映射关系要改变,不变的是键到槽的映射关系.
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。
4. 某个Master又怎么知道某个槽自己是不是拥有呢?
Master节点维护着一个16384/8字节的位序列,Master节点用bit来标识对于某个槽自己是否拥有。比如对于编号为1的槽,Master只要判断序列的第二位(索引从0开始)是不是为1即可。

如上面的序列,表示当前Master拥有编号为1,134的槽。集群同时还维护着槽到集群节点的映射,是由长度为16384类型为节点的数组实现的,槽编号为数组的下标,数组内容为集群节点,这样就可以很快地通过槽编号找到负责这个槽的节点。位序列这个结构很精巧,即不浪费存储空间,操作起来又很便捷。
具体参照:http://blog.jobbole.com/103258/ ,还提到了slot迁移的一些细节。
5. redis节点之间如何通信的?
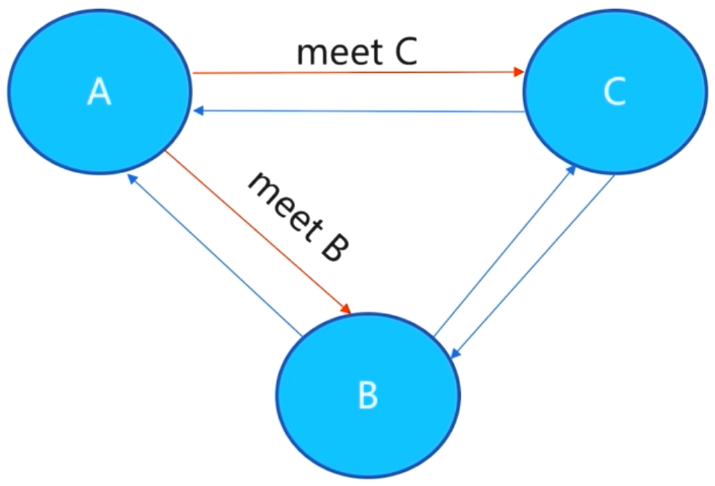
gossip协议:节点之间彼此不断通信交换信息,一段时间后所有节点都会知道集群完整的信息。- 节点与节点之间通过二进制协议进行通信。
- 客户端和集群节点之间通信和通常一样,通过文本协议进行。
- 集群节点不会代理查询。
6. 集群伸缩
这里6385为新加入的节点,一开始是没有槽的,所以进行slot的迁移。
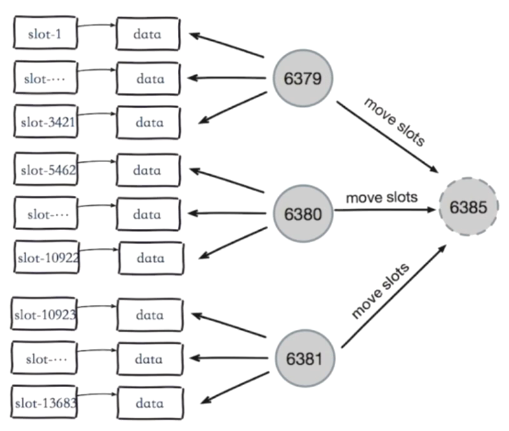
集群伸缩:槽和数据在节点之间的移动。
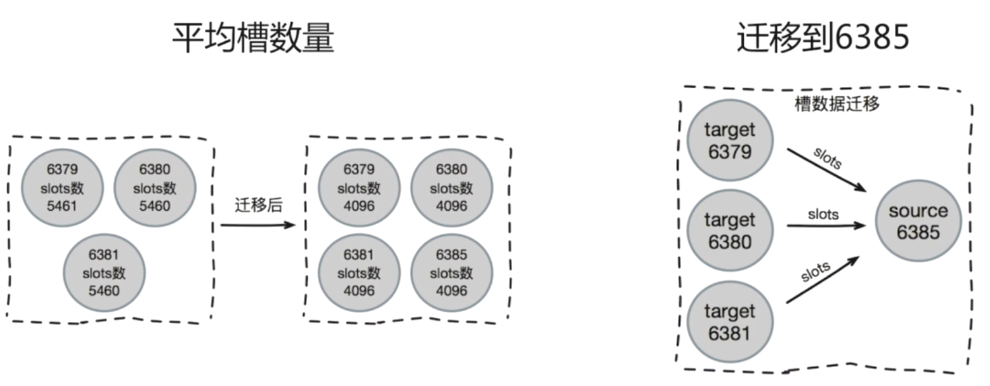
迁移数据的流程图:
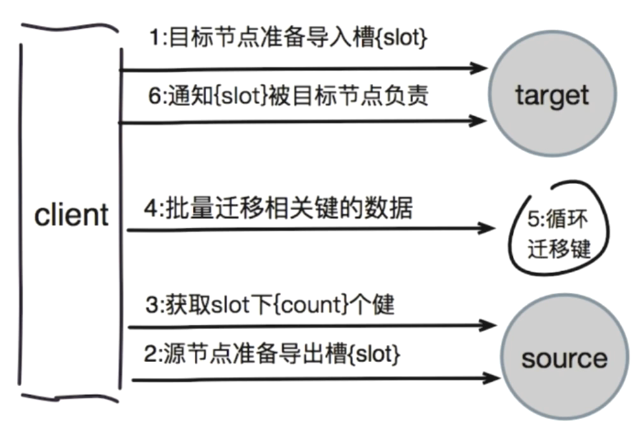
迁移key可以用pipeline进行批量的迁移。
对于扩容,原理已经很清晰了,至于具体操作,网上很多。至于缩容,也是先手动完成数据迁移,再关闭redis。
7. 客户端路由
7.1 moved重定向
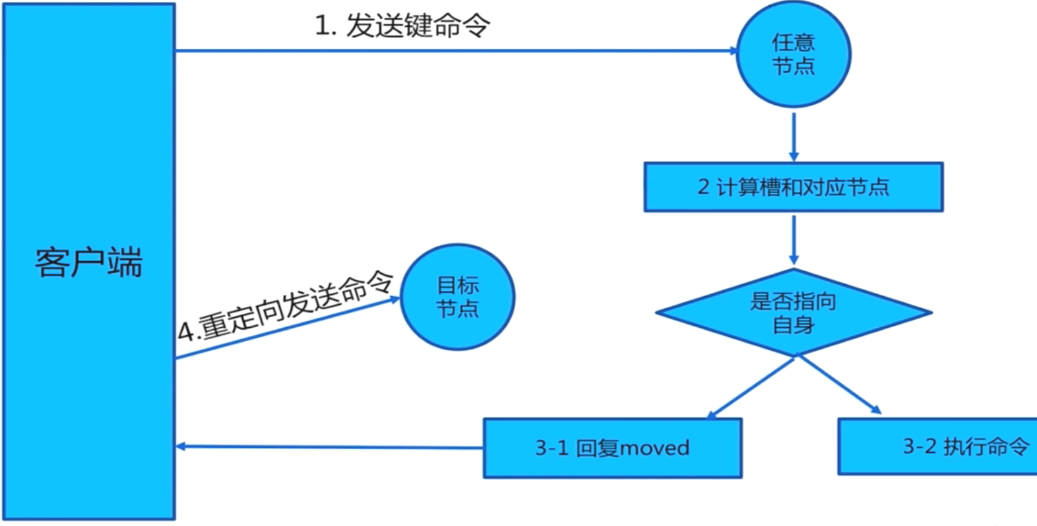
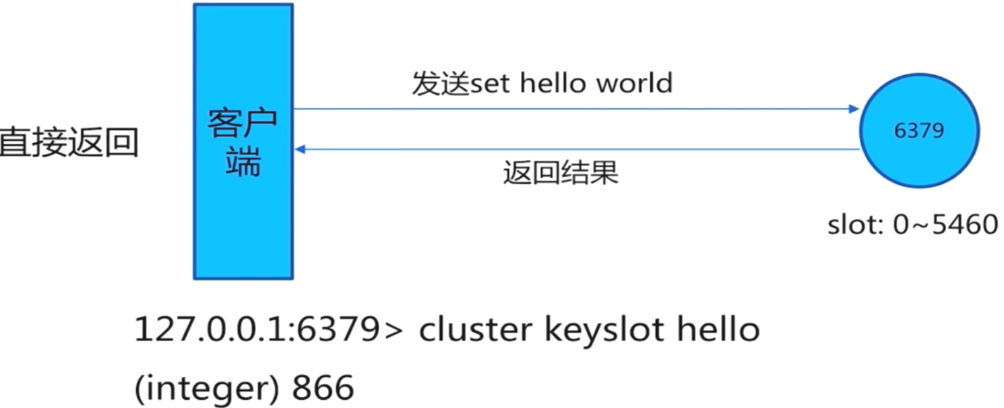
其中,槽直接命中的话,就直接返回槽编号:
槽不命中,返回带提示信息的异常,客户端需要重新发送一条命令:

对于命令行的实验,用redis-cli去连接集群:
redis -c -p 7000:加上-c,表示使用集群模式,帮助我们在第一次不命中的情况下自动跳转到对应的节点上:

如果不加-c的话,会返回moved异常,不会自动跳转:

7.2 ask重定向
在扩容缩容的时候,由于需要遍历这个节点上的所有的key然后进行迁移,是比较慢的,对客户端是一个挑战。因为假设一个场景,客户端访问某个key,节点告诉客户端这个key在源节点,当我们再去源节点访问的时候,却发现key已经迁移到目标节点。

7.3 moved重定向和ask重定向对比
- 两者都是客户端的重定向
- moved:槽已经确定转移
- ask:槽还在迁移中
问题:如果节点众多,那么让客户端随机访问节点,那么直接命中的概率只有百分之一,还有就是发生ask异常时(即节点正在迁移时)客户端如何还能高效运转?
总结一句话就是redis cluster的客户端的实现会更复杂。
8. smart客户端
8.1 追求目标
追求性能,不会使用代理模式,而是直连对应节点。需要对moved异常和ask异常做兼容。也就是说,需要有一个这个语言对应的客户端来高效实现查找等操作。
8.2 smart原理
- 从集群中选一个可运行节点,使用
cluster slots初始化槽和节点映射 - 将
slot与node节点的结果映射到本地,为每个节点创建JedisPool - 准备执行命令
第一步中将slot与node节点的对应关系放在了map中,形成一个映射关系;key是通过CRC16算法再取余得到slot,所以key与slot的映射关系也是确定的。我们就可以直接发送命令。只要后面集群没有发生数据迁移,那么就会连接成功。但是如果在连接的时候出现了连接出错,说明这个key已经迁移到其他的node上了。如果发现key不停地迁移,超过5次就报错。
在发生moved异常的时候,则需要刷新缓存,即一开始维护的map。
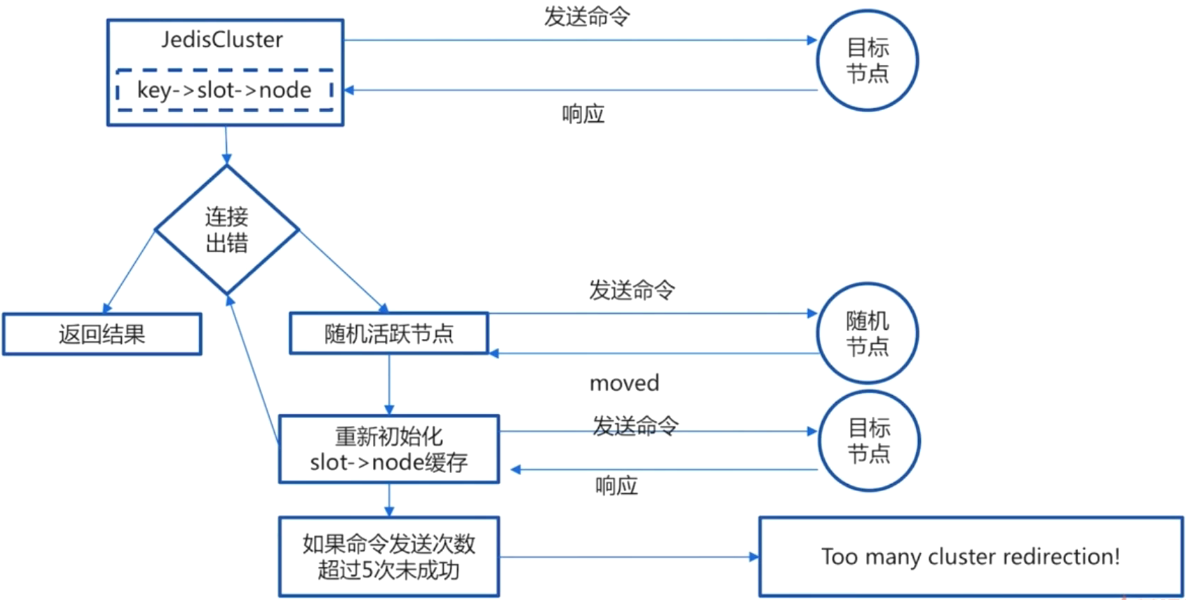
有一个情况比较全的图:
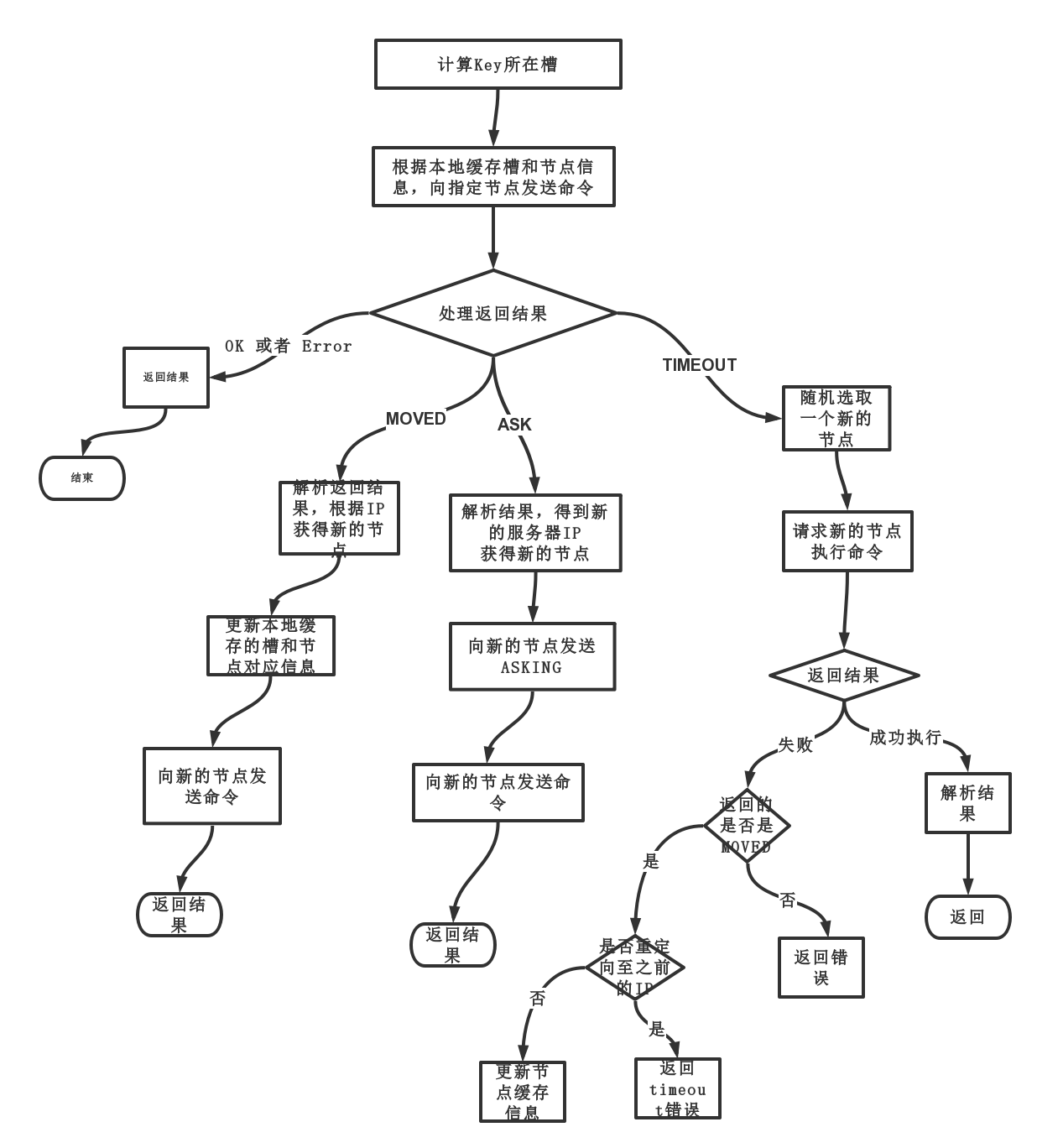
java redis cluster客户端:jedisCluster基本使用–伪代码
jedisCluster内部已经封装好池的借还操作等。
先写一个JedisClusterFactory:
1 | import redis.clients.jedis.HostAndPort; |
hostPortList 放入spring bean中,spring自动完成注入。
8.3 多节点命令实现
有的时候我们想操作所有节点的数据。如何实现呢?

8.4 批量操作
mget,mset必须在一个槽。这个条件比较苛刻,一般是不能保证的,那么如何实现批量的操作呢?
Redis Cluster的行为和Redis的单节点不同,甚至和一个Sentinel监控的主从模式也不一样。主要原因是集群自动分片,将一个key映射到16384个槽中的一个,这些槽分布在多个节点上。因此操作多个key的命令必须保证所有的key都映射到同一个槽上,避免跨槽执行错误。更进一步说,今后一个单独的集群节点,只服务于一组专用的keys,请求一个命令到一个Server,只能得到该Server上拥有keys的对应结果。一个非常简单的例子是执行KEYS命令,当发布该命令到集群环境中的某个节时,只能得到该节点上拥有的keys,而不是集群中所有的keys。所以要得到集群中所有的keys,必须从集群的所有主节点上获取所有的keys。
对于分散在redis集群中不同节点的数据,我们如何比较高效地批量获取数据呢????
- 串行mget–原始方案,整一个for循环
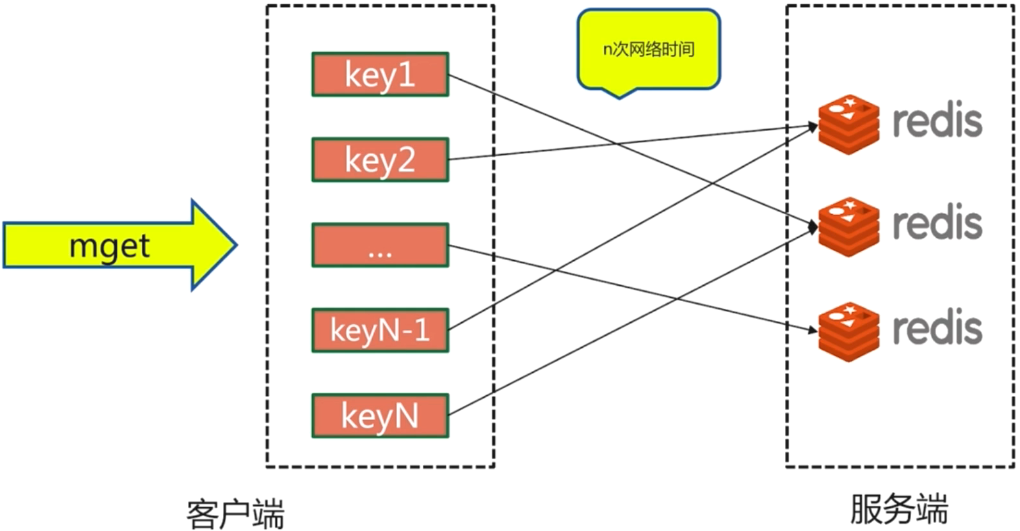
- 串行IO
对key进行RCR16和取余操作得到slot,将slots按照节点进行分批传送:

- 并行IO
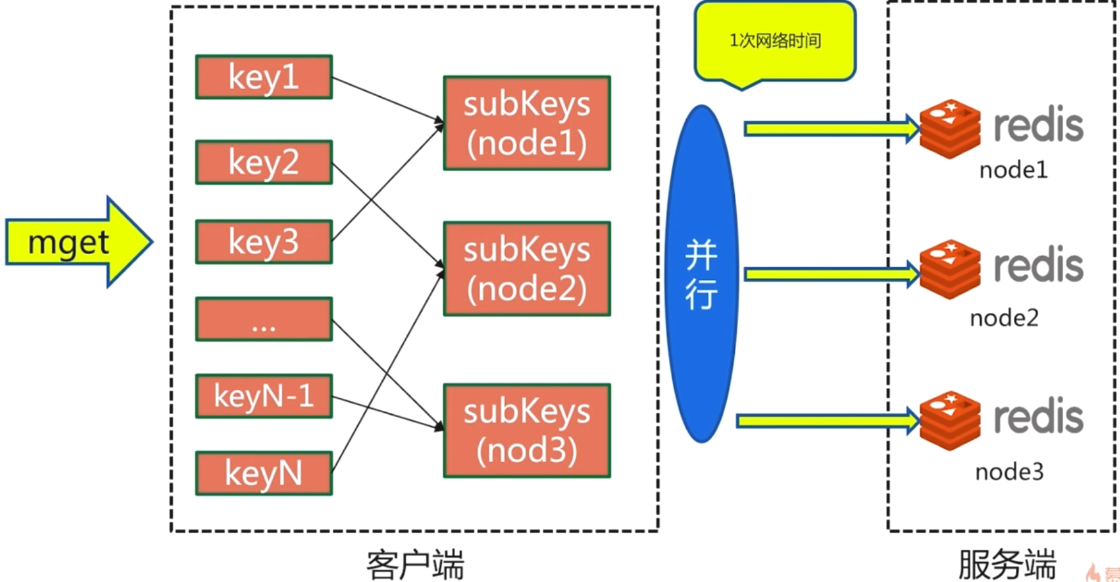
- hash_tag
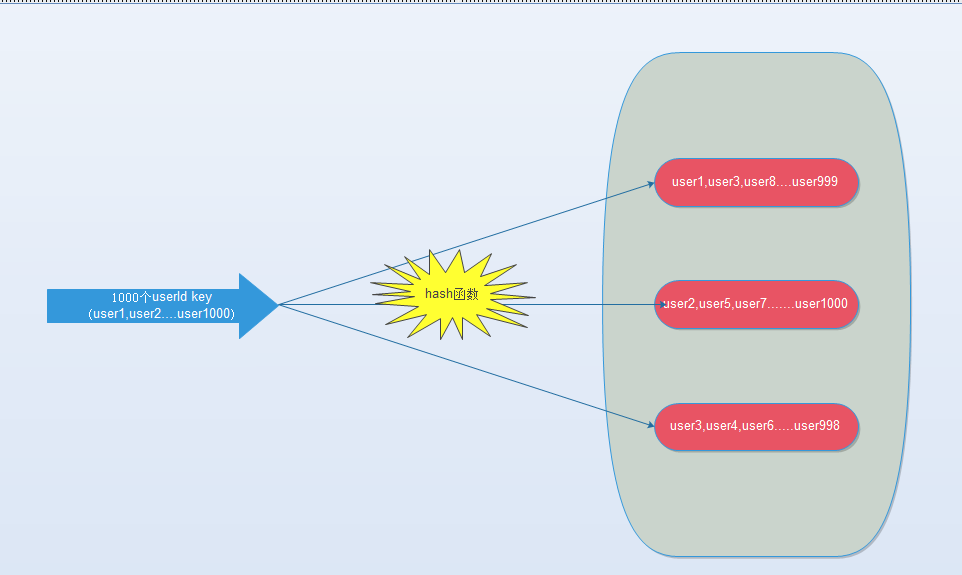
不做任何改变的话,hash之后就比较均匀地散在每个节点上:
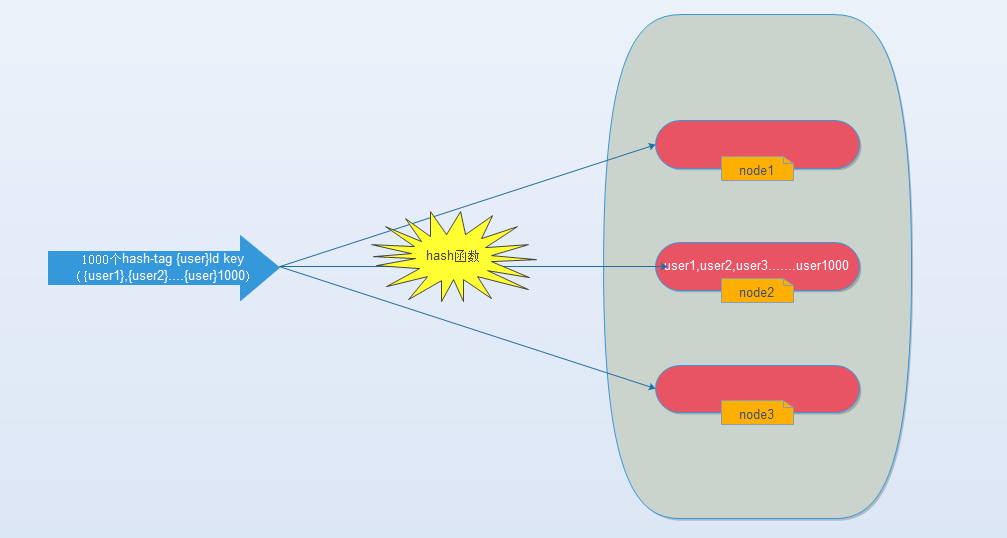
那么我们能不能像使用单机redis一样,一次IO将所有的key取出来呢?hash-tag提供了这样的功能,如果将上述的key改为如下,也就是用大括号括起来相同的内容,那么这些key就会到指定的一个节点上。
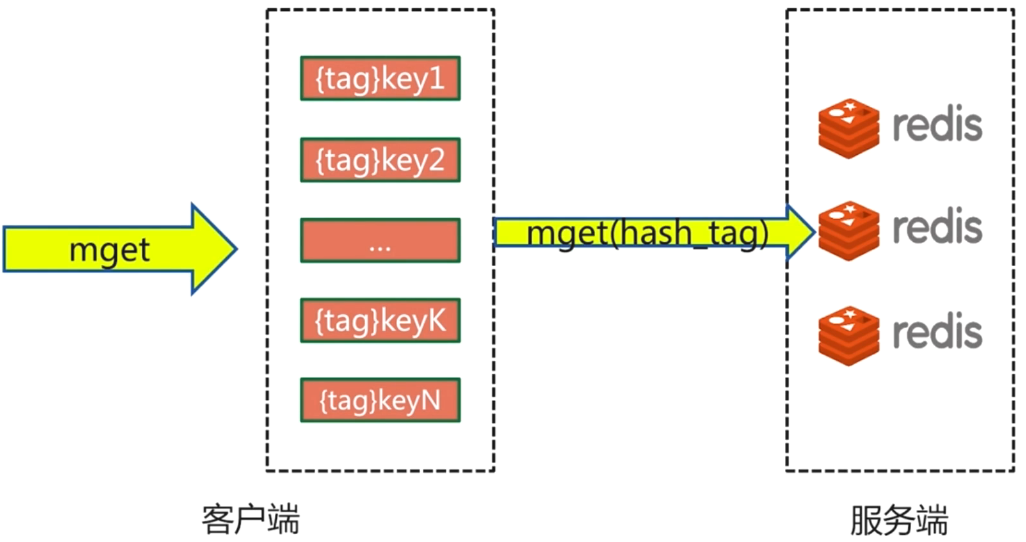
在mget的时候只需要在一台机器上去即可。
- 对比
方案三比较复杂,一般不用;方案四可能会出现数据倾斜,也不用。方案一在key小的时候可以用;方案二相对来说有一点优势;

为什么说是一点优势呢?pipeline批量处理不应该比串行处理好很多吗?
- http://xiezefan.me/2015/12/13/redis_cluster_research_2/
- http://trumandu.github.io/2016/05/09/RedisCluster构建批量操作探讨/
9. 故障转移
9.1 故障发现
- 通过
ping/pong消息实现故障发现:不需要sentinel - 分为主观下线和客观下线
主观下线:
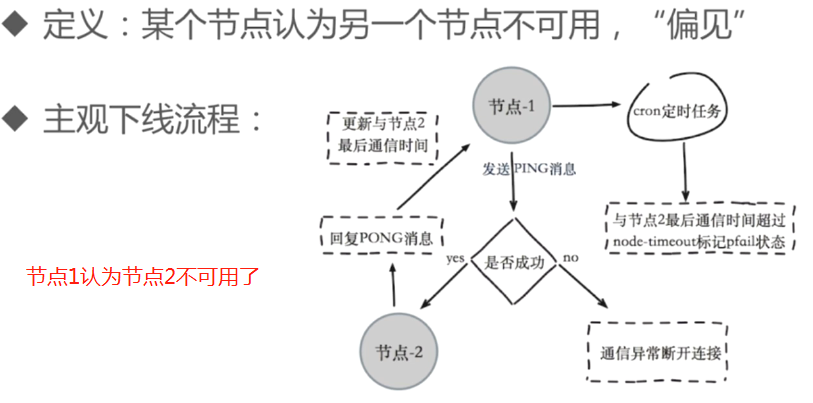
客观下线:
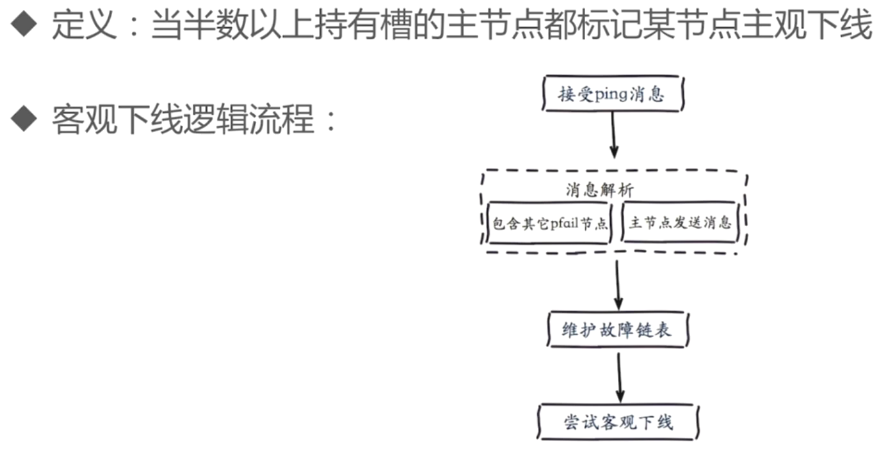
pfail消息就是主观下线的信息,维护在一个链表中,链表中包含了所有其他节点对其他节点所有的主观信息,是有时间周期的,为了防止很早以前的主观下线信息还残留在这里。对这个链表进行分析,符合条件就尝试客观下线。

9.2 故障恢复
从节点接收到他的主节点客观下线的通知,则进行故障恢复的操作。
- 资格检查
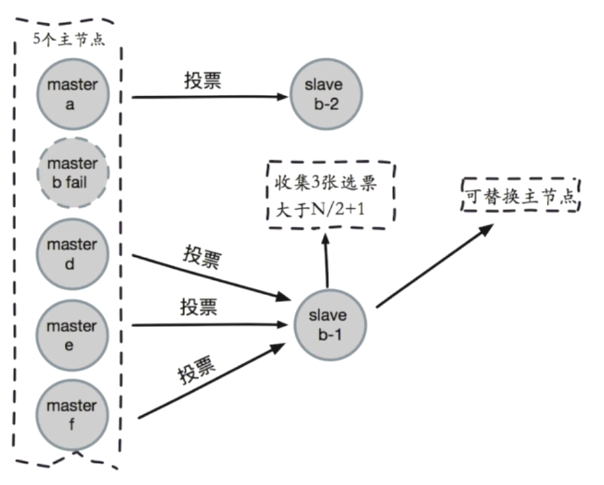
选取出符合条件的从节点:当从节点和故障主节点的断线时间太长,会被取消资格。
- 准备选举时间
就是为了保证偏移量大的从节点优先被选举投票

- 选举投票
- 替换主节点

这些所有步骤加起来,差不多十几秒左右。最后如果故障节点又恢复功能了,就称为新的Master的slave节点。
10. 常见问题
10.1 集群完整性
cluster-require-full-coverage默认为yes
- 要求所有节点都在服务,集群中16384个槽全部可用:保证集群完整性
- 节点故障或者正在故障转移:`(error)CLUSTERDOWN the cluster is down`
但是大多数业务都无法容忍。需要将cluster-require-full-coverage设置为no
10.2 带宽消耗
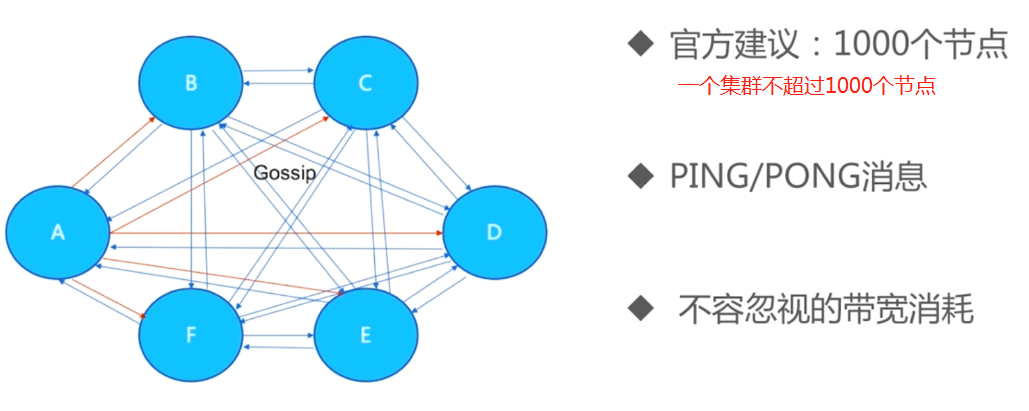
- 消息发送频率:节点发现与其他节点最后通信时间超过
cluster-node-timeout/2时会直接发送Ping消息 - 消息数据量:
slots槽数组(2k空间)和整个集群1、10的状态数据(10个节点状态数据约10k) - 节点部署的机器规模:进去分布的机器越多且每台机器划分的节点数越均匀,则集群内整体的可用带宽越高。
- 优化:避免“大”集群,:避免多业务使用一个集群,大业务可用多集群;
cluster-node-timeout时间设置要注意是带宽和故障转移速度的均衡;尽量均匀分配到多机器上:保证高可用和带宽。
10.3 PubSub广播
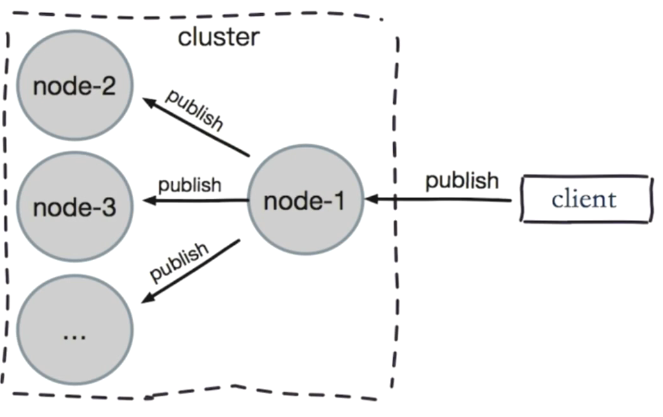
- 问题:
publish在集群中每个节点广播:加重带宽。 - 解决:单独“走”一套
redis sentinel。就是针对目标的几个节点构建redis sentinel,在这个里面实现广播。
10.4 数据倾斜
- 节点和槽分配不均匀
./redis-trib.rb info ip:port查看节点、槽、键值分布- 慎用
rebalance命令
- 不同槽位对应键数量差异较大
- CRC16正常情况下比较均匀
- 可能存在
hash_tag cluster countKeysinslot {slot}获取槽对应键值个数
- 包含
bigkey- 例如大字符串、几百万的元素的
hash、set等 - 在从节点上执行:
redis-cli --bigkeys来查看bigkey情况 - 优化:优化数据结构
- 例如大字符串、几百万的元素的
- 内存相关配置不一致
- 因为某种情况下,某个节点对
hash或者Set这种数据结构进行了单独的优化,而其他节点都没有配置,会出现配置不一致的情况。
- 因为某种情况下,某个节点对
10.5 请求倾斜
- 热点key:重要的
key或者bigkey - 优化:避免
bigkey;热键不使用hash_tag;当一致性不高时,可以用本地缓存+MQ
10.6 读写分离
- 只读连接:集群模式的从节点不接受任何读写请求
重定向到负责槽的主节点(对从节点进行读,都是重定向到主节点再返回信息)
readonly命令可以读:连接级别命令(每次重新连接都要写一次)
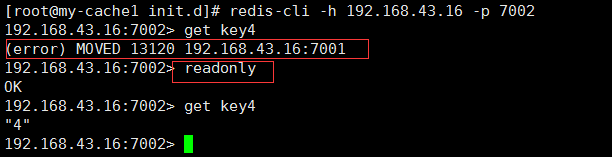
上图可以看出,redis cluster 默认slave 也是不能读的,如果要读取,需要执行 readonly,就可以了。
- 读写分离:更加复杂(成本很高,尽量不要使用)
同样的问题:复制延迟、读取过期数据、从节点故障
修改客户端
10.7 数据迁移
分为离线迁移和在线迁移(唯品会redis-migrate-tool和豌豆荚redis-port)。
官方的方式:只能从单机迁移到集群、不支持在线迁移、不支持断点续传、单线程迁移影响速度
./redis-trib.rb import --from 源ip:port --copy 目标ip:port
加入在迁移时再往源redis插入几条数据,这几条数据会丢失(丢失一部分)
10.8 集群vs单机
集群也有一定的限制:

分布式redis不一定是好的:

11. 简单总结

