
Redis-Sentinel实现高可用读写分离
本文为redis学习笔记的第七篇文章。Redis Sentinel 是一个分布式系统,你可以在一个架构中运行多个 Sentinel 进程,这些进程使用流言协议(gossip protocols)来接收关于主服务器是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个从服务器作为新的主服务器。
虽然 Redis Sentinel 是一个单独的可执行文件 redis-sentinel ,但实际上它只是一个运行在特殊模式下的 Redis 服务器,你可以在启动一个普通 Redis 服务器时通过给定 –sentinel 选项来启动 Redis Sentinel 。
- 启动方式一:使用
sentinel可执行文件redis-sentinel程序来启动Sentinel系统,命令如下:
1 | redis-sentinel /path/to/sentinel.conf |
sentinel只是运行在特殊模式下的redis服务器,你可以用启动redis服务的命令来启动一个运行在Sentinel模式下的Redis服务器:
1 | redis-server /path/to/sentinel.conf --sentinel |
1. redis sentinel
首先来看看什么是 redis sentinel,中文翻译是redis哨兵。顾名思义,哨兵是站岗监督突发情况的,那么这里具体的功能上很类似:
- 监控:
Sentinel会不断地检查你的主服务器和从服务器是否运作正常。 - 提醒:当被监控的某个
Redis服务器出现问题时,Sentinel可以通过 API 向管理员或者其他应用程序发送通知。 - 自动故障迁移:当一个主服务器不能正常工作时,
Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
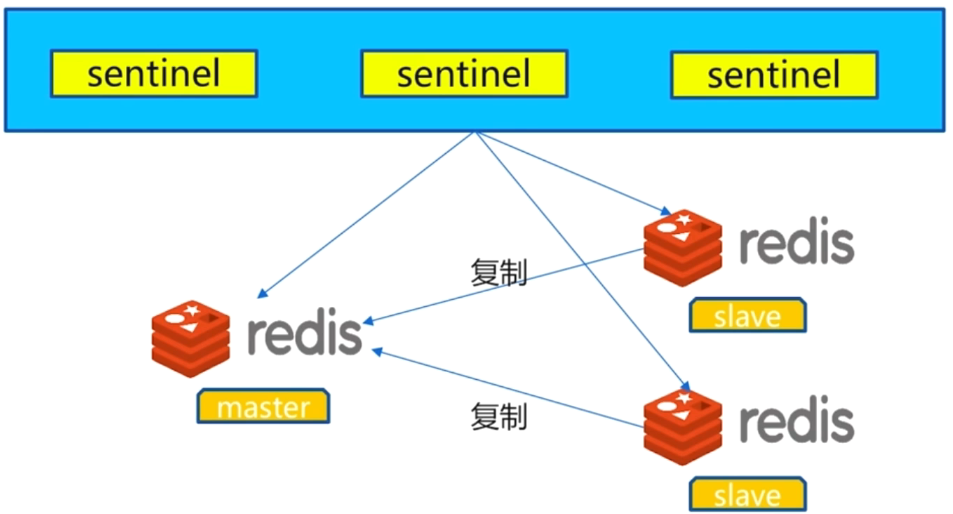
其中总结一下故障转移的基本原理:
- 多个
sentinel发现并确认master有问题 - 选举出一个
sentinel作为领导 - 选出一个可以成为新的
master的slave - 通知其他的
slave称为新的master的slave - 通知客户端主从变化
- 等待老的
master复活称为新的master的slave
也支持多个master-slave结构:
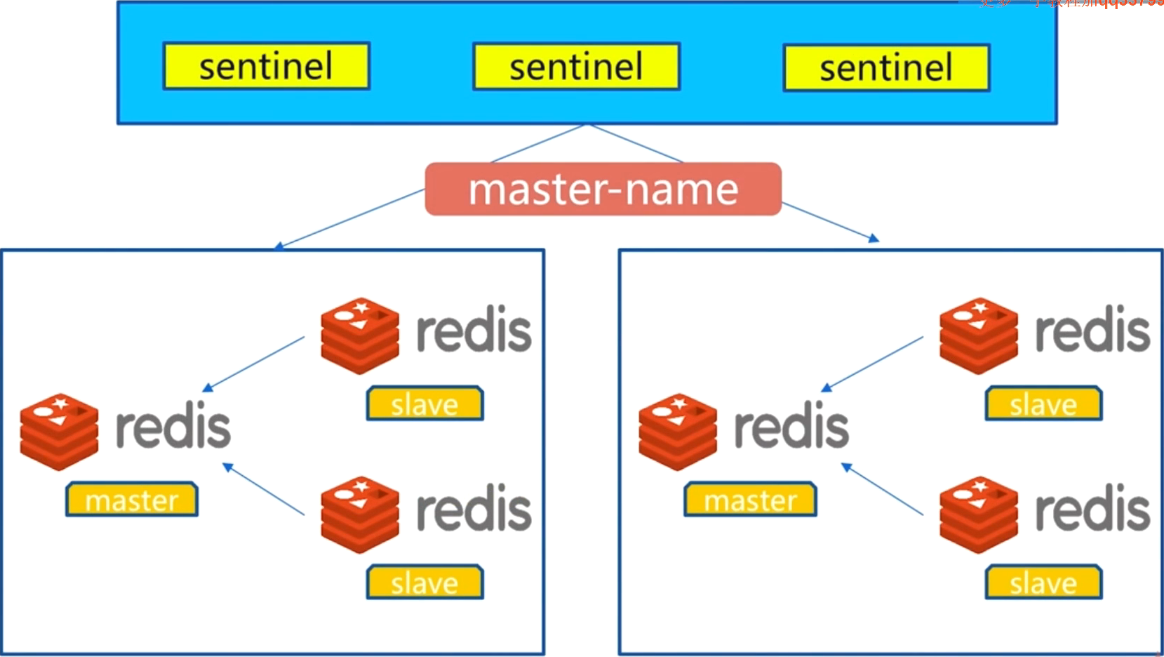
2. 安装与配置
- 配置开启主从节点
- 配置开启
sentinel监控主节点(sentinel是特殊的redis) - 实际应该多台机器,但是演示方便,只用一台机器来搭建
- 详细配置节点
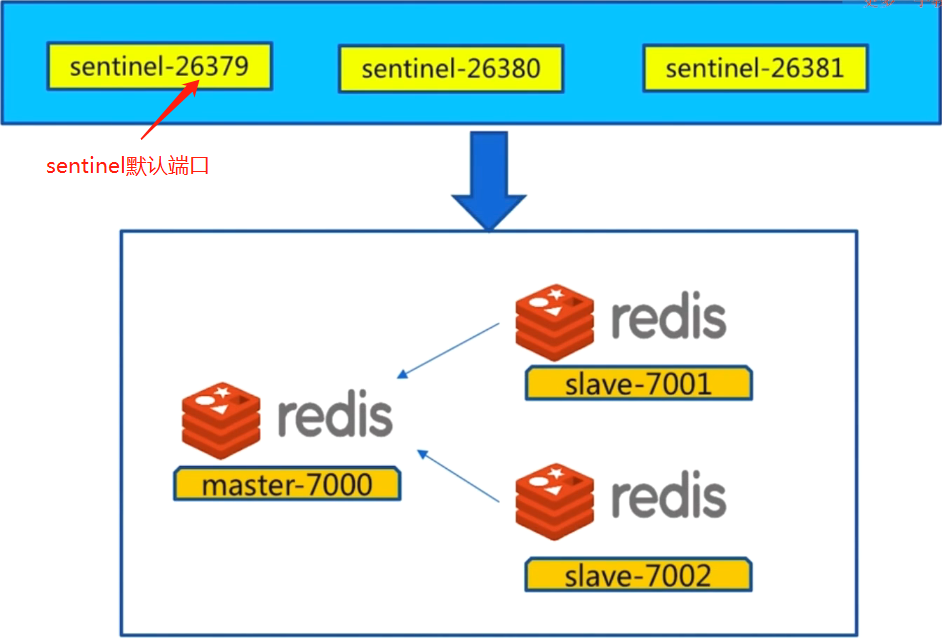
本地安装的结构图:
对于master:redis-7000.conf配置:

1 | port 7000 |
对于slave:redis-7001和redis-7002配置:
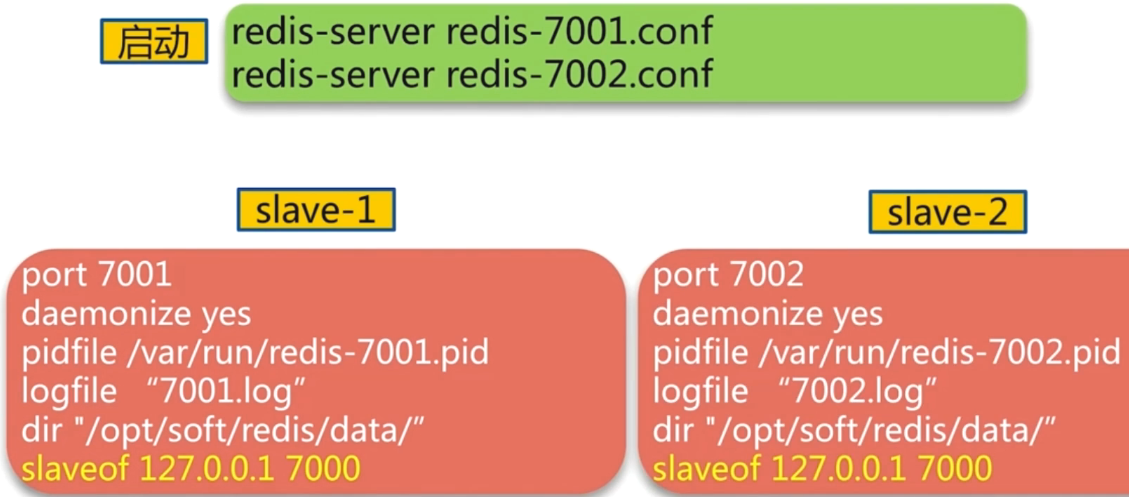
1 | port 7001 |
启动redis服务:
1 | redis-server ../config/redis-7000.conf |
访问7000端口的master redis:
1 | redis-cli -p 7000 info replication |
显示他有两个从节点:
1 | # Replication |
对于sentinel主要配置:

master sentinel config:
1 | port 26379 |
启动redis sentinel:
1 | redis-sentinel ../config/redis-sentinel-26379.conf |
访问26379 redis sentinel master:
1 | redis-cli -p 26379 info sentinel |
显示:
1 | # Sentinel |
1 | 查看这六个进程是否都起来了:ps -ef | grep redis |
注意,如果上面是配置在虚拟机的话,需要将127.0.0.1改为虚拟机的ip,要不然找不着。
3. 故障转移演练
3.1 java客户端程序
JedisSentinelPool只是一个配置中心,不需要具体连接某个redis,注意它不是代理。
1 | private Logger logger = LoggerFactory.getLogger(AppTest.class); |
maven依赖是:
1 | <!--jedis--> |
启动程序,发现是正常写入:
1 | 16:16:01.424 [main] INFO com.njupt.swg.AppTest - k-54795 value is v-54795 |
我们将现在的端口为7000的redis master 给kill掉
kill -9 master的pid
我们会发现:客户端报异常,但是在大概十几秒之后,就继续正常塞值了。原因是服务端的哨兵机制的选举matser需要一定的时间。
4. 三个定时任务
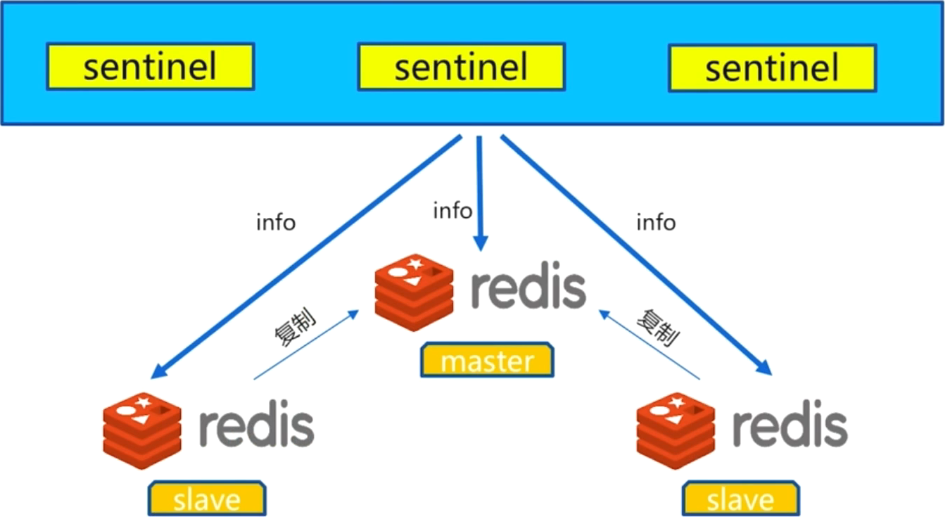
4.1 每10秒每个sentinel对master和slave执行Info
- 发现
slave节点 - 确认主从关系
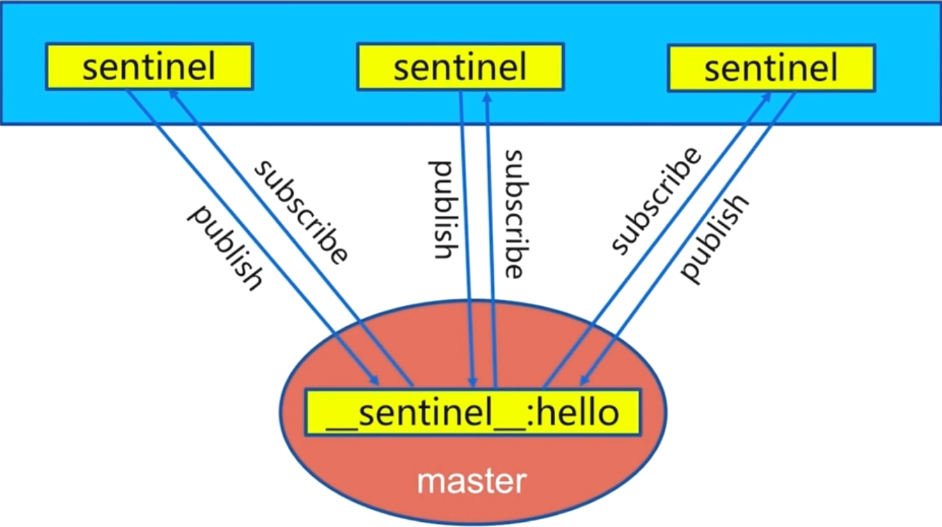
4.2 每2秒每个sentinel通过master节点的channel交换信息(pub/sub)
- 通过
__sentinel__:hello进行频道交互 - 交互对节点的“看法”和自身信息
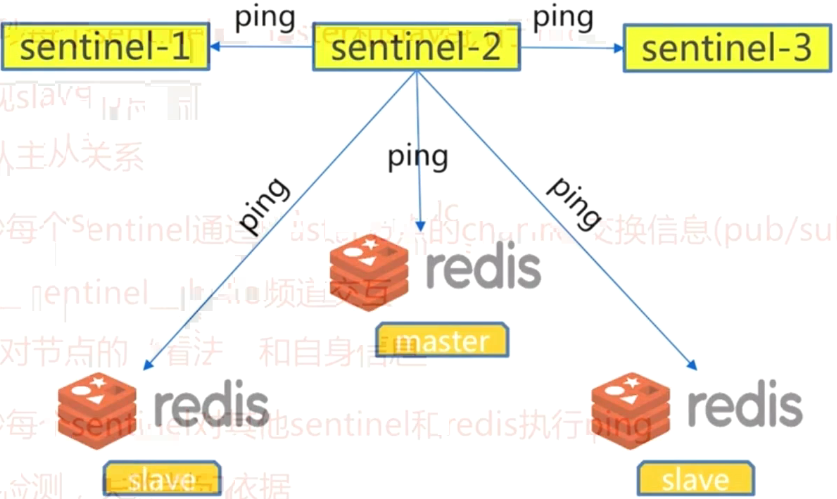
4.3 每1秒每个sentinel对其他sentinel和redis执行ping
- 心跳监测,失败判定依据
5. 主观下线和客观下线
对于之前的Sentinel配置文件中有两条配置:
监控master redis节点,这里是当超过两个sentinel认为master挂了,则认为master挂了。
sentinel monitor <masterName> <masterIp> <msterPort> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
这里是每秒sentinel都会去Ping周围的master redis,超过30秒没有任何响应,说明其挂了。
sentinel down-after-milliseconds <masterName> <timeout>
sentinel down-after-milliseconds mymaster 300000
5.1 主观下线
主观下线:每个sentinel节点对Redis节点失败的“偏见”
这是一种主观下线。因为在复杂的网络环境下,这个sentinel与这个master不通,但是master与其他的sentinel都是通的呢?所以是一种“偏见”
这是依靠的第三种定时:每秒去ping一下周围的sentinel和redis。对于slave redis,可以使用这个主观下线,因为他不需要进行故障转移。
5.2 客观下线
客观下线:所有sentinel节点对master Redis节点失败“达成共识”(超过quorum个则统一)
这是依靠的第二种定时:每两秒,sentinel之间进行“商量”,传递的消息是:sentinel is-master-down-by-addr
对于master redis的下线,必须要达成共识才可以,因为涉及故障转移,仅仅依靠一个sentinel判断是不够的。
6. 领导者选举
原因:只有一个sentinel节点完成故障转移
选举:通过sentinel is-master-down-by-addr命令都希望成为领导者
- 每个做主观下线的
sentinel节点向其他sentinel节点发送命令,要求将它设置为领导者 - 收到命令的
sentinel节点如果还没有同意过其他semtinel节点发送的命令,那么将同意该请求,否则拒绝 - 如果该
sentinel节点发现自己的票数已经超过sentinel集合半数并且超过quorum,那么它将成为领导者。 - 如果此过程中多个
sentinel节点成为了领导者,那么将等待一段时间重新进行选举
7. 故障转移
- 从
slave节点中选出一个“合适的”节点作为新的master节点 - 对上述的
slave节点执行“slaveof no one”命令使其成为master节点 - 向剩余的
slave节点发送命令,让它们成为新master节点的slave节点,复制规则和parallel-syncs参数一样 - 更新对原来的
master节点配置为slave,并保持着对其“关注”,当恢复后命令他去复制新的master节点
那么,如何选择“合适”的slave节点呢?
- 选择
slave-priority(slave节点优先级)最高的slave节点,如果存在则返回,不存在则继续。 - 选择复制偏移量最大的
slave节点(复制得最完整),如果存在则返回,不存在则继续 - 选择
run_id最小的slave节点(最早的节点)
8. 节点下线
主节点下线:sentinel failover <masterName>
从节点下线要注意读写分离问题。
9. 总结与思考
redis sentinel是redis高可用实现方案:故障发现、故障自动转移、配置中心、客户端通知。
redis sentinel从redis2.8版本才正式生产可用,之前版本不可生产用。
尽可能在不同物理机上部署
redis sentinel所有节点。
redis sentinel中的sentinel节点个数应该大于等于3且最好是奇数。
redis sentinel中的数据节点和普通数据节点没有区别。每个sentinel节点在本质上还是一个redis实例,只不过和redis数据节点不同的是,其主要作用是监控redis数据节点
客户端初始化时连接的是
sentinel节点集合,不再是具体的redis节点,但sentinel只是配置中心不是代理。
redis sentinel通过三个定时任务实现了sentinel节点对于主节点、从节点、其余sentinel节点的监控。
redis sentinel在对节点做失败判定时分为主观下线和客观下线。
看懂
redis sentinel故障转移日志对于redis sentinel以及问题排查非常有用。
redis sentinel实现读写分离高可用可以依赖sentinel节点的消息通知,获取redis数据节点的状态变化。
redis sentinel可以实现高可用的读写分离,高可用体现在故障转移,那么实现高可用的基础就是要有从节点,主从节点还实现了读写分离,减少master的压力。但是如果是从节点下线了,sentinel是不会对其进行故障转移的,并且连接从节点的客户端也无法获取到新的可用从节点,而这些问题在Cluster中都得到了有效的解决。
对于性能提高、容量扩展的时候,这种方式是比较复杂的,比较推荐的是使用集群,就是下面讨论的redis cluster!