
几种主流缓存框架介绍
本文为redis学习笔记的第十二篇文章。本文对Guava Cache,Memcache以及redis进行简单介绍和对比。
缓存特征
缓存都会涉及:命中率、最大元素、清空策略(FIFO,LFU,LRU,过期时间,随机)
影响缓存命中率因素
- 业务场景和业务需求:适合读多写少的场景
- 缓存的设计(粒度和策略):缓存粒度越小,命中率越高
- 缓存容量(经常用LRU)和基础设施(是否可扩展,避免缓存失效-一致性hash算法和几点冗余)
缓存分类
- 本地缓存:编程实现(成员变量、局部变量、静态变量)、Guava Cache
- 分布式缓存:Memcache,Redis
本地缓存:各应用之间无法很好地共享,与应用本身耦合过紧;而分布式缓存,本身就是独立的应用,各独立应用之间共享缓存。
Guava Cache

设计思想类似于jdk1.7中的ConcurrentHashMap,也是用多个segments的细粒度锁,在保证线程安全的同时,支持高并发场景的需求。
下面数据存储就是以键值对的形式存储,另外,需要处理缓存过期、动态加载等算法逻辑,所以需要一些额外的信息来实现这些操作。
主要实现的功能有:自动将节点加入到缓存结构中,当缓存的数据超过设置的最大值时,用LRU算法来移除。他具备根据节点上次被访问或者写入的时间来计算他的过期机制。
memcache
memcache简单认识
memcache是一个高性能的分布式的内存对象缓存系统,它在内存里维护一个统一的巨大的hash表。能用来缓存各种格式的数据,包括图像、视频、文件以及数据库检索等结果.
memcache是以守护程序方式运行于一个或多个服务器中,随时会接收客户的连接和操作。
存在memcache中的对象实际放置在内存中,这也是memcache如此高效的原因。
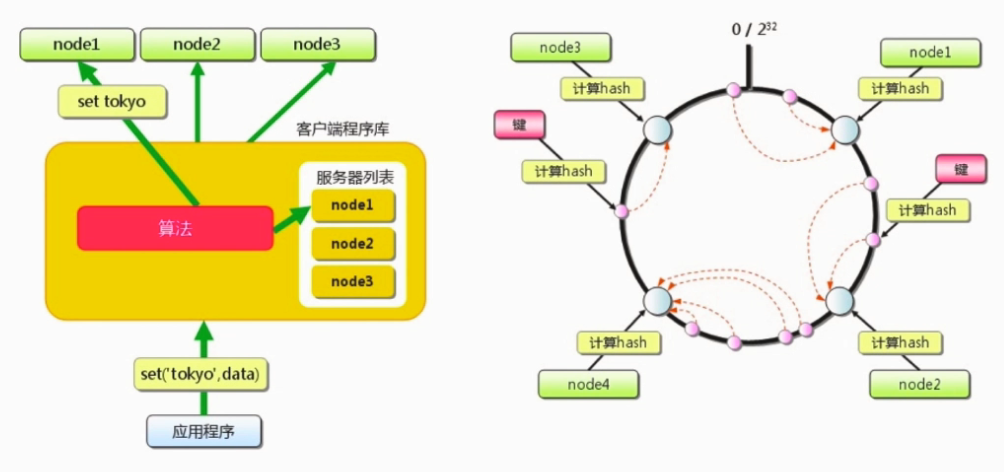
本身是不提供分布式的解决方案的。分布式是在客户端实现的,通过客户端的路由来处理达到分布式的目的。
应用服务器每次在存储某个key和value的时候,通过某种算法把key映射到某台服务器上。
一致性hash算法
客户端实现分布式:一致性hash算法,这个算法已经详细介绍过了。
memcache一些特性
Memcached单进程在32位系统中最大使用内存为2G,若在64位系统则没有限制,这是由于32位系统限制单进程最多可使用2G内存,要使用更多内存,可以分多个端口开启多个Memcached进程。
32 位寻址空间只有 4GB 大小,于是 32 位应用程序进程最大只能用到 4GB 的内存。然而,除了应用程序本身要用内存,操作系统内核也需要使用。应用程序使用的内存空间分为用户空间和内核空间,每个 32 位程序的用户空间可独享前 2GB 空间(指针值为正数),而内核空间为所有进程共享 2GB 空间(指针值为负数)。所以,32 位应用程序实际能够访问的内存地址空间最多只有 2GB。
最大30天的数据过期时间,设置为永久也会在这个时间过期。最长键长为250字节,大于该长度无法存储。最大同时连接数是200;
memcache是一种无阻塞的socket通信方式服务,基于libevent库,犹豫无阻塞通信,对内存读写速度非常快。
不适用memcached的业务场景?
缓存对象的大小大于1MB
虚拟主机不让运行
memcached服务
key的长度大于250字符
需要持久化
不能够遍历memcached中所有的item?
这个操作的速度相对缓慢且阻塞其他的操作
memcache如何分配内存?
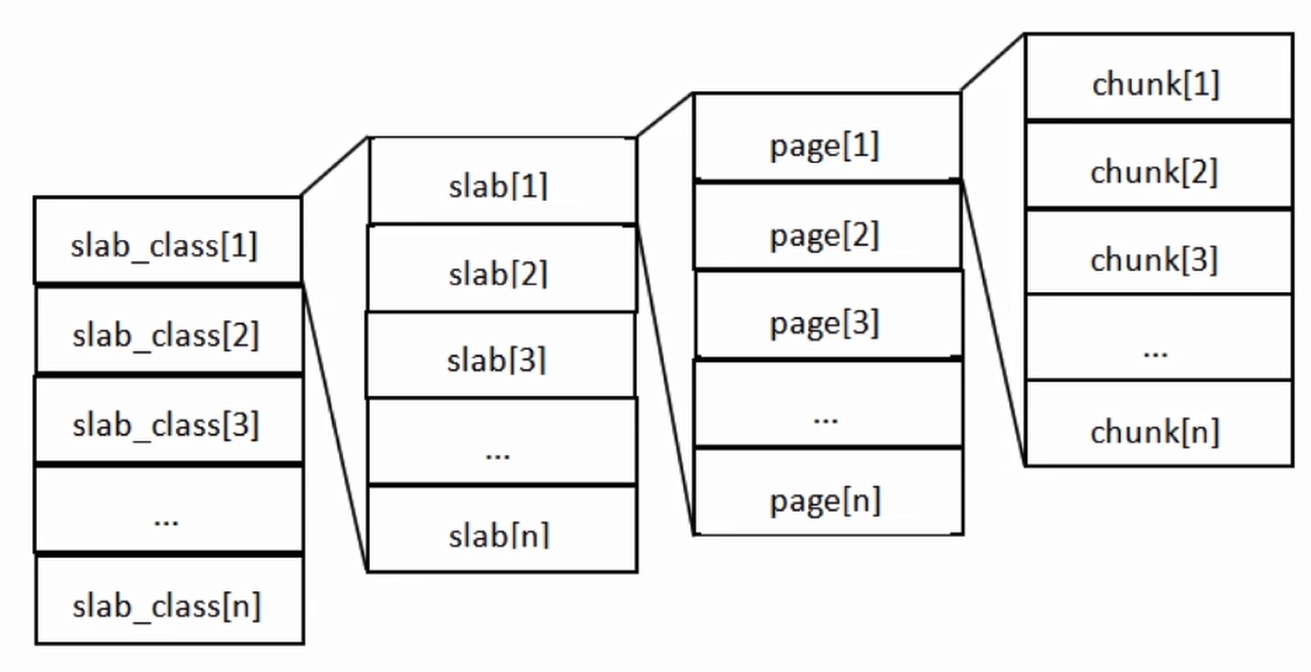
这张图片里面涉及了slab_class、slab、page、chunk四个概念,它们之间的关系是:
MemCache将内存空间分为一组slab- 每个
slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page - 每个page里面包含一组
chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的 - 有相同大小
chunk的slab被组织在一起,称为slab_class
那么是具体如何分配的呢?
MemCache中的value过来存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中,比如slab[1]的chunk大小为80字节、slab[2]的chunk大小为100字节、slab[3]的chunk大小为128字节(相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例),那么过来一个88字节的value,这个value将被放到2号slab中。
放
slab的时候,首先slab要申请内存,申请内存是以page为单位的,所以在放入第一个数据的时候,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk数组,最后从这个chunk数组中选择一个用于存储数据。
如果这个slab中没有
chunk可以分配了怎么办,如果MemCache启动没有追加-M(禁止LRU,这种情况下内存不够会报Out Of Memory错误),那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。
MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节(紧接着大的用)的chunk中,就损失了30字节,但是这也避免了管理内存碎片的问题
MemCache的LRU算法不是针对全局的,是针对slab的
- 该可以理解为什么
MemCache存放的value大小是限制的,因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了
最后再总结一下memcache
MemCache中可以保存的item数据量是没有限制的,只要内存足够MemCache单进程在32位机中最大使用内存为2G,64位机则没有限制Key最大为250个字节,超过该长度无法存储- 单个
item最大数据是1MB,超过1MB的数据不予存储 MemCache服务端是不安全的,比如已知某个MemCache节点,可以直接telnet过去,并通过flush_all让已经存在的键值对立即失效- 不能够遍历
MemCache中所有的item,因为这个操作的速度相对缓慢且会阻塞其他的操作 MemCache的高性能源自于两阶段哈希结构:第一阶段在客户端,通过Hash算法根据Key值算出一个节点;第二阶段在服务端,通过一个内部的Hash算法,查找真正的item并返回给客户端。从实现的角度看,MemCache是一个非阻塞的、基于事件的服务器程序MemCache设置添加某一个Key值的时候,传入expire为0表示这个Key值永久有效,这个Key值也会在30天之后失效
redis
redis特点
- 支持数据持久化,可以将内存中的数据保存到磁盘。
- 支持更多的数据结构
- 支持数据备份
- 性能极高,读可以达到11万次每秒;写达到8万1千次每秒
- redis所有操作都是原子性,并且支持几个操作一起的原子性
- 支持发布-订阅功能
redis适用场景
- 取最新n个数据、排行榜
- 精准过期时间
- 计数器
- 唯一性检查
- 实时系统、垃圾系统、缓存等
redis VS memcache
当提到redis就问memcache,当提到memcache就提到redis,说明这两者用的都十分广泛,redis号称“强化版memcached”,他们之间的区别到底是啥呢?
- 基本命令
memcache支持的命令很少,因为他只支持String的操作,通讯协议包括文本格式和二进制格式,用于满足简单网络客户端工具(如telnet)和对性能要求更高的客户端的不同需求;redis操作类似,只是数据结构更复杂以支持更多的特性,如发布订阅、消息队列等。redis的客户端-服务器通讯协议完全采用文本格式(Redis Cluster服务端节点之间通讯采用二进制格式)。
- 事务
redis通过multi/watch/exec等命令可以支持事务的概念,原子性的执行一批命令;
memcache:即使在多线程模式,所有的命令都是原子的;命令序列不是原子的。在并发的情况下,您也可能覆写了一个被其他进程set的item。memcached 1.2.5以及更高版本,提供了gets和cas命令,它们可以解决上面的问题。如果您使用gets命令查询某个key的item,memcached会给您返回该item当前值的唯一标识。如果您覆写了这个item并想把它写回到memcached中,您可以通过cas命令把那个唯一标识一起发送给memcached。如果该item存放在memcached中的唯一标识与您提供的一致,您的写操作将会成功。如果另一个进程在这期间也修改了这个item,那么该item存放在memcached中的唯一标识将会改变,您的写操作就会失败。
- 数据备份,有效性,持久化等
memcached不保证存储的数据的有效性,slab内部基于LRU也会自动淘汰旧数据;memcached也不做数据的持久化工作;
redis可以以master-slave的方式配置服务器,slave节点对数据进行replica备份,slave节点也可以充当read only的节点分担数据读取的工作;redis内建支持两种持久化方案,snapshot快照和AOF增量Log方式。
- 性能
memcached自身并不主动定期检查和标记哪些数据需要被淘汰,只有当再次读取相关数据时才检查时间戳,或者当内存不够使用需要主动淘汰数据时进一步检查LRU数据。
redis为了减少大量小数据CMD操作的网络通讯时间开销RTT (Round Trip Time),支持pipeline和script技术。
- 集群
memcached的服务器端互相完全独立,客户端通常通过对键值应用hash算法决定数据的分区,为了减少服务器的增减对hash结果的影响,导致大面积的缓存失效,多数客户端实现了一致性hash算法。
redis3.0已经支持服务端集群了。
- 性能对比
由于
redis只使用单核,而memcached可以使用多核,所以平均每一个核上redis在存储小数据时比memcached性能更高。而在100k以上的数据中,memcached性能要高于redis,虽然redis最近也在存储大数据的性能上进行优化,但是比起memcached,还是稍有逊色
- 内存使用效率
使用简单的
key-value存储的话,memcached的内存利用率更高,而如果redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于memcached。另外,memcached使用预分配的内存池的方式,带来一定程度的空间浪费 并且在内存仍然有很大空间时,新的数据也可能会被剔除,而redis使用现场申请内存的方式来存储数据,不会剔除任何非临时数据 redis更适合作为存储而不是cache。
redis支持服务器端的数据操作
redis相比memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么redis会是不错的选择
何时应该使用memcache:
首先就是对小型静态数据进行缓存处理,最具代表性的例子就是HTML代码片段。这是因为
memcached在处理元数据时所消耗的内存资源相对更少.在以前,
redis3.0版本之前,memcached在横向扩展方面也比redis更具优势。由于其在设计上的思路倾向以及相对更为简单的功能设置,memcached在实现扩展时的难度比redis低得多。
何时应该使用redis:
其他场景都可以用
redis来替换。相比于武断的
LRU(即最低近期使用量)算法,redis允许用户更为精准地进行细化控制,利用六种不同回收策略确切提高缓存资源的实际利用率。redis还采用更为复杂的内存管理与回收对象备选方案。
memcached将键名限制在250字节,值也被限制在不超过1MB,且只适用于普通字符串。redis则将键名与值的最大上限各自设定为512MB,且支持二进制格式。它所保存的数据具备透明化特性,也就是说服务器能够直接对这些数据进行操作.
redis还提供可选而且能够具体调整的数据持久性方案
redis能够提供复制功能。复制功能旨在帮助缓存体系实现高可用性配置方案,从而在遭遇故障的情况下继续为应用程序提供不间断的缓存服务。
使用redis的正确姿势:
要进行
master-slave配置,出现服务故障时可以支持切换。在
master侧禁用数据持久化,只需在slave上配置数据持久化。物理内存+虚拟内存不足,这个时候
dump一直死着,时间久了机器挂掉。这个情况就是灾难。当
redis物理内存使用超过内存总容量的3/5时就会开始比较危险了,就开始做swap,内存碎片大。当达到最大内存时,会清空带有过期时间的
key,即使key未到过期时间。
redis与DB同步写的问题,先写DB,后写redis,因为写内存基本上没有问题。