
JAVA内存模型常问面试题
本篇为学习JAVA虚拟机的第七篇文章,介绍一些面试比较常问的问题。
一、JVM三大性能调优参数-Xms -Xmx -Xss的含义
一般我们可以传入以下参数去调整堆和内存所占的大小:
1 | java -Xms128m -Xmx128m -Xss256k -jar xxx.jar |
- -Xms :堆的初始值
- -Xmx :堆能达到的最大值
- -Xss :规定了每个线程虚拟机栈的大小
二、JAVA内存模型中堆和栈的区别
首先来了解一下几种不同的内存分配策略:
- 静态存储:编译时确定每个数据目标在运行时的存储空间需求,比如static声明的静态变量,这里的数据一般都放在方法区,java8中这个区域叫做元数据区,用的时物理内存,并且之前合在一起的字符串常量池也被移到了堆区,详情见上一篇文章。
- 栈式存储:数据去需求在编译时未知,运行时模块入口前确定,比如基本数据类型,都是在运行的时候,才知道数据(字面量)到底是什么,对于JVM,一个方法内的执行,局部变量表和操作数栈的大小时确定的,即引用变量和栈空间大小是编译器确定的,至于字面量等运行时才能确定。
- 堆式存储:编译时或运行时模块入口都无法确定,动态分配,比如可变长度串、对象实例
下面来看看栈和堆的联系:
引用对象或者数组时,栈里定义变量保存堆中目标的首地址。
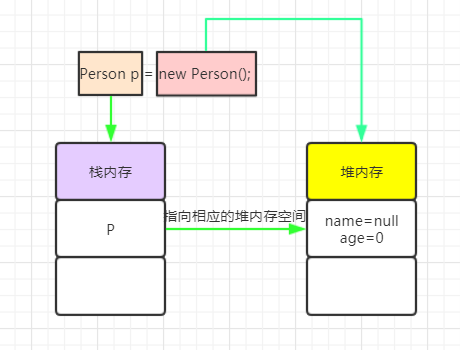
下面来看看栈和堆的区别:
- 管理方式:栈自动释放,堆需要GC
- 空间大小:栈比堆小
- 碎片相关:栈产生的碎片远小于堆
- 分配方式:栈支持静态和动态分配,而堆仅支持动态分配
- 效率:栈的效率比堆高
简单总结:栈比较小,随着方法执行完毕自动释放,栈数据结构简单,所以操作也简单高效。堆放各种对象实例和数组,必定要比较大的空间,那么需要GC来回收不需要的数据,效率低并且碎片也比较多,由于堆的操作比较复杂,所以数据结构也复杂,效率低。
三、元空间、堆、线程独占部分间的联系
先来看一个最简单的程序:
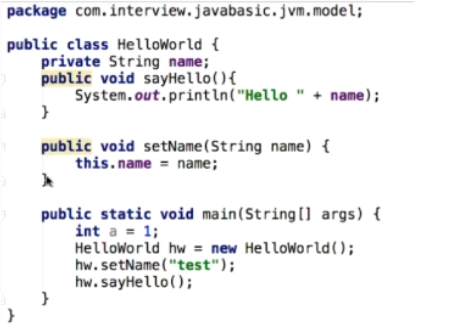
我们分别从元空间、堆、以及线程独占的部分来看看分别存储了啥:

学到这里,对于这些东西已经不需要解释了。针对JVM内存模型的知识在这里就串联起来了。了解到这里,对内存模型这一块基本的知识已经差不多了。
四、再来说说字符串
之前在java字符串核心一网打尽文章中,其实是对于JDK8这个版本的字符串特性进行详细的解读,其中也介绍了intern这个方法的含义和用法,由于JDK6和JDK6+关于intern是不一样的,这里对比一下。
对于JDK8:
1 | public static void main(String[] args) throws ClassNotFoundException { |
输出结果为:
1 | false |
但是在JDK6中执行结果为:
1 | false |
这个问题困扰了我很久,由于之前基础不是太扎实,所以直接就跳过了这个问题,在面试的时候几乎也不会太深究,但是一直成为我心里的坎。今天要把他解决掉。在说明这个问题之前,需要说明一下JVM有三种常量池:
4.1 三种常量池
- Class文件中的常量池
这里面主要存放两大类常量:字面量和符号引用,符号引用包含三类常量:
- 类和接口的全限定名(
Full Qualified Name) - 字段的名称和描述符(
Descriptor) - 方法的名称和描述符
这个用javap看一下就能明白,这里只涉及字符串就不谈其他的了。简单地说,用双引号引起来的字符串字面量都会进这里面。
1 | String str2 = "a"; |
这里的str2就是符号引用,a就是字面量。
- 运行时常量池
方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池(Constant Pool Table),存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池。
- 全局字符串
HotSpot VM里,记录interned string的一个全局表叫做StringTable,它本质上就是个HashSet<String>。这是个纯运行时的结构,而且是惰性(lazy)维护的。
注意,它里面存放的是引用。
所以,一般我们说一个字符串进入了全局的字符串常量池其实是说在这个StringTable中保存了对它的引用,反之,如果说没有在其中就是说StringTable中没有对它的引用。
4.2 字面量进入字符串常量池的时机
先给出一个结论:就HotSpot VM的实现来说,加载类的时候,那些字符串字面量会进入到当前类的运行时常量池,不会进入全局的字符串常量池(即在StringTable中并没有相应的引用,在堆中也没有对应的对象产生)
那么加载类的过程发生的是什么呢?
R大的一篇文章:
在类加载阶段, JVM会在堆中创建 对应这些 class文件常量池中的 字符串对象实例 并在字符串常量池中驻留其引用。具体在resolve阶段执行。这些常量全局共享。
这里说的比较笼统,没错,是resolve阶段,但是并不是大家想的那样,立即就创建对象并且在字符串常量池中驻留了引用。 JVM规范里明确指定resolve阶段可以是lazy的。
所以,类加载的时候,必定要做的东西是,将class文件中字面量和符号引用放入运行时常量池中,而JVM规范里Class文件的常量池项的类型,有两种东西:CONSTANT_Utf8和CONSTANT_String。后者是String常量的类型,但它并不直接持有String常量的内容,而是只持有一个index,这个index所指定的另一个常量池项必须是一个CONSTANT_Utf8类型的常量,这里才真正持有字符串的内容。
CONSTANT_Utf8会在类加载的过程中就全部创建出来,而CONSTANT_String则是lazy resolve的,例如说在第一次引用该项的ldc指令被第一次执行到的时候才会resolve。
4.3 ldc指令是什么东西?
简单地说,它用于将int、float或String型常量值从常量池中推送至栈顶
以下面代码为例:
1 | public class Abc { |
查看其编译后的Class文件如下:
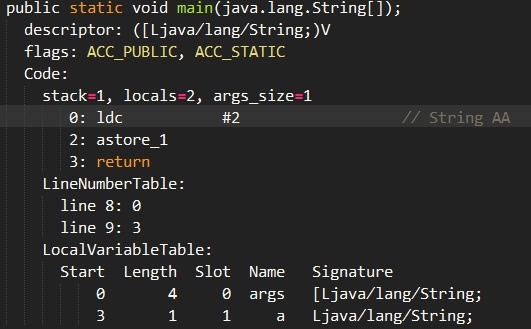
根据上面说的,在类加载阶段,这个 resolve 阶段( constant pool resolution)是lazy的。换句话说并没有真正的对象,字符串常量池里自然也没有。执行ldc指令就是触发这个lazy resolution动作的条件。
ldc字节码在这里的执行语义是:到当前类的运行时常量池去查找该index对应的项,即上面说的CONSTANT_String指向的index,如果该项尚未resolve则resolve之,并返回resolve后的内容。
在遇到String类型常量时,resolve的过程如果发现StringTable已经有了内容匹配的java.lang.String的引用,则直接返回这个引用,反之,如果StringTable里尚未有内容匹配的String实例的引用,则会在Java堆里创建一个对应内容的String对象,然后在StringTable记录下这个引用,并返回这个引用出去。
这里很重要,昭示了一个重要问题:String a = "AA";这一句执行完,要看字符串常量池中是否已经存在,不存在的话是要在堆中先创建对象的,然后把堆地址给全局的字符串常量池。
理解到这,有些问题就可以解决了,这里先不回答最上面的问题,先来看看下面的例子。注意运行环境是JDK8:
1 | class NewTest0 { |
"static" "he" "llo" "hello"都会进入Class的常量池, 按照上面说的,类加载阶段由于resolve 阶段是lazy的,所以是不会创建实例,更不会驻留字符串常量池了。
但是要注意这个“static”和其他三个不一样,它是静态的,在类加载阶段中的初始化阶段,会为静态变量指定初始值,也就是要把“static”赋值给s1,这个赋值操作要怎么搞啊,先ldc指令把它放到栈顶,然后用putstatic指令完成赋值。注意,ldc指令,根据上面说的,会创建"static"字符串对象,并且会保存一个指向它的引用到字符串常量池。
运行main方法后,首先是第二句,一样的,要先用ldc把"he"和"llo"送到栈顶,换句话说,会创建他俩的对象(注意,在堆中开辟本体所占的空间,还没到new的那一步),并且会保存引用到字符串常量池中(把本地在堆中空间地址传给字符串常量池);然后有个+号对吧,内部是创建了一个StringBuilder对象,一路append,最后调用StringBuilder对象的toString方法得到一个String对象(内容是hello,注意这个toString方法会new一个String对象),并把它赋值给s2(s2指向的是new出来的新对象,是新的一块内存空间)。
注意,此时还没有把hello的引用放入字符串常量池。然后是第三句,intern方法一看,字符串常量池里面没有,它会把上面的这个hello对象的引用保存到字符串常量池,然后返回这个引用,但是这个返回值我们并没有使用变量去接收,所以没用。
第四句,字符串常量池里面已经有了,直接用嘛。所以s2和s3都是s2的指向的地址。
再来看个例子:
1 | public static void main(String[] args) { |
首先是将一些符号引用和字面量从class文件的常量池中撞到运行时常量池。然后运行main方法,先看第一句,会创建"he"和"llo"对象,并放入字符串常量池,然后会创建一个"hello"对象,没有放入字符串常量池,s1指向这个"hello"对象。
第二句,创建"h"和"ello"对象,并放入字符串常量池,然后会创建一个"hello"对象,没有放入字符串常量池,s2指向这个"hello"对象。
第三句,字符串常量池里面还没有,于是会把s1指向的String对象的引用放入字符串常量池(换句话说,放入池中的引用和s1指向了同一个对象),然后会把这个引用返回给了s3,所以s3==s1是true。
第四句,字符串常量池里面已经有了,直接将它返回给了s4,所以s4==s1是true。
此时,回到一开始:
1 | public static void main(String[] args) throws ClassNotFoundException { |
在jdk1.6及以前,调用intern()
如果常量池中不存在值相等的字符串时,jvm会复制一个字符串到创量池中,并返回常量池中的字符串。
而在jdk1.7及以后,调用intern()
如果常量池中不存在值相等的字符串时,jvm只是在常量池记录当前字符串的引用,并返回当前字符串的引用。
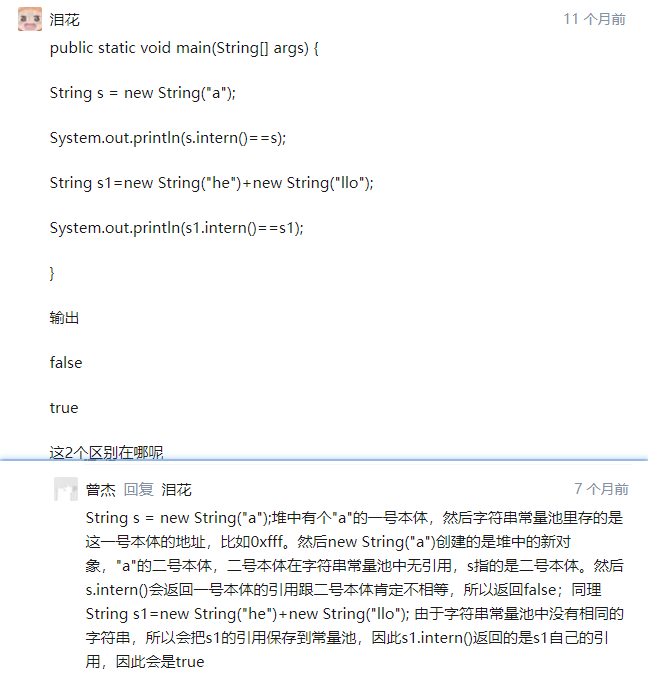
所以在JDK6情况下,都是返回false,原因是:第一种情况下,执行第一句,看到有个字符串"a",那么首先是创建"a"本体对象,并且把副本放入字符串常量池中。执行第二句,发现字符串常量池中已经存在,则不放了。执行第三句,
s2指向的是字符串常量池中的"a",这个字符串常量池"a"所在的地址,肯定与堆中的新new出来的不一样。所以返回false。
第二种情况,第一句相当于:
其实相当于:
1 | String s1 = new String("a"); |
会先在堆中创建两个对象"a",拷贝一个副本到字符串常量池中,此时"a"已经存在于字符串常量池中了。然后拼接生成一个新的对象"aa"在堆中,这种拼接出来的"aa"此时是不会把副本放进字符串常量池的,因为字符串常量池只保存已确定的字面量,这种拼接的属于运行完成才能确定,所以字符串常量池中没有,直到执行第6句,才会尝试把"aa"副本放入字符串常量池,但是还是跟上面一样,一个指向堆,一个指向字符串常量池,肯定不相等。
在JDK6+情况下,第一个返回false,第二个返回true。原因是:第一种情况下,执行第一句,首先是创建"a"本体对象,并且把引用放进字符串常量池中,然后new,开辟新的地址空间,此时str1指向的是new出来的空间的引用。执行第二句,尝试将str1的引用放入字符串常量池,但是池中已经存在了,所以不能放,所以一个指向堆,一个是本体对象的引用,不一样,所以为false。第二种情况,"a"跟上面一样,在堆中开辟,然后引用放入字符串常量池中,后面拼接成"aa",此时只是在堆中开辟空间,下面执行intern尝试把它的引用传给字符串常量池,由于字符串常量池中没有,所以就放进去了。此时字符串常量池中的引用与"aa"对象实际的堆地址是一样的,所以为true.
这边有一个事实:在执行String s1 = new String("a")的new之前,JVM先看到有一个字符串"a",则会先看看字符串常量池中是否有这个"a",有则直接返回字符串常量池引用,没有则给它开辟空间,并且把这个空间的引用传给字符串常量池。
整理自:木女孩的回答