
java多线程之传参和返回值处理
本文是关于JAVA多线程和并发的第二篇,对于传参和返回值的问题,是面试中关于多线程这一块问得比较多的问题了,这里进行详细的说明。
一、如何给run()方法传参
我们知道多线程是通过star()方法让线程处于准备就绪状态,而实际运行的业务逻辑是放在run()方法体中的,但是run()方法是没有参数的方法,实际的业务场景中,我们可能需要向方法体中传递参数,实现的方式主要有三种:
- 构造函数传参,这个在上一篇文章中已经演示了。
- 成员变量传参,这个就是依靠
set方法。 - 回调函数传参,这个稍微特殊一点。这里说明一下。
上面的两种向线程中传递数据的方法是最常用的。但这两种方法都是main方法中主动将数据传入线程类的。这对于线程来说,是被动接收这些数据的。
然而,在有些应用中需要在线程运行的过程中动态地获取数据,如在下面代码的run方法中产生了3个随机数,然后通过Work类的process方法求这三个随机数的和,并通过Data类的value将结果返回。从这个例子可以看出,在返回value之前,必须要得到三个随机数。也就是说,这个 value是无法事先就传入线程类的。
1 | class Data { |
其中一次的执行结果为:
1 | 707+678+173=1558 |
在上面代码中的process方法被称为回调函数。从本质上说,回调函数就是事件函数。在Windows API中常使用回调函数和调用API的程序之间进行数据交互。因此,调用回调函数的过程就是最原始的引发事件的过程。在这个例子中调用了process方法来获得数据也就相当于在run方法中引发了一个事件。
二、如何处理线程返回值
由于线程相当于一个异步的处理函数,想要获取它的结果就不能像传统的获取它的return的值那么简单了,主要问题就在于它什么时候能处理好是不知道的,需要一定的机制去等待它处理好了再去获取它的处理结果。方式一般有三种。
2.1 主线程等待法
这个方法是最简单也是最容易想到的处理方式。下面搞个实例来看看大概是如何操作的。
首先写一个类,写这个的含义是,假如主线程不等待,将会一口气执行到最后一行,此时子线程可能还没执行完。就会出现打印空。
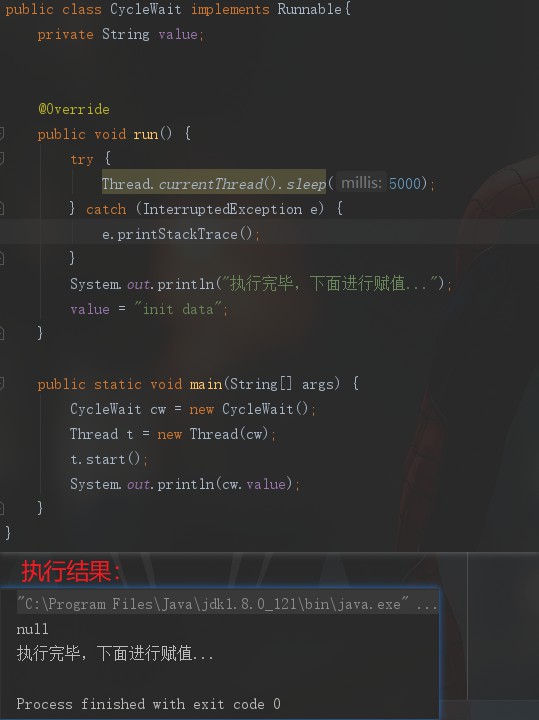
那么我们的主线程如何获取到子线程中赋予的值呢?一种方式就是死等,不停地轮询看你的值是否已经计算好了,一旦计算好就可以拿到这个值。类似于以下:
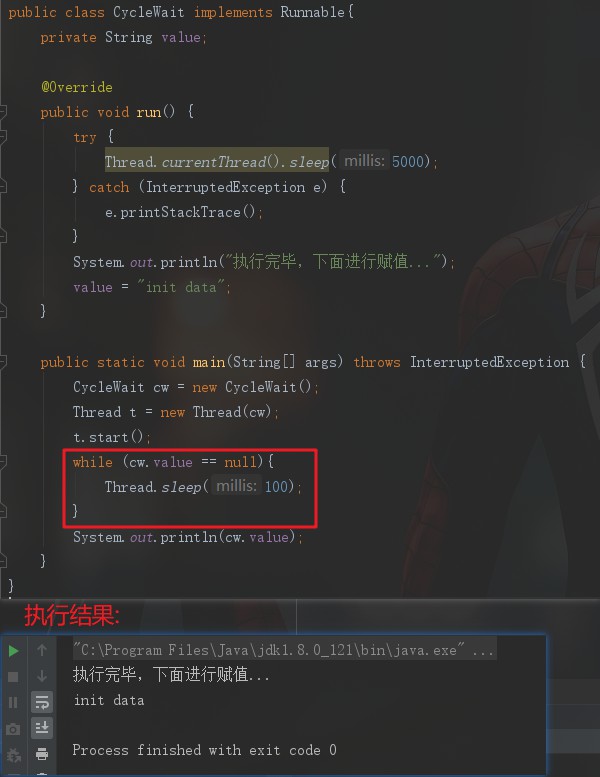
其实这就是自旋,即CPU停在这里等待,不能干其他事情,这必然会大大浪费CPU资源,所以虽然这种方式实现起来非常简单,但是不适合用。另外的缺点就是代码臃肿,比如我要等待的值不止一个,有多个,那是不是要写多个while循环来等待呢?此外,我们大多时候根本不知道这个子线程到底要执行多久,因为我们这里是每隔100毫秒轮询一次,那假如这个值在这100毫秒内值已经有了,那么是不能立即获取的。
针对以上不能精准控制的缺点,这里便有了第二种方法。
Join方法
Thread类中的join方法可以阻塞当前线程以等待子线程处理完毕。
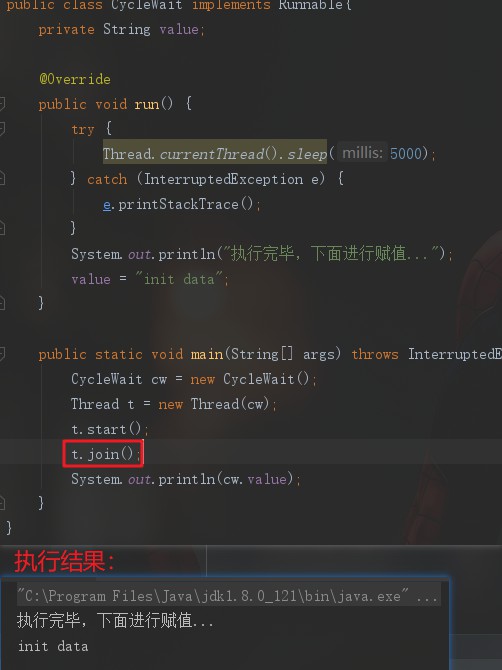
在这里,由于是在主线程中调用的join,所以阻塞主线程,让子线程执行完毕再继续执行。
这种方法更简单,但是存在多个子线程的情况下,做到灵活以及精准控制是做不到的。
Callable接口实现
JAVA提供了有返回值的任务,即实现了Callable接口的任务,执行这个任务之后可以获取一个叫做Futrue的对象,通过get()就可以获取Callable任务返回的内容。
具体是如何获取返回的内容呢?有两种方式,一个是通过FutureTask这个类来获取,一个是通过线程池获取。
对于第一种方式,我们通过例子来理解。
先新建一个实现了Callable接口的任务:

把Callable任务放进FutureTask中,这个FutureTask再放进Thread中去执行:
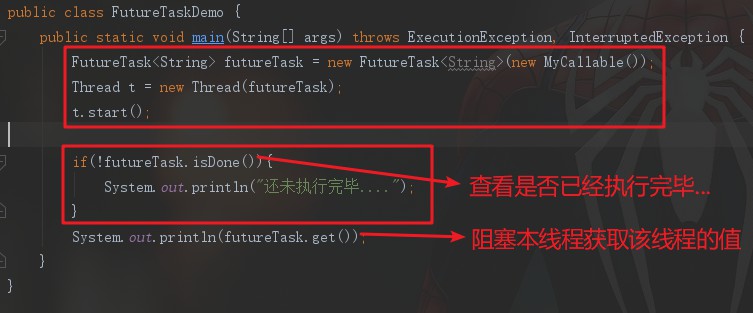
发现我们的程序并没有显示地等待,FutureTask的get()方法完成了等待和获取返回值。下面来看看Future的继承关系:
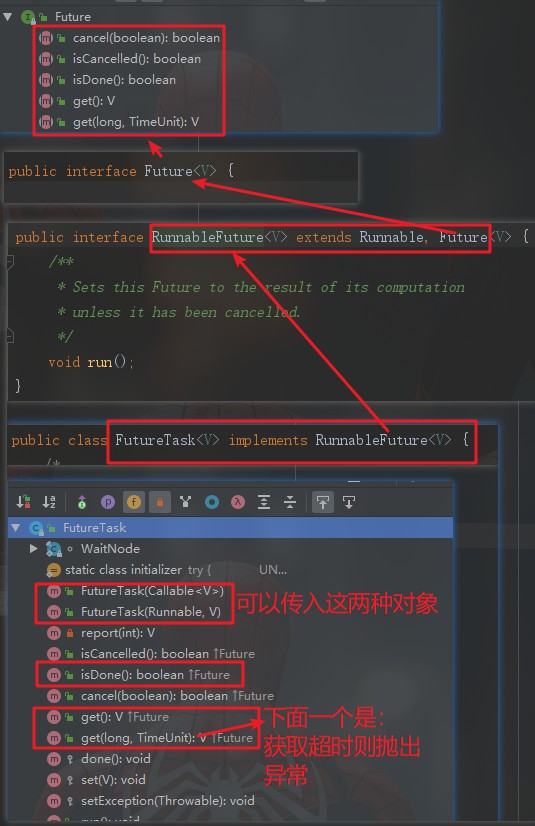
我们发现,FutureTask实质上都是Runnable接口的实例,只是它还是Futrue接口的实例,所以不仅可以作为一个线程任务被执行,还可以接受一个Callable接口去接受它的返回值。因此是一个升级版的Runnable实例。
说完了FutureTask的实现方式,下面再来看看另一种方式,即线程池来实现。关于线程池,后文还会详细介绍,这里只是简单先运用一下。
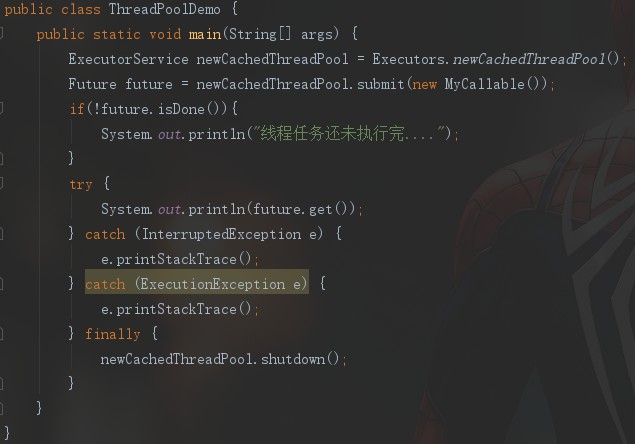
达到了一样的效果。我们来分析分析。
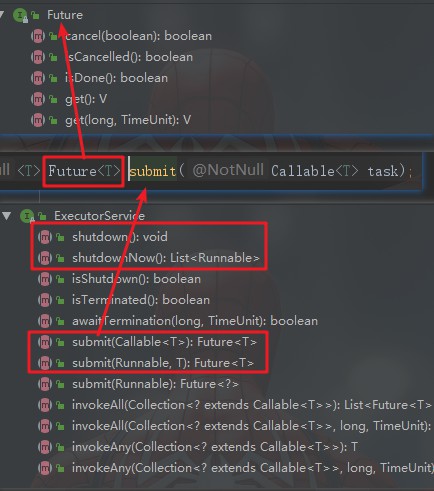
我们发现,其实两种方式的根本就是Future这个接口,第一种是直接用了FutureTask这个类来手动实现,即不仅需要它接收一个Callable任务,还需要将其作为一个线程任务去手动执行。而第二种方式就比较简单了,有了线程池,我直接把Callable任务扔线程池去submit,就可以得到一个可以获取返回值的Future类型对象,就可以根据这个对象获取到值了。
所以两种方式本质上是一样一样的。
下面补充一下关于Runnable和Callable两者的区别:
表面区别:
Runnable不返回任务执行结果,Callable可返回任务执行结果Callable在任务无法计算结果时抛出异常,而Runnable不能