
JUC组件拓展-BlockingQueue
在之前的线程池原理介绍中,我们了解到在核心线程被全部占用并且没有空闲线程的时候,就会把后续的线程任务先放入一个队列结构中,然后按照队列的方式去消化任务。虽然队列有很多种,但是他们都有一个共同的名字叫做阻塞队列,本文来逐个击破揭开他们的面纱。
一、BlockingQueue
在Java中,BlockingQueue是一个接口,它的实现类有ArrayBlockingQueue、DelayQueue、 LinkedBlockingDeque、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等,它们的区别主要体现在存储结构上或对元素操作上的不同,但是对于take与put操作的原理,却是类似的。
BlockingQueue 是一个先进先出的队列(Queue),为什么说是阻塞(Blocking)的呢?是因为 BlockingQueue 支持当获取队列元素但是队列为空时,会阻塞等待队列中有元素再返回;也支持添加元素时,如果队列已满,那么等到队列可以放入新元素时再放入。

add(anObject):把anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则抛出异常offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.- ⭐
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续. - ⭐与
put相对应的是take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止 poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null
BlockingQueue的各个实现都遵循了这些规则,当然我们也不用死记这个表格,知道有这么回事,然后写代码的时候根据自己的需要去看方法的注释来选取合适的方法即可。
一个
BlockingQueue可能是有界的,如果在插入的时候,发现队列满了,那么put操作将会阻塞。通常,在这里我们说的无界队列也不是说真正的无界,而是它的容量是Integer.MAX_VALUE(21亿多)。
BlockingQueue实现主要用于生产者-消费者队列,但它另外还支持Collection接口。因此,举例来说,使用remove(x)从队列中移除任意一个元素是有可能的。然而,这种操作通常不 会有效执行,只能有计划地偶尔使用,比如在取消排队信息时。
BlockingQueue的实现都是线程安全的,但是批量的集合操作如addAll,containsAll,retainAll和removeAll不一定是原子操作。如addAll(c)有可能在添加了一些元素后中途抛出异常,此时BlockingQueue中已经添加了部分元素,这个是允许的,取决于具体的实现。
下面来看看阻塞队列的各种具体的实现类。
二、ArrayBlockingQueue
- 构造函数必须带一个int参数来指明其大小
- 一个由数组结构组成的有界阻塞队列.
- 此队列按
FIFO(先进先出)原则对元素进行排序. - ⭐其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。
- ⭐如果队列为空,这个时候读操作的线程进入到读线程队列排队,等待写线程写入新的元素,然后唤醒读线程队列的第一个等待线程。
- ⭐如果队列已满,这个时候写操作的线程进入到写线程队列排队,等待读线程将队列元素移除腾出空间,然后唤醒写线程队列的第一个等待线程。
- 支持公平锁和非公平锁。公平的获取锁,也就是当前等待时间最长的线程先获取锁
三、LinkedBlockingQueue
- 大小不定的
BlockingQueue - 若其构造函数带一个规定大小的参数,生成的
BlockingQueue有大小限制 - 若不带大小参数,所生成的BlockingQueue的大小由
Integer.MAX_VALUE来决定 - 其所含的对象是以
FIFO(先入先出)顺序排序的 - ⭐链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低
- 最新插入的数据在尾部,最新移除的对象在头部
四、PriorityBlockingQueue
- ⭐类似于
LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序 - 一个无界的阻塞队列
五、SynchronousQueue
- ⭐它是一种阻塞队列,其中每个
put必须等待一个take,反之亦然。 - ⭐同步队列没有任何内部容量,甚至连一个队列的容量都没有。
- 它是线程安全的,是阻塞的。
- 不允许使用
null元素。 - 公平排序策略是指调用
put的线程之间,或take的线程之间。
一个没有容量的并发队列有什么用了?或者说存在的意义是什么?
尽管元素在SynchronousQueue 内部不会“停留”,但是并不意味着SynchronousQueue 内部没有队列。实际上SynchronousQueue 维护着线程队列,也就是插入线程或者移除线程在不同时存在的时候就会有线程队列。既然有队列,同样就有公平性和非公平性特性,公平性保证正在等待的插入线 程或者移除线程以FIFO的顺序传递资源。
它模拟的功能类似于生活中一手交钱一手交货这种情形,像那种货到付款或者先付款后发货模型不适合使用SynchronousQueue。首先要知道SynchronousQueue没有容纳元素的能力,即它的isEmpty()方法总是返回true,但是给人的感觉却像是只能容纳一个元素。
六、DelayQueue
DelayQueue对元素进行持有直到一个特定的延迟到期。注意其中的元素必须实现java.util.concurrent.Delayed接口。
七、生产者与消费者模式
阻塞队列的最常使用的例子就是生产者消费者模式,也是各种实现生产者消费者模式方式中首选的方式。使用者不用关心什么阻塞生产,什么时候阻塞消费,使用非常方便。
LinkedBlockingQueue来实现一个生产者与消费者模型:
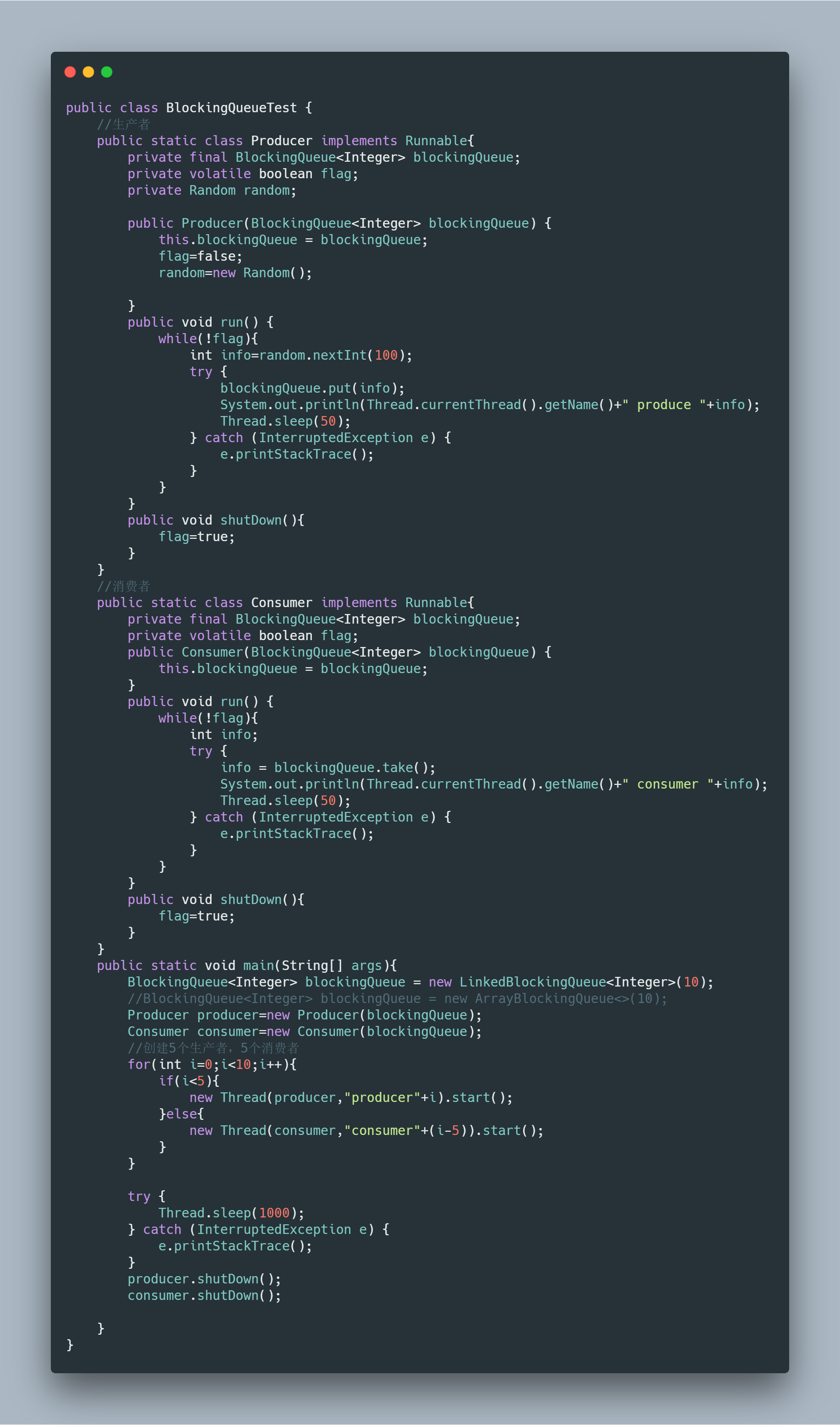
运行效果:
1 | producer1 produce 95 |
八、ArrayBlockingQueue和LinkedBlockingQueue的区别
- 队列中锁的实现不同
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;另外,可以指定是否为公平锁,默认是非公平锁。
LinkedBlockingQueue实现的队列中的锁是分离的,在队头和队尾各持有一把锁,入队和出队之间不存在竞争。即生产用的是putLock,消费是takeLock,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
- 在生产或消费时操作不同
ArrayBlockingQueue实现的队列中在生产和消费的时候,是直接将枚举对象插入或移除的;
LinkedBlockingQueue实现的队列中在生产和消费的时候,需要把枚举对象转换为Node<E>进行插入或移出(会生成一个额外的Node对象,这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。)
- 队列大小初始化方式不同
ArrayBlockingQueue实现的队列中必须指定队列的大小;
LinkedBlockingQueue实现的队列中可以不指定队列的大小,但是默认是Integer.MAX_VALUE
- 作为开发者,我们需要注意的是,如果构造一个
LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。 - 在使用
ArrayBlockingQueue和LinkedBlockingQueue分别对1000000个简单字符做入队操作时,LinkedBlockingQueue的消耗是ArrayBlockingQueue消耗的10倍左右,即LinkedBlockingQueue消耗在1500毫秒左右,而ArrayBlockingQueue只需150毫秒左右。 - 按照实现原理来分析,
ArrayBlockingQueue完全可以采用分离锁,从而实现生产者和消费者操作的完全并行运行。Doug Lea之所以没这样去做,也许是因为ArrayBlockingQueue的数据写入和获取操作已经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其在性能上完全占不到任何便宜。