
Zookeeper笔记8-典型应用场景详解
本章对于zk的应用场景和解决方案进行详细的介绍。
一、从应用程序的角度看ZooKeeper
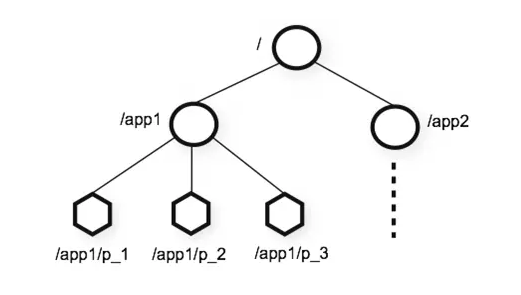
ZNode之间的层级关系就像文件系统的目录结构一样,但和传统的磁盘文件系统不同的是全量数据都存储在内存中,以此来实现提高服务器吞吐、减少延迟的目的,从这一点来说应用只应该存储控制信息和配置信息到ZNode,而不应该用它来存储大量数据。
ZNode可以分为持久节点和临时节点两类。持久节点是指一旦该ZNode被创建了,除非主动进行删除操作,这个节点就会一直存在;而临时节点的生命周期会和客户端会话绑定在一起,一旦客户端会话失效其所创建的所有临时节点都会被删除。
ZK还支持客户端创建节点时指定一个特殊的SEQUENTIAL属性,这个节点被创建的时候ZK会自动在其节点名后面追加上一个整形数字,该数字是一个由服务端维护的自增数字,以此实现创建名称自增的顺序节点。
二、监听器Watcher
Watcher是ZK中很重要的特性,ZK允许用户在指定节点上注册一些Watcher,在该节点相关特定事件(比如节点添加、删除、子节点变更等)发生时Watcher会监听到,ZK服务端会将事件通知到感兴趣的客户端上去,该机制是ZK实现分布式协调服务的重要特性。
通知的时候服务端只会告诉客户端一个简单的事件(通知状态、事件类型、节点路径)而不包含具体的变化信息(如原始数据及变更后的数据),客户端如要具体信息再次主动去重新获取数据;此外,无论是服务端还是客户端,只要Watcher被触发ZK就会将其删除,因此在Watcher的使用上需要反复注册,这样轻量的设计有效减轻了服务端压力,如果Watcher一直有效,节点更新频繁时服务端会不断向客户端发送通知,对网络及服务端性能影响会非常大。
三、典型应用场景
3.1 数据发布/订阅(以Dubbo注册中心为例)
Dubbo是阿里集团开源的分布式服务框架,致力于提供高性能和透明化的远程服务调用解决方案和基于服务框架展开的完整SOA服务治理方案。
其中服务自动发现是最核心的模块之一,该模块提供基于注册中心的目录服务,使服务消费方能够动态的查找服务提供方,让服务地址透明化,同时服务提供方可以平滑的对机器进行扩容和缩容,其注册中心可以基于提供的外部接口来实现各种不同类型的注册中心,例如数据库、ZK和Redis等。接下来看一下基于ZK实现的Dubbo注册中心。
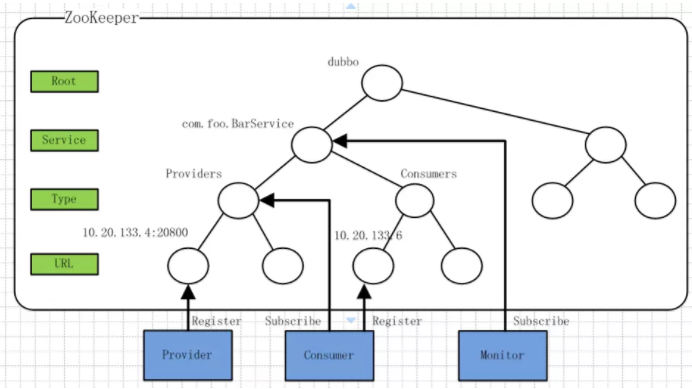
/dubbo: 这是Dubbo在ZK上创建的根节点。/dubbo/com.foo.BarService: 这是服务节点,代表了Dubbo的一个服务。/dubbo/com.foo.BarService/Providers: 这是服务提供者的根节点,其子节点代表了每个服务的真正提供者。/dubbo/com.foo.BarService/Consumers: 这是服务消费者的根节点,其子节点代表了没一个服务的真正消费者- Dubbo基于ZK实现注册中心的工作流程:
- 服务提供者:在初始化启动的时候首先在
/dubbo/com.foo.BarService/Providers节点下创建一个子节点,同时写入自己的url地址,代表这个服务的一个提供者。 - 服务消费者:在启动的时候读取并订阅ZooKeeper上
/dubbo/com.foo.BarService/Providers节点下的所有子节点,并解析所有提供者的url地址类作为该服务的地址列表,开始发起正常调用。同时在Consumers节点下创建一个临时节点,写入自己的url地址,代表自己是BarService的一个消费者 - 监控中心:监控中心是Dubbo服务治理体系的重要一部分,它需要知道一个服务的所有提供者和订阅者及变化情况。监控中心在启动的时候会通过ZK的
/dubbo/com.foo.BarService节点来获取所有提供者和消费者的url地址,并注册Watcher来监听其子节点变化情况
- 服务提供者:在初始化启动的时候首先在
所有服务提供者在ZK上创建的节点都是临时节点,利用的是临时节点的生命周期和客户端会话绑定的特性,一旦提供者机器挂掉无法对外提供服务时该临时节点就会从ZK上摘除,这样服务消费者和监控中心都能感知到服务提供者的变化。
3.2 命名服务
命名服务也是分布式系统中比较常见的一类场景,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象,其中较为常见的是一些分布式服务框架中的服务地址列表,通过使用命名服务客户端应用能够指定名字来获取资源的实体、服务地址和提供者的信息等。
3.3 Master选举
当前系统的mater节点挂了怎么办?那就要重新选出一个master来。
ZK创建节点时有一个重要的特性,利用ZK的强一致性能够很好的保证在分布式高并发情况下节点的创建一定能够保证全局唯一,即ZK会保证客户端无法重复创建一个已经存在的数据节点。也就是说同时有多个客户端请求创建同一个节点最终一定只有一个客户端能够请求创建成功,利用这个特性就能很容易的在分布式环境中进行Master选举了。
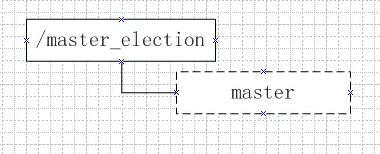
进行Master选举时客户端启动后可以向ZK请求创建一个临时节点,例如/master_election/master。在多个客户端创建时只有一个能创建成功,那么这个创建成功的客户端所在的机器就成为了Master。
同时其他没有创建成功的客户端都可以在节点/master_election上注册一个子节点变更的Watcher来监控当前Master是否在线,一旦发现Master挂了临时节点会被删除,其它客户端会收到通知,开始重新进行Master选举。
3.4 分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。如果不同系统或同一系统不同机器之间共享了同一资源,那访问这些资源时通常需要一些互斥手段来保证一致性,这种情况下就需要用到分布式锁了。
接下来看下使用ZK如何实现排他锁。排他锁的核心是如何保证当前有且只有一个事务获得锁,并且锁被释放后所有等待获取锁的事务能够被通知到。
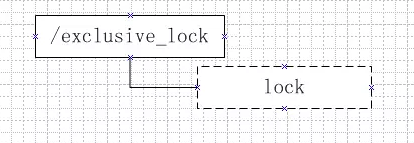
和Master选举类似,在需要获取排他锁时,所有客户端都会试图在/exclusive_lock下创建临时子节点/exclusive_lock/lock,最终只有一个客户端能创建成功,该客户端就获取到了锁。
同时没有获取到锁的客户端需要到/exclusive_lock节点上注册一个子节点变更的Watcher监听,用于实时监听lock节点的变更情况。
/exclusive_lock/lock是一个临时节点,在一下两种情况下都有可能释放锁:
- 当获取锁的客户端挂掉,ZK上的该节点会被删除
- 正常执行完业务逻辑之后客户端会主动将自己创建的临时节点删除。
无论在什么情况下删除了lock临时节点ZK都会通知在/exclusive_lock节点上注册了子节点变更Watcher监听的客户端,重新发起锁的获取。
3.5 分布式屏障
分布式屏障,举个栗子,在大规模分布式并行计算的场景下,最终的合并计算需要基于很多并行计算的子结果来进行,即系统需要满足特定的条件,一个队列的元素必须都聚齐之后才能进行后续处理,否则一直等待。看下如何用ZK来支持这种场景。
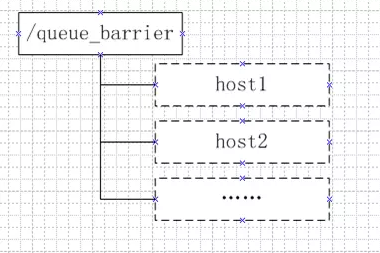
开始时/queue_barrier是一个存在的节点,数据内容赋值为一个数字n来代表满足条件的机器总数,例如n=10表示只有当/queue_barrier节点下的子节点数量达到10后才会打开屏障继续处理。
然后所有的客户端都会到/queue_barrier节点下创建一个临时节点,如/queue_barrier/192.168.0.1。创建完节点之后根据以下步骤来确定执行顺序:
- 1、调用获取节点数据的api获取
/queue_barrier节点的内容:10 - 2、调用获取子节点总数的api获取
/queue_barrier下的所有子节点,并且注册对子节点变更的Watcher监听 - 3、统计子节点个数
- 4、如果子节点个数小于10则继续等待,否则打开屏障继续处理
- 5、接收到Watcher通知后,重复步骤2