
基础算法2-汉诺塔问题
为什么还要再来说说递归问题,因为数据结构中二叉树是比较重要也是比较难的数据结构,它的结构是天生递归的,所以对于二叉树的很多操作都可以用递归来实现,因此递归这一关能尽量理解是最好的,本章从汉诺塔的问题出发,来看看递归的实现原理。
汉诺塔问题
这个问题估计大多数人都是知道的,汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具。大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘。大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上。并且规定,在小圆盘上不能放大圆盘,在三根柱子之间一次只能移动一个圆盘。
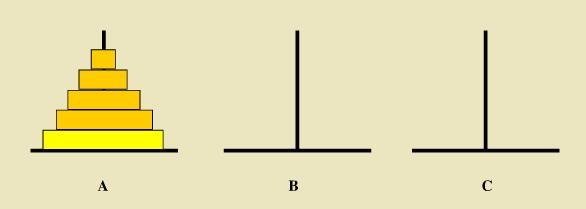
抽象为数学问题:如下图所示,从左到右有A、B、C三根柱子,其中A柱子上面有从小叠到大的n个圆盘,现要求将A柱子上的圆盘移到C柱子上去,期间只有一个原则:一次只能移到一个盘子且大盘子不能在小盘子上面,求移动的步骤和移动的次数。
其实核心的思想已经在上篇文章中说明了,就是数学归纳法的思想,就拿简单又不失一般性的三个盘子先说事。

其实我们发现,最核心的一个状态就是:
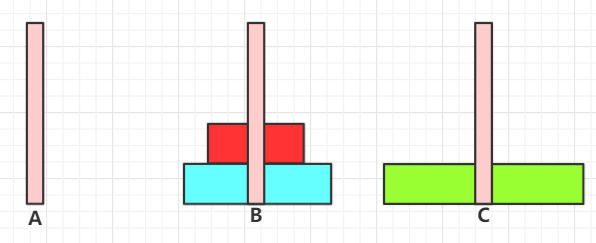
就是说,我们已经有了中间B这个符合条件的2个盘子的情况,那么我只需要将这两个想办法将这B上两个盘子放到C上就结束了。
同理,更多的盘子n,我就是想办法将n-1个符合条件的盘子放到第n个盘子上不就可以了。大概的思想如下:
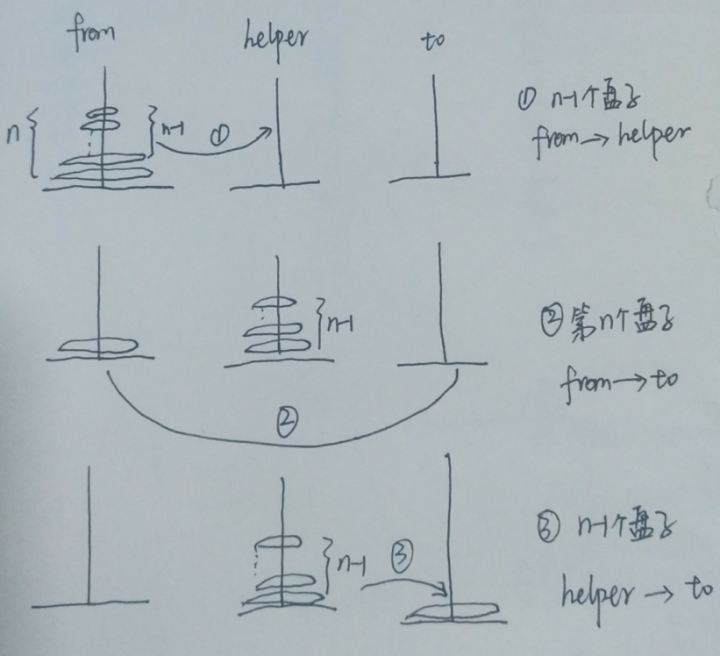
OK,下面展示程序:
1 | static void hanoi(int n,char A,char B,char C){ |
先拿2测试一下:
1 | public static void main(String[] args) { |
结果为:
1 | A -> B |
是符合我们的预期的。并且尝试更多的时候,按照它一步一步是正确的。
如果理解了上面说的,那么这个程序是非常好理解的。但是真正想深入进递归里面,一旦多起来还是比较复杂的。其实我们可以这样理解:
一个小朋友坐在第10排,他的作业本被小组长扔到了第1排,小朋友要拿回他的作业本,可以怎么办?他可以拍拍第9排小朋友,说:“帮我拿第1排的本子”,而第9排的小朋友可以拍拍第8排小朋友,说:“帮我拿第1排的本子”…如此下去,消息终于传到了第1排小朋友那里,于是他把本子递给第2排,第2排又递给第3排…终于,本子到手啦!这就是递归,拍拍小朋友的背可以类比函数调用,而小朋友们都记得要传消息、送本子,是因为他们有记忆力,这可以类比栈。
更严谨一些,递归蕴含的思想其实是数学归纳法:为了求解问题p(n),首先解决基础情形p(1),然后假定p(n-1)已经解决,在此基础上若p(n)得解,那所有问题均得解。这也启发我们:使用递归,切忌纠结中间步骤,因为这样做的代价是手动推理中间的若干步骤,而这些脏活,应该是计算机给我们干的!
所以理解递归还是不能太纠结具体的过程,这样只会更加地糊涂,我们注重的应该是思想以及写递归的一些注意事项,比如对于参数的确定,停止条件以及每次都要缩小范围并且都是以1这个段位缩小,不要跨段不要跨段。
递归与栈
虽然说我们不能纠结于递归的过程,但是递归与栈关系紧密,区别只是这个栈是计算机系统栈帮我们实现,而迭代是我们自己控制栈来实现,两者的基本思想都是栈,那么我们就来探讨探讨递归与栈。这个问题也是我之前面试被问过的一个问题,希望再这里能有个比较清晰的理解。
前面说过,树是一个天然递归的数据结构,这里拿二叉树的前序遍历作为分析点,并且拿最简单的三个节点的二叉树作为示例。
对于树这个数据结构暂且不多说,我们如果用递归的方式来实现前序遍历还是非常简单的。
1 | /** |
这个直接放到leetcode上竟然也是可以通过的,说明对这个递归答案还是认可的。不过这里想说明一下递归与栈的关系,所以需要详细说明一下它里面是如何通过系统栈来进行调用的。(前序遍历:144号,中序遍历84号,后序遍历145号)。
当然了,我们也知道递归相当于一个函数调用另一个子函数,它是自己再调用自己而已,递归借助了系统栈自己来实现的。我们这里以遍历最简单的二叉树为例:
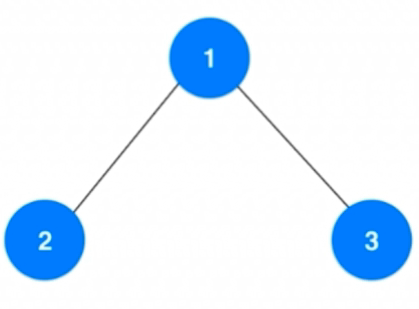
当执行到第一个preorder的时候,此时系统栈里面已经标志一下前面两句执行完毕,还剩下遍历右孩子的操作。此时就是已经遍历了1这个节点,下面就是准备进入1的左孩子即2这个节点的遍历。
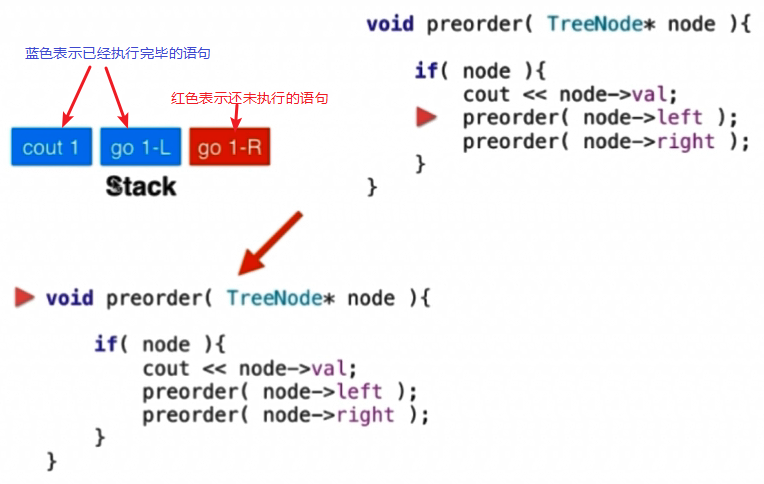
此时进入递归重新执行preorder,那么此时又将这个重新执行的函数的参数压到栈顶:
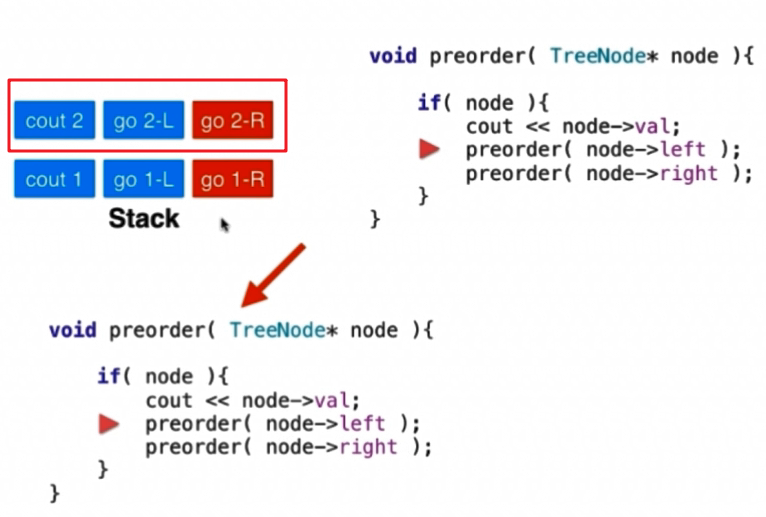
此时2这个节点已经打印出来了,此时又要进入preorder重新执行了,再将2的左孩子放进preorder进行遍历,此时为null,那么就会直接结束preorder函数,返回来继续执行,此时go 2-R还没有执行,那么就是看看2的右孩子,也是null,那么此时关于2的节点的孩子们都遍历完毕了,就会出栈,回到一开始继续执行go 1-R。同理再去遍历1的右孩子们。
我们从上面的过程中知道,系统栈会保留递归调用的时候调用方的参数以及执行情况,等递归返回的时候,就可以将现场恢复并且继续执行。我们还明确,比如对于节点1来说,系统栈的处理方式是:先count 1即打印1,然后递归访问左孩子go 1-L,最后递归访问右孩子go 1-R,那么我们也可以用栈来模拟这个过程,那么压栈的过程必然是go 1-R–go 1-L–count 1,这样根据后进先出的原则,出来的顺序正好是count 1–go 1-L–go 1-R。
根据这个思路,我们完全可以将上面的递归程序改成用栈来实现。
首先将root入栈,并且标识为go,下面进入循环判断栈是否为空,不为空则进入循环。
首先是判断如果当前节点为go,则表示进行入栈操作,这里首先演示的是前序遍历,所以入栈的顺序是右孩子(go 1-R)–左孩子(go 1-L)–自身(print 1),此时栈中已经有了这三个信息,那么进入下一次循环,首先出栈的就是自身(print 1),那么则打印,继续循环,此时出栈的是左孩子(go 1-L),因为是go所以要添加左右孩子,但是它没有左右孩子,则直接将print 2压入栈中,那么下次循环就会打印出来。最后同理就是右孩子出栈,跟2一样没有左右子孩子则直接将print 3压入栈中下次循环打印出来。代码如下:
1 | /** |
有的小伙伴可能会发现这个写法好像跟主流的写法不大一样,后面介绍二叉树的话会介绍一下主流的写法是什么,但是这个写法是比较通用的。原因在于这个写法是真正模拟了系统栈的执行流程,思路会比较清晰一点,并且它具有通用性,如果我想改为中序遍历或者后续遍历是非常简单的,只需要简单地调整if (command.str.equals("go"))里面的顺序即可。
至此,简单地昭示了系统栈的执行流程,阐明了递归与栈之间的关系,并且用自己的栈来模拟系统栈写出了非递归的版本。递归在树这种数据结构中是随处可见的,应该对它重视起来。