
01-初识Hadoop
关于大数据的学习终于开始了,对java后台开发比较熟悉的同学会发现,部分的组件比如zookeeper就是从Hadoop生态圈中诞生的,但是纵观hadoop的生态圈,大多数还是比较陌生,本节来说一说比较核心的组件,找到学习的入口。
一、概述
我们来到它的官网来看看Hadoop到底是什么。

大概就是说:Haadoop项目旨在发展可靠的、可扩展的、分布式计算的开源软件。允许用简单的编程跨越集群来分布式处理大数据集。可以从单体服务扩展到上千台机器,每个机器都可以提供本地计算和存储。相比于依赖硬件来保证高可用,Hadoop是在应用层监测和处理错误从而保证可靠性,允许单个机器出现故障。
可以看到,Hadoop旨在提供高可用、可扩展、分布式计算一种能力,是应对海量数据的存储以及处理的一个方案。
这个Hadoop project包含了几个核心的子模块:
- Hadoop Common: 为其他的模块提供基础支持。
- Hadoop Distributed File System (HDFS™): 一个高吞吐量的分布式文件系统
- Hadoop YARN: 一个作业调度和集群资源管理的框架
- Hadoop MapReduce: 基于YARN实线的用于并行处理大数据集的系统
二、核心组件之HDFS
- 源自于谷歌的GFS论文,论文发表于2003年10月
- HDFS是GFS的克隆版
- HDFS特点:扩展性&容错性&海量数据存储
HDFS是一种分布式文件系统,文件系统是什么,我们需要知道他的基本功能是:管理和调度文件的存储空间,提供文件的逻辑结构、物理结构和存储方法;实现文件从标识到实际地址的映射。也就是对文件进行管理和调度的。
海量的数据,我们需要良好的扩展性来存放,也需要容错性来防止数据丢失,因此HDFS是在文件系统基本要求的基础上,实现更可靠的存储。
这里简单说一下的它的容错性是如何做到的:将文件切分为指定带线啊哦的数据块并以多副本的方式存储在多个机器上,而数据切分、多副本、容错等操作对用户是透明的。
三、核心组件之资源调度系统YARN
- 负责整个集群资源的管理和调度:比如有一个作业要提交上来执行,需要占用多少CPU,多少内存都是YARN来计算完成的。
- 具有扩展性&容错性&多框架资源统一调度
这里注意,YARN可以为上层应用提供统一的资源管理和调度,是什么意思呢?
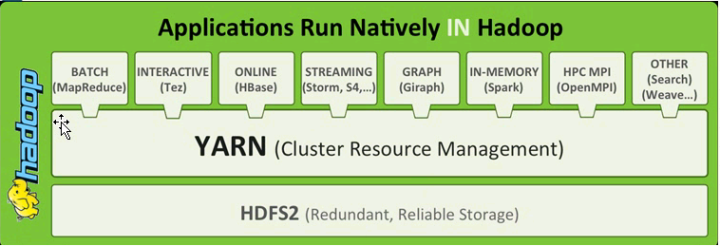
这张图从下面开始,HDFS2其实就是表示hadoop2.x,他是做存储的,往上看有一个YARN,他就是做集群的资源管理的(cluster resource management),再往上看,对于批处理我们可以用mapreduce这种执行引擎,对于交互式的我们可以使用tez,在线的我们可以使用hbase,流处理可以采用storm,图计算用giraph,内存式的计算我们可以使用spark。。。。。
有了YARN之后就可以执行不同类型的计算框架,我们可以把YARN理解为操作系统级别的资源调度框架,可以让更多的计算框架mapreduce,spark,storm等等都运行在同一个集群里面,而且不同的计算框架可以共享同一个hdfs上的数据,享受整体的资源调度。
四、核心组件之分布式计算框架MapReduce
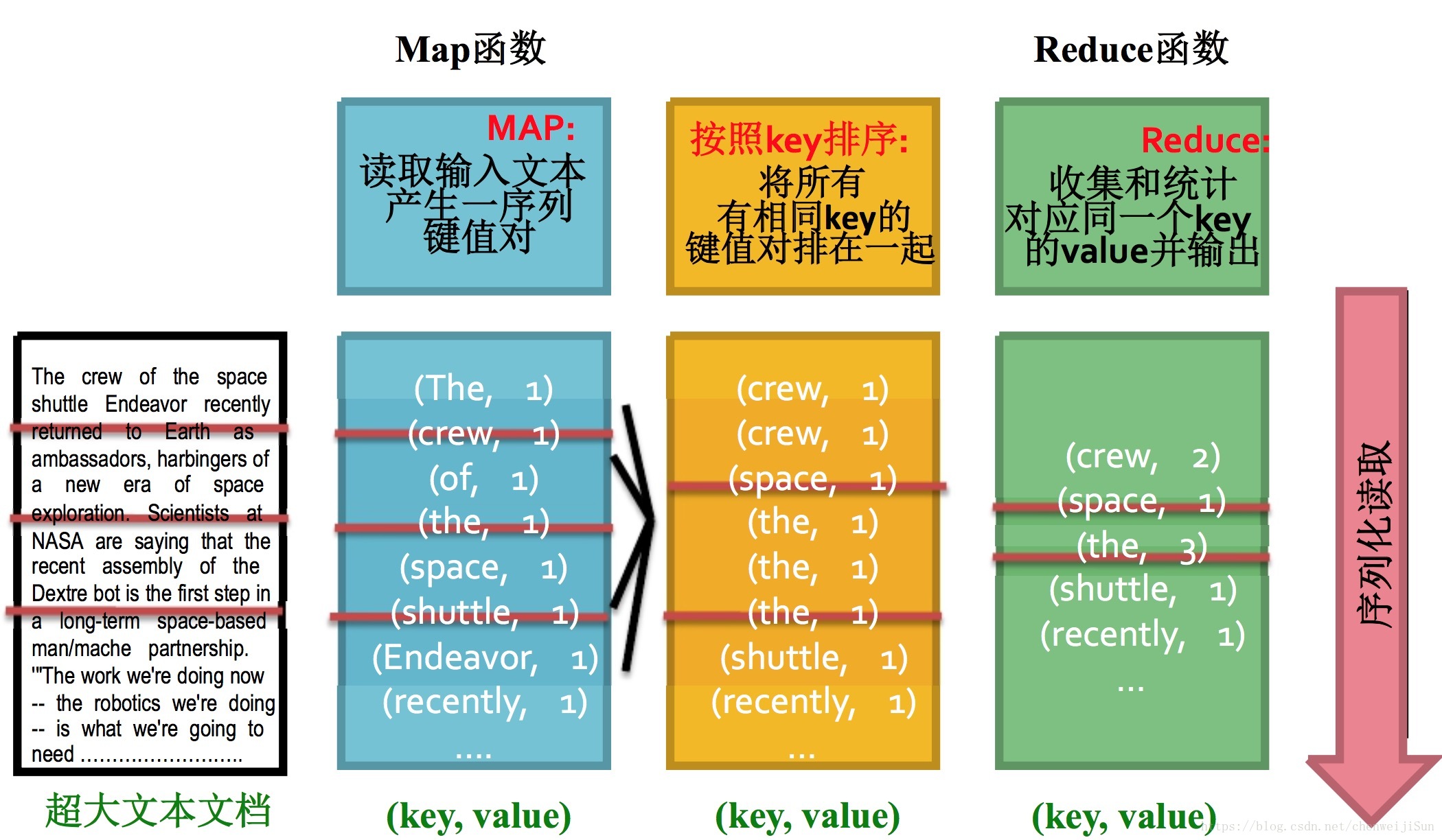
也是根据谷歌的论文实线的。不再赘述。下面我们来看看它是如何简单地统计单词出现频率的:
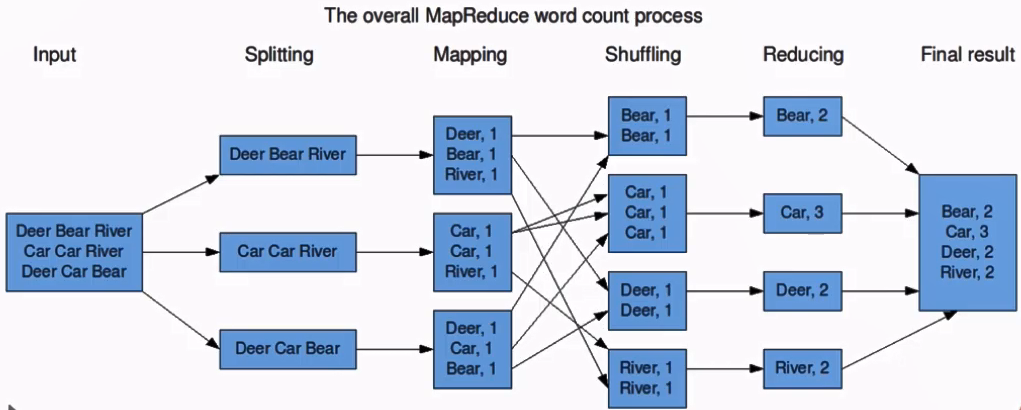
这是比较经典的一个案例。
大概是分成下面几个环节:
- Map阶段
- 主要完成
key-value对生成,这里是每看到一个单词,就输出(单词,1)的kv对
- 主要完成
- 排序阶段
- 对刚才的kv对进行排序,这样相同单词就在一块儿了
- Reduce阶段
- 对同一个单词的次数进行汇总,得到(词,频次)对
五、Hadoop优势
- 高可用性:
- 数据存储:数据块多副本
- 数据计算:发生异常的时候会重新调度作业计算
- 高扩展性
- 可以横向增加机器
- 其他
- 可以存储在廉价机器上,降低成本
- 成熟的生态圈
六、狭义Hadoop和广义Hadoop
狭义上的Hadoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台。
广义上的Hadoop:指的是Hadoop生态系统。我们要知道,完成一些任务仅靠上面几个是不够的,比如MapReduce只能做离线批处理,要想做实时计算时无法完成的,所以需要其他的软件来完成。Hadoop生态系统是一个很庞大的概念,Hadoop是其中最重要最基础的一个部分;生态系统中的每一个子系统只解决某一个特定的问题域,不搞统一型的一个全能系统,而实小而精的多个小系统。
七、Hadoop生态圈介绍
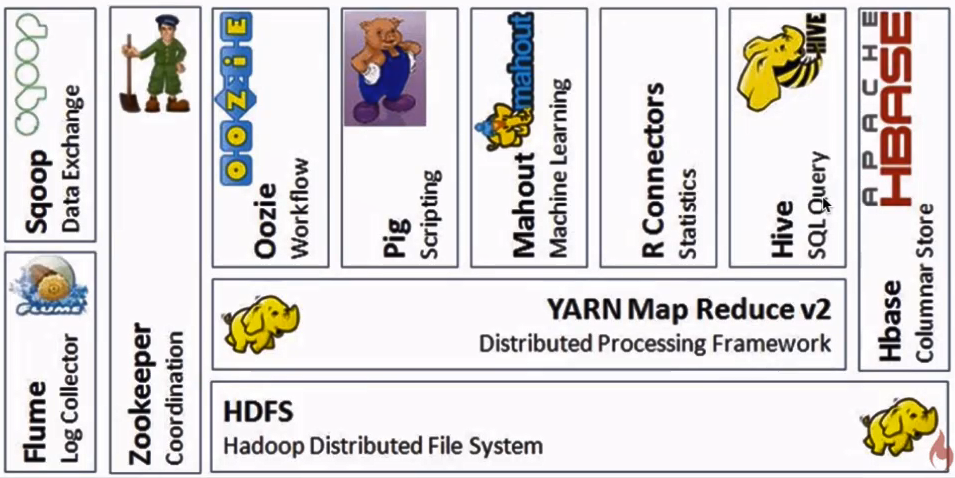
我们从图中可以大概知道每个组件的用途。下面我们来简单说一说。
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。
Hive与Hbase的数据一般都存储在HDFS上。hadoop HDFS为他们提供了高可靠性的底层存储支持。
hive不支持更改数据的操作,Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
Pig的语言层包括一个叫做PigLatin的文本语言,Pig Latin是面向数据流的编程方式。Pig和Hive类似更侧重于数据的查询和分析,底层都是转化成MapReduce程序运行。
Pig和Hive的区别是Hive是类SQL的查询语言,要求数据存储于表中,而Pig是面向数据流的一个程序语言。
总结:
Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制(zookeeper = 通知机制 + 文件系统)。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。
八、选型
- Apache Hadoop
- CDH:Cloudera Distributed Hadoop
- HDP:Hortonworks Data Platform
优先选择CDH,比较全,解决了版本冲突问题。
九、总结
我们可以看到,Hadoop的生态圈是极其庞大的,每个组件都是小而精,是为了解决特定问题而产生的,因此需要具体情况具体分析选用什么组件,也需要对核心的组件原理和使用了如指掌,下面我们先逐个来学习一下狭义Hadoop核心组件,从HDFS开始。