
05-交易工程(上)
一、前言
回顾一下之前的内容,在单体应用中,我们可以用select .. for update,这样子可以在这个事务内锁定这一行数据,避免了并发问题。还可以用唯一约束来限制。对于分布式应用,必须要由一个全局锁来控制,比如ZK来实现的分布式锁。
对于分表之后,如何保证ID的不重复呢?一般我们可能会想到用UUID来实现嘛。但是UUID一般可以获取当前时间的毫秒数再加点随机数,但是在高并发下仍然可能重复。最重要的是,如果我要用这种UUID来生成分表的唯一ID的话,重复不谈,这种随机的字符串对于我们的innodb存储引擎的插入效率是很低的。所以我们生成的ID如果作为主键,最好有两种特性:分布式唯一和有序。
唯一性就不用说了,有序保证了对索引字段的插入的高效性。我们来具体看看ShardingJDBC的分布式ID生成策略是如何保证。
二、ShardingJDBC的分布式ID生成策略
snowflake算法

sharding-jdbc的分布式ID采用twitter开源的snowflake算法,不需要依赖任何第三方组件,这样其扩展性和维护性得到最大的简化;但是snowflake算法的缺陷(强依赖时间,如果时钟回拨,就会生成重复的ID)。
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如MySQL的Innodb存储引擎的主键。
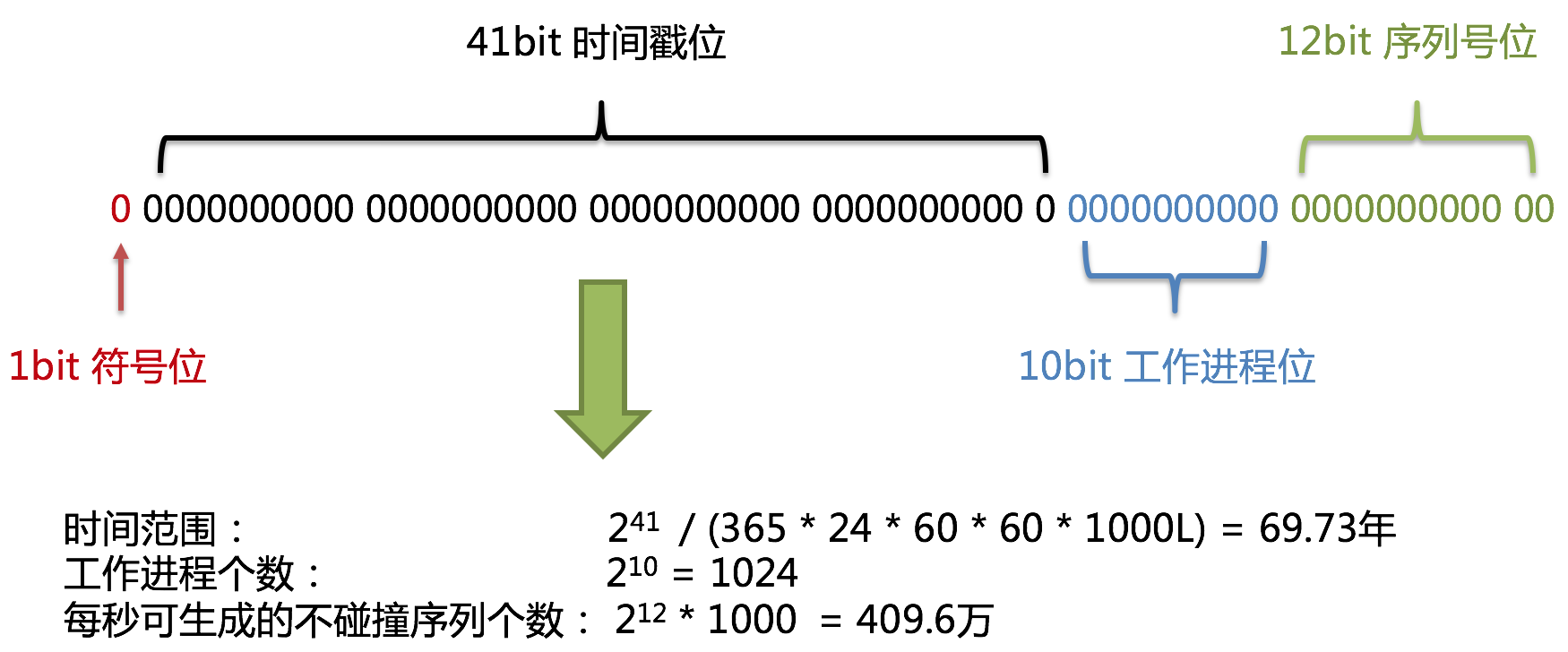
使用雪花算法生成的主键,二进制表示形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
- 符号位(1bit)
预留的符号位,恒为零。
- 时间戳位(41bit)
41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:
1 | Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); |
结果约等于69.73年。ShardingSphere的雪花算法的时间纪元从2016年11月1日零点开始,可以使用到2086年,相信能满足绝大部分系统的要求。
- 工作进程位(10bit)
该标志在Java进程内是唯一的,如果是分布式应用部署应保证每个工作进程的id是不同的。该值默认为0,可通过调用静态方法DefaultKeyGenerator.setWorkerId()设置。
- 序列号位(12bit)
该序列是用来在同一个毫秒内生成不同的ID。如果在这个毫秒内生成的数量超过4096(2的12次幂),那么生成器会等待到下个毫秒继续生成。
时钟回拨
服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。 如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为0,可通过调用静态方法DefaultKeyGenerator.setMaxTolerateTimeDifferenceMilliseconds()设置。
雪花算法主键的详细结构见下图。
三、ES
对于商品搜索这种功能,为什么要用ES呢?
在数据库中可以用%这种模糊搜索,比如我要搜世界你好,那么我们可能可以这样:like '%世界%'来进行模糊搜索。但是如果我要搜世好咋办呢?另一方面,不能走索引,并且全表扫描,数据量大的时候就凉了。
ES基本原理是实现了一个分词匹配器,比如一句话叫你好世界,我是JAVA,它可能会将其分解为你好,世界,我是,JAVA这几个词,然后根据你输入的关键字来一一匹配,按照匹配度的高低排个序展示出来。
下面具体的安装下节再说。
四、核心-商品表设计
我们先来看看华为官网手机详情,比如我们看看HUAWEI Mate 20这一款(此处非广告…还没用过华为手机):
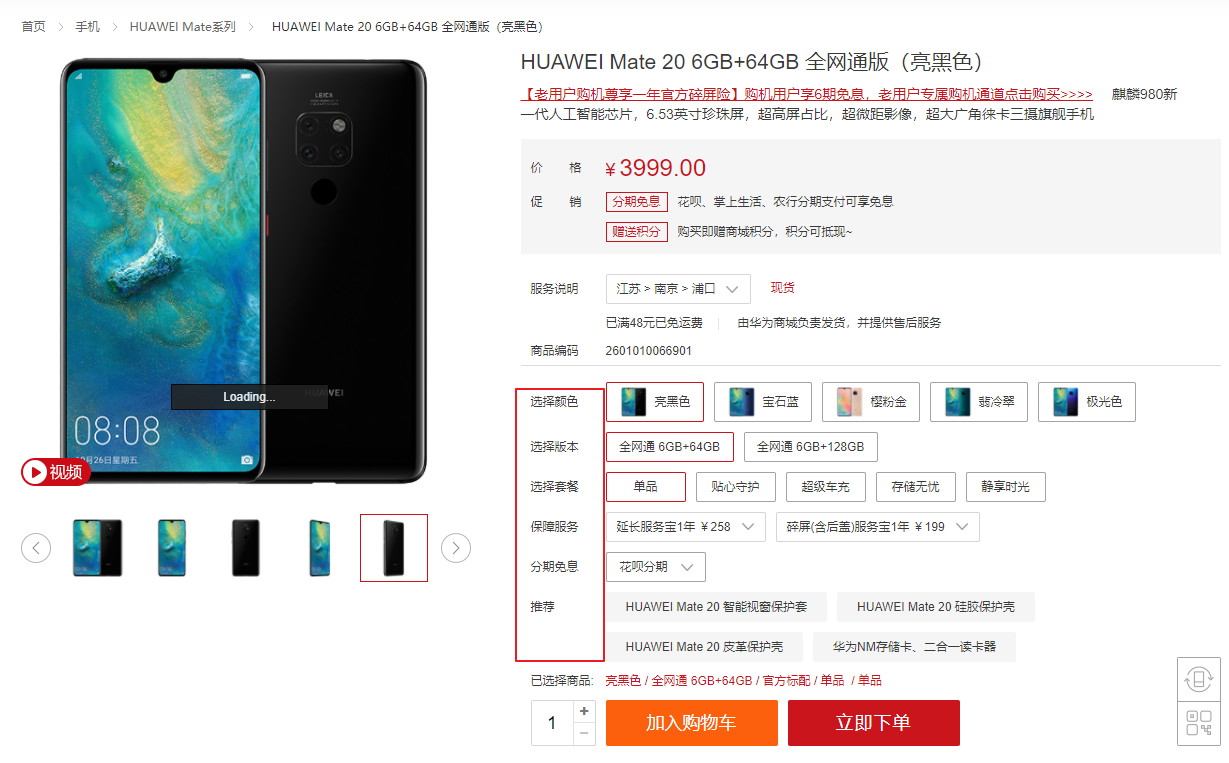
这是一个真正的页面详情,主要的特点是针对不同的颜色、版本、套餐等条件会动态地改变价格。也就是说一组独立的属性决定了一个库存。这就是SKU(最小库存单位)。其实是非常复杂的,这里的手机算是比较简单的。
那么如何设计呢?
从页面上看,这个SKU有个名字:“HUAWEI Mate 20 6GB+64GB 全网通版(亮黑色)”,下面是若干属性。
首先整体来看一下交易数据库有几张表:

我们分解来看,从简单到复杂。首先是t_brand,t_category和t_product这三张表,分别是品牌,可能有华为,也可能有小米等等。现在假设就只有华为这一个牌子,下面有几种分类,我们可以看页面:
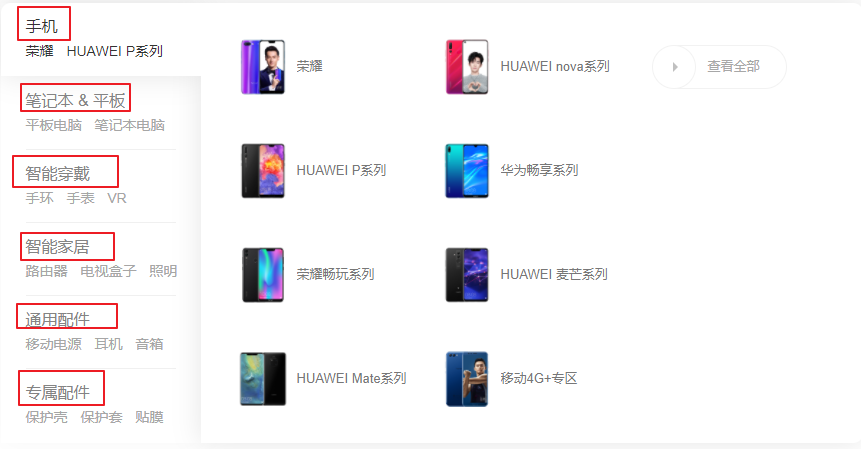
我们看到,有手机、笔记本、智能家居等几种分类。每种分类下面有好几种子分类,比如这里的荣耀、P系列、Mate系列等分类。
对于t_brand,十分简单,表设计如图:

对于t_category也简单,简单来说就是用一个parent_id来实现递归的自相关:
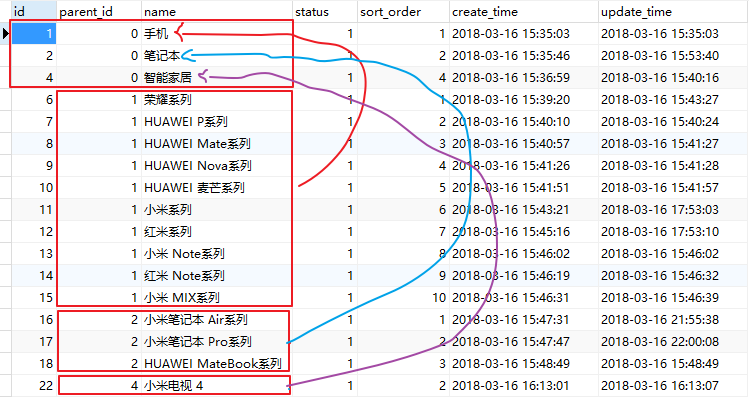
t_category和t_product的关联就简单啦,就是一对多的关系嘛!
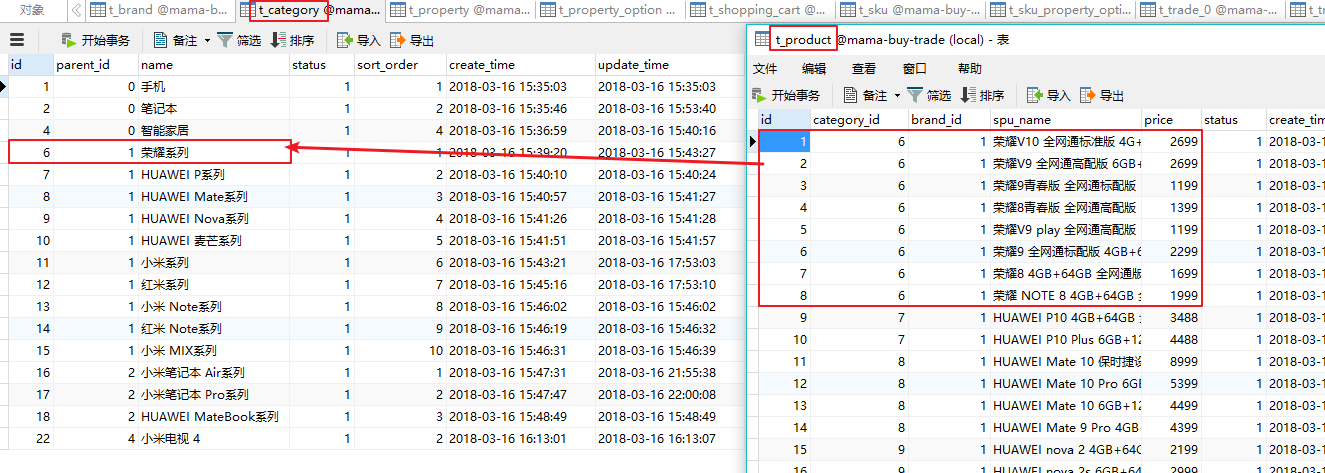
下面是比较麻烦一点的是属性,t_property是与t_category挂钩的,这样设计的原因是,在后台配置的时候,选完分类,比如这里的荣耀系列之后,我就可以配置对应的属性:颜色、容量、制式、套餐和定制这五种属性了。t_property与t_property_option就是一对多的关系了,比如颜色有沙滩金、极光蓝、幻夜黑以及魅力红。
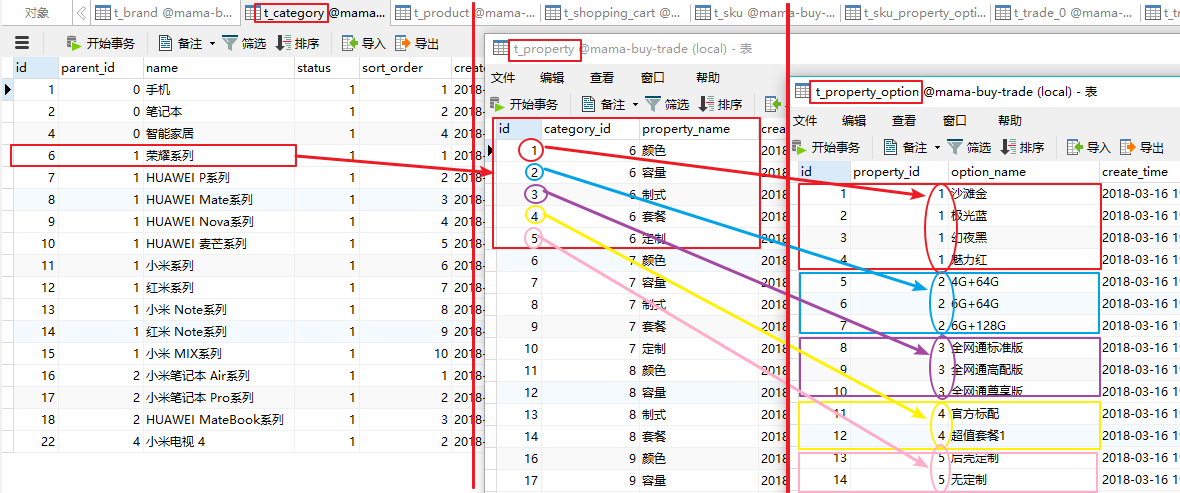
ok,下面就是设计SKU了,简单来说,就是每种产品对应的版本,我们再看一眼第一幅图:
我们可以看到,首先这是一款具体的产品,然后呢,每款产品下有产品的名字、产品对应于各种不同的属性而显示不同的价格。
我们思考一下,我们已经拥有了t_product,t_property,t_property_option这三张表。其实,我们的页面,就是说SKU,其实就是这三张表的再组合。
首先一个产品,比如荣耀V10这一款产品,我首先有一个总的SKU来说明这个产品,我只需要一个简单的信息,比如sku_name和sku_price即可,因为我这款手机有很多的配置选项可以选择,那么就需要一张t_sku_option这张表来承载,就是sku_id,property_id和property_option_id这三者的结合,后面我们根据这三者才能真正的到库存系统去削减库存,然后下单。
比如我买的是荣耀V10 6G+128G 幻夜黑 官方标配 全网通 这一款,那么我对应到t_sku表的是第7条记录,对应到t_sku_option表的是有下面几条记录:
- 7 1 3 表示: skuID=7,颜色为幻夜黑
- 7 2 7 表示:skuID=7,容量为6G+128G
- 7 3 8 表示:skuID=7,全网通标配版
- 7 4 11 表示:skuID=7,官方标配
- …
Ok,这样我就真正选择了一个具体的手机款式,后面就可以根据这些属性去扣减库存,下订单啦!
注1:下面这张图有个错误,就是下面个绿的箭头指向的应该是t_sku的第一行id=1的记录,懒得改了。
注2:上面举的例子与下面的数据库中数据是一致的,可以对比看一下。
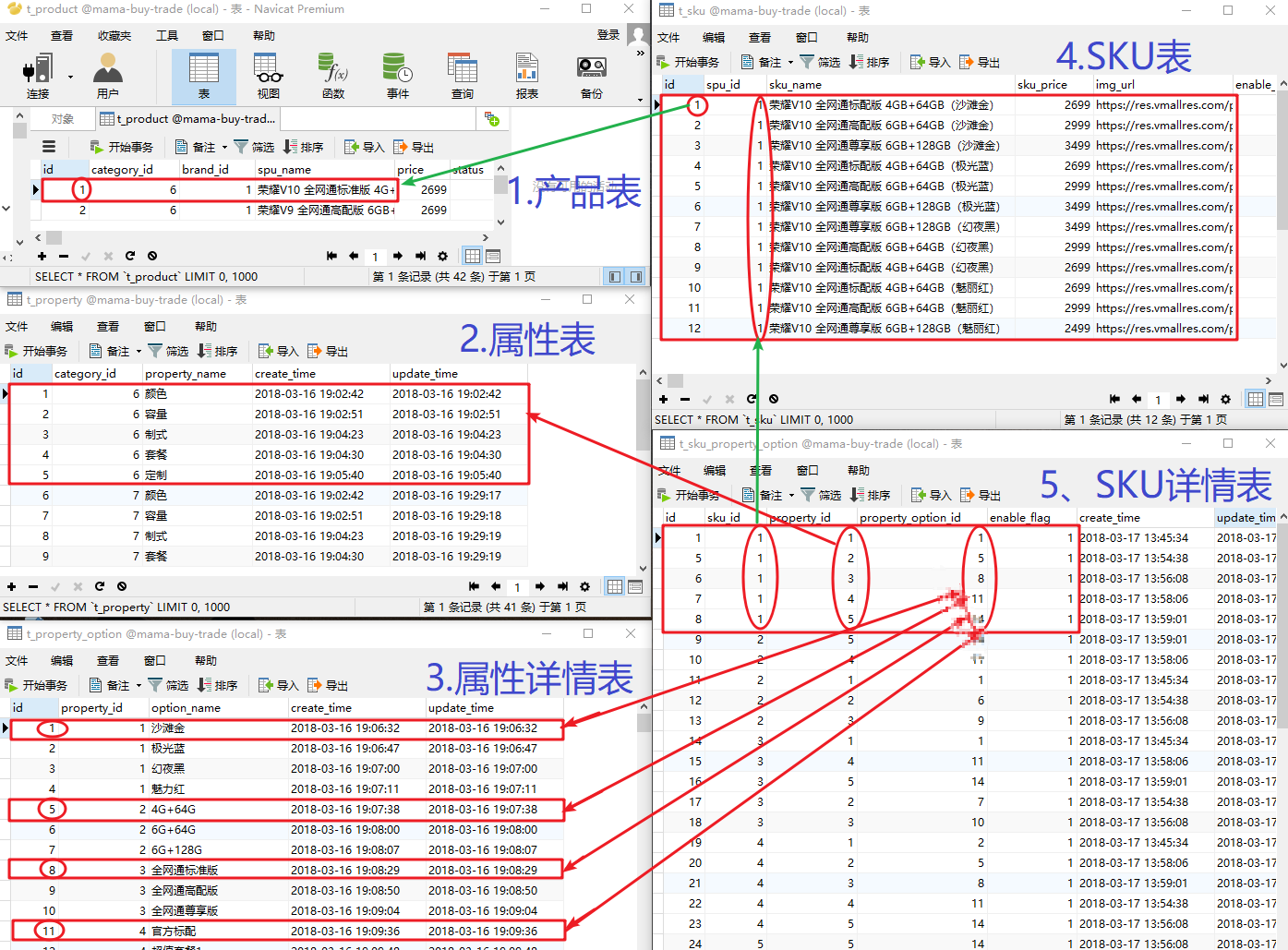
这样,就完成了比较简单的产品表的设计了。