
01kafka入门

本系列博客主要以《深入理解kafka核心设计和实践原理》和《kafka权威指南》这两本书为基础深入学习kafka的使用和原理。
我们或多或少都听说过kafka,为了深入学习一下kafka,本文作为学习的第一篇文章,主要目标是搞清楚kafka的基本概念,因为kafka涉及一些专用名词,只有先了解这些名词,才有可能理解kafka的设计思想。
一、为什么要学习kafka
目前,kafka的定位是一个分布式流处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。截止到写本文的时间:2019年08月21号,已经到了2.3版本,kafka也成为后端程序猿或者大数据程序猿不可不学习的一个重要中间件。它有三大特点:
- 消息系统
市面上有很多的消息中间件,这些消息中间件的主要功能是:系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复等功能。但是kafka不仅包含这些内容,还提供大多数消息中间件不能实现的:消息顺序性保障和回溯消费等功能。
- 存储系统
Kafka支持消息的持久化,相比于其他内存存储系统有较高的保障性,并且提供多副本机制,避免某一台服务器挂掉而导致消息丢失。并且支持长期的数据存储,只需要将数据保存策略设置为永久或者启用主题的日志压缩功能即可。
- 流式处理平台
kafka的定位日渐提高,它不是仅仅可以作为消息中间件,它的目标实际是为流式处理框架提供可靠的数据来源。还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
以上就是kafka与其他的消息中间件的区别(优势),下面来一起入门kafka的基本概念吧。
二、kafka基本概念
入门一个新的知识,首先需要知道它是啥,用来干啥,下面就是要知道它涉及的基本概念,才能为接下来的深入学习和使用打下良好基础,本文先来缕一缕最基本且最重要的概念。
一个典型的kafka架构包若干Producer、若干Broker、若干Consumer,以及一个Zookeeper集群。

有的小伙伴会问ZK在里面的角色是啥?为什么在玩kafka的时候需要先启动一个ZK?其实ZK在kafka中主要负责集群元数据的管理、控制器的选举等操作。关于什么是元数据,我这里简单说明一下:
元数据就是描述数据的数据。初次看到这个表述有点懵,其实简单来说,就像是手机或者电脑的参数,比如像素多少千万、处理器多少HZ等,这些数据都是用来描述手机的,整个参数合起来,我们大概就知道这个手机的配置如何。阮一峰的一篇文章说得可能详细一点,不妨去看看。
关于控制器的选举,可能难懂一点,会在后续的内容中说明。
回到上图,我们可以看到kafka的一个工作方式:Producer将消息发送到Broker中并持久化到磁盘,而Consumer负责从Broker订阅并消费消息。
注意,上面提到了三个专业名词:Producer,Broker以及Consumer。这个是三个最基本的术语,意义也很简单,下面一一阐述。
Producer即生产者,就是发送消息的一方,负责创建消息,然后投递到kafka。Consumer即消费者,就是接收消息的一方,负责连接到kafka上并接收消息。Broker即服务代理节点,Broker可以简单看作一个独立的kafka服务节点或者kafka服务实例,通常情况下,可以将Broker看作一台Kakfa服务器,前提是这个服务器上只部署了一个kafka,所以简单来说,broker就是一个kafka实例。
在kafka中还有两个重要的概念:主题(Topic)和分区(partition)。
kafka中的消息以主题为单位进行分类,生产者负责将消息发送到特定的主题下,消费者可以订阅相关的主题去消费。
主题是一个抽象的概念,可以细分为多个分区。他们的关系是:一个主题可以分为多个分区,一个分区只属于一个主题。那么分区是啥呢?
简单来说,就是这个主题的所有消息在物理上可以分为多块进行存储,这个块就可以理解为分区了。那么不难理解的是:每个分区上的消息不一样,所有分区的消息加起来就是一个主题的所有消息。
分区在存储层面可以看作是一个可追加的日志文件,消息在被追加到分区日志文件的时候就会分配一个特定的偏移量(offset),这个玩意很重要,就是标识这个分区下某个消息的顺序,并且是这个消息的唯一标识。注意,offset不能跨越分区,即kafka保证的顺序性是在一个分区内所有消息的顺序性,而不是整个topic下所有消息的顺序性。

上图所示就是表示一个抽象概念的topic下的所有消息可以分为多个分区进行存储。每个分区的消息按照offset进行顺序追加存储。分区可以在不同的broker上,也就是说,一个topic下的数据可以分布在不同的服务器上,显而易见,这样做的好处是可以提高吞吐量,因为我可以起多个生产者/消费者去不同的分区消费,达到并行处理的效果。
分区个数可以在创建主题的时候指定,也可以在主题创建之后去修改分区的数量,注意分区的数量只能增加不能减少。
三、副本机制
上面介绍了最基本也是最重要的概念,概念相对来说比较清晰,下面来说说副本机制。kafka引入多副本机制,可以提高容灾能力。
同一分区的不同副本理论上保存是相同的消息(同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,而follow副本只负责与leader副本的消息同步。副本处于不同的broker中,而leader副本出现故障时,从follow副本中重新选举新的leader副本对外提供服务。kafka通过多副本机制实现了故障的自动转移,当kafka集群中某个broker失效时仍然能保证服务可用。
这里举个例子,kafka集群中有4个broker,某个主题有3个分区,假设副本因子时3,则每个分区便有一个leader副本和两个follow副本。follow副本中的消息相对leader副本中的消息有一定的滞后性。
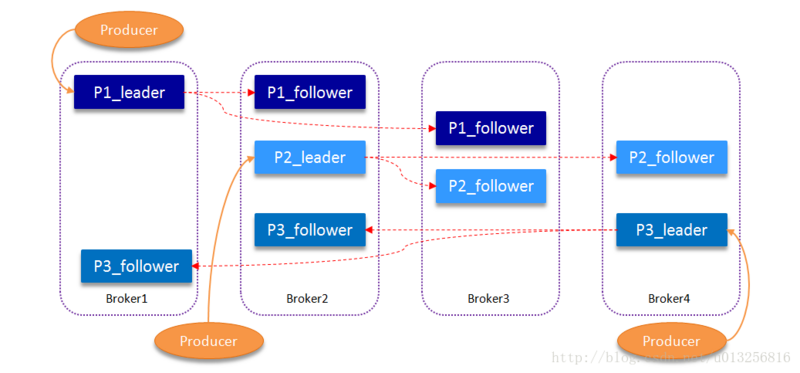
当然,kafak的消费端也有容灾机制,当某个消费者宕机,只要记录了消费的offset,就可用从指定的offset处重新消费,不会造成消息的丢失。
分区中所有的副本统称为AR,所有与leader副本保持一定程度同步的副本组成ISR,ISR是AR的子集,消息会先发送到leader副本,然后follow副本才能从leader副本中拉取消息进行同步。与leader副本同步滞后过多的副本组成OSR,由此可见:AR=ISR+OSR。在正常情况下,所有的follow副本都应该与leader副本保持一定程度的同步,即AR=ISR,OSR集合为空。
leader副本负责维护和跟踪ISR集合中所有follow副本的滞后状态,当follow副本落后太多或者失效时,leader副本会把它从ISR集合中剔除。如果OSR集合中有follow副本追上了leader副本,那么leader副本就会把它从OSR集合中转移到ISR集合中。
默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader,而在OSR集合中的副本原则上没有机会(除非修改相应的配置参数)。
此外,还有两个名词值得关注:
HW(High WaterMark): 高水位, 用来标记一个特定的消息偏移量,消费者只能拉取到这个offset之前的消息(可见性)LEO(Log End Offset) : 标志着当前日志文件中下一条待写入消息的offset。 分区ISR集合中的每个副本都维护自身的LEO,而ISR集合中的最小LEO为分区的HW,对消费者而言只能消费HW之前的消息。
对此记住一点,这两个都是指最后一条的下一条的位置而不是指最后一条的位置。
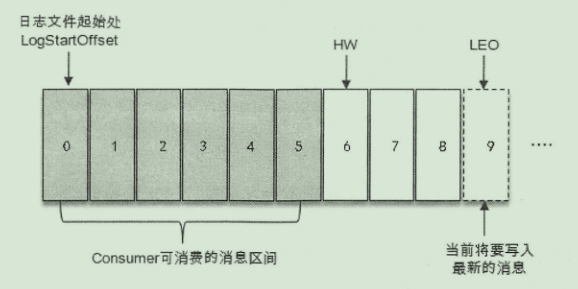
当消息写入leader副本之后,follow副本会发送拉取请求来拉取消息以进行消息同步。在同步的过程中,不同的follow副本同步效率不尽相同,此时各个follow的LEO也就不一样,这个时候HW就是最小的LEO,那么消费者能消费到的消息就是这个HW之前的消息。
说白点就是,这种方式保证消费者消费到的是当前follow副本中同步最慢的那个消息,可以看出,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制,同步复制要求所有能工作的follow副本都要复制完,这条消息才会被确认已成功提交,这种复制方式极大地影响了性能;异步复制方式下,follow副本异步地从leader副本中复制数据,数据只要被leader副本写入就认为已成功提交,这种方式下,如果leader副本突然宕机但是follow副本还没有复制完,则会造成数据丢失。kafka这种ISR的方式有效地权衡了数据可靠性和性能之间的关系。
下面介绍基本的使用,包括topic的查看、创建,生产者的启动以及消费者的启动等。