
04kafka生产者

在完成kafka的入门以及基本的操作之后,相信已经对kafka有了基本认识,下面我们一起从kafka的生产者开始,深入学习一下。
一、一个简单的生产者示例
1 | public class KafkaProducerAnalysis { |
注意,KafkaProducer是线程安全的,可以在多个线程中共享单个KafkaProducer实例,也可以将KafkaProducer实例进行池化来供其他线程调用。
- 生产逻辑的几个步骤:
- 配置生产者客户端参数并创建生产者实例
- 构建待发送消息
- 发送消息
- 关闭生产者实例
注意,我们发送消息的时候,可以指定消息的topic、partition、headers、key、value等字段。
topic:消息要发往的主题,不赘述partition:消息要发往的分区号,不赘述headers:指消息的头部,Kafka 0.11.x版本才引入此属性,它大多来设定一些与应用相关的信息,基本不用管他。key:指消息的键,它可以用来计算分区号进而可以让消息发往特定的分区,消息可以以主题进行分类,也可以用key进行二次归类,同一个key的消息会被划分到同一个分区。,有key的消息可以支持日志压缩功能。value:指消息体,一般不为空,如果为空则表示特定的消息-墓碑消息,后续介绍。
二、发送消息的三种模式
1 | public Future<RecordMetadata> send(ProducerRecord<K, V> record); |
- 发后即忘
- 只管发送消息,不关心信息是否正确到达。
- 优点:性能最高,吞吐量大
- 缺点:会造成数据丢失,可靠性低
- 同步
- 发送消息后返回
Future对象,调用get()方法时阻塞等待,直到发送成功或出现异常 - 优点:可靠性高,如有异常可处理或进行消息重发
- 缺点:性能低,造成阻塞
- 发送消息后返回
- 异步
- 发送消息时指定回调函数,
Kafka在返回响应时会调用该函数实现异步的发送确认。 - 在同一个分区中,如果消息
record1比record2先发送,那么它会保证callback1在callback2之前调用。
- 发送消息时指定回调函数,
这里推荐使用第三种即回调函数的方式来实现,但是针对send()方法的返回值是Future可能会有疑问:Future本身就是可以用作异步的逻辑处理。这样做不是不行,只不过Future里的get()方法在何时调用,以及怎么调用都是需要面对的问题,消息不停地发送,那么诸多消息的Future对象的处理难免会引起代码处理逻辑的混乱。因此推荐使用Callback这种回调函数的方式来处理,要么发送成功,要么抛出异常,回调函数示例:
1 | producer.send(record,new callback(){ |
注意,metadata和e是互斥的,消息发送成功时,metadata不为null而e为null;消息发送异常时,metadata为null为e不为null;
再来说说Future对象,它表示一个任务的生命周期,并提供了相应的方法来判断任务是否已经完成或取消,以及获取任务的结果和取消任务等。我们可以使用Future中的get(long timeout,TimeUtil unit)方法实现可超时的阻塞。
KafkaProducer中一般会发生两种异常:可重试的异常和不可重试的异常。常见的可重试异常有:
NetworkException:表示网络异常,有可能由于网络瞬间故障而导致的异常,可以通过重试解决LeaderNotAvailableException表示分区的leader副本不可用,这个异常通常发生在leader副本下线而新的leader副本选举完成之前,重试之后可以重新恢复。
不可重试的异常:比如RecordTooLargeException异常,暗示了所发送的消息太大,KafkaProducer对此不会进行任何重试,直接抛出异常。
三、发送者整体架构原理分析
整体架构如下:
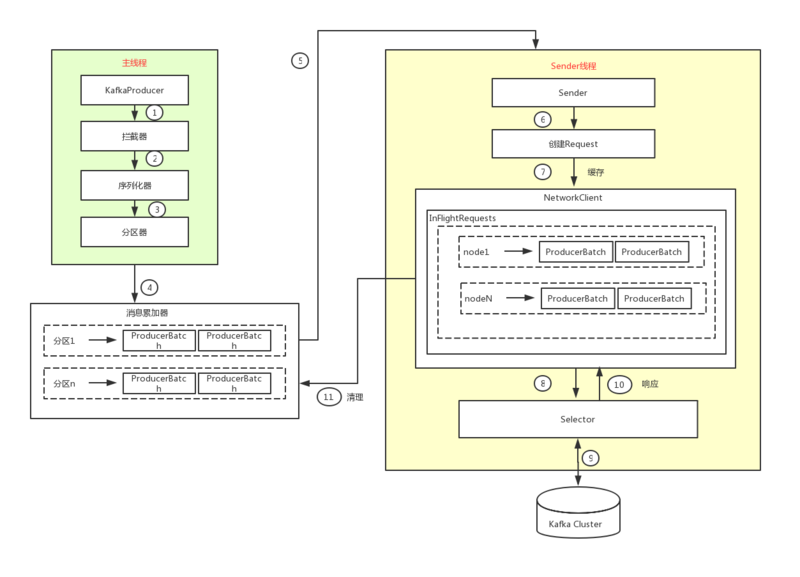
主要分为两个线程,一个主线程,一个发送线程,我们从左向右一一说明。
消息在发送到kafka之前,可能需要经历拦截器、序列化器和分区器。对应着图中是左边主线程中干的事情。下面一一介绍一下。
1.拦截器
拦截器早在Kafka0.10.0.0中已经引入的功能,一共有两种拦截器:生产者拦截器和消费者拦截器。这里当然主要关注生产者拦截器。
生产者拦截器既可以在消息发送之前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
下面给出一个简单示例,onSend()方法给每条消息加一个前缀prefix1-,并且通过onAcknowledgement开统计发送消息的成功率:
1 | public class ProducerInterceptorPrefix implements |
光有这个还不够,还需要在KafkaProducer的配置参数interceptor.classes中指定这个拦截器,此参数的默认值为“”,示例为:
1 | properties.put(ProducerConfig.INTERCEPTOR_CLASSED_CONFIG, |
当然了,也可以指定多个拦截器形成拦截链,多个的拦截器之间用逗号隔开,并且是有顺序的,排在前面的先执行。
总结一下就是:消息一发出首先就是经过拦截器链处理消息,如果消息发送失败会调用onAcknowledgement方法,这个方法优先于用户设定的Callback之前执行。一般情况下,拦截器是用不到的。
2.序列化器
关于序列化,没什么好说的,总结为以下三句话:
- 生产者使用序列化器将对象转换为字节数组,才能通过网络发送给Kafka
- 消费者使用反序列化其把Kafka中收到的字节数组转换为相应的对象。
- 因此生产者的序列化器和消费者使用的反序列化器要一一对应。
3.分区器
上面介绍了拦截器和序列化器,一般情况下拦截器是不需要的,序列化器是必需的,消息经过序列化之后就需要确定它发往的分区,如果消息ProducerRecord中指定了partition字段,那么就不需要分区器了,因为partition就是要发往的分区号。
如果消息ProducerRecord中没有指定partition字段,就需要依赖分区器,根据key这个字段来计算partition的值,分区器的作用就是为消息分配分区。此时有两种情况:
key为null:那么消息将以轮询的方式发往主题内各个可用分区key不为null:默认的分区器会对key进行哈希(采用MurmurHash2算法,具备高运算性能即低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同的key的消息会被写入同一个分区下
好了,至此介绍了拦截器、序列化器以及分区器的作用之后,之后又会发生什么呢?
不得不再把整体架构图拿过来了:
我们可用看到,整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程。
四、主线程
在主线程中由kafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也成为消息收集器)。Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
RecordAccumulator主要用来缓存消息以便Sender线程可用批量发送,进而减少网络传输的资源损耗以提升性能。RecordAccumulator缓存消息的可以通过buffer.memory进行配置,默认为32兆。
主线程中发送过来的消息都会被追加到RecordAccumulator的某个双端队列中,在RecordAccumulator的内部每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即Deque<ProducerBatch>。
消息写入缓存时,追加到双端队列的尾部;Sender线程获取消息时,从双端队列的头部读取。
注意这里的ProducerBatch不是ProducerRecord,后者是一条消息,前者可以包含一个或多个ProducerRecord,即ProducerBatch是一个消息批次,ProducerRecord只是一条消息而已。ProducerBatch中包含多条ProducerRecord是为了使字节的使用更加紧凑,与此同时可以减少网络请求以提升整体的吞吐量。
ProducerBatch与batch.size参数有一定的关系。当一条消息ProducerRecord流入RecordAccumulator时,会先寻找与消息分区所对应的双端队列(如果没有则新建),再从这个双端队列的尾部获取一个ProducerBatch(如果没有则新建),查看ProducerBatch中是否还可以写入这个ProducerRecord,如果可以则写入,如果不可以则需要创建一个新的ProducerBatch。
在新建ProducerBatch的时候评估这条消息是否超过batch.size参数的大小,如果不超过,就以batch.size参数的大小来创建ProducerBatch,这样在使用完这段内存区域之后,可以通过BufferPool的管理来进行复用;如果超过,就以评估的大小来创建ProducerBatch,这段内存区域不会被复用。
如果消息总是大于batch.size的大小,那么就会频繁地在内存中创建和释放这段区域,时比较浪费资源的。因此,batch.size的参数比较重要,默认是16K,我们可以适当调大以便多缓存一些消息。
五、Sender线程
Sender从RecordAccumulator中获取缓存的消息之后,会进一步将原来<分区,Deque<ProducerBatch>>的保存形式转变成<node,List<ProducerBatch>>的形式,其中node表示kafka集群的broker节点。
对于网络连接来说,生产者客户端是与具体的broker节点建立的连接,也就是向具体的broker节点发送消息,而并不关心消息属于哪一个分区;而对于KafkaProducer的应用逻辑来说,我们只关注向哪个分区发送哪些消息,所以需要在这里做一个应用逻辑层面到IO层面的转换。
在转成<node,List<ProducerBatch>>的形式之后,Sender还会进一步封装成<node,Request>的形式,这样就可以将Request请求发往各个node了,这里的Request指kafka的各种协议请求,对于消息发送而言就是指具体的producerRequest,更多与kafka协议相关的内容后面章节再讨论。
请求从Sender线程发往kafka之前还会保存到InFlightRequests中,InFlightRequests保存对象的具体形式为Map<nodeId,Deque<Request>>,它的主要作用是缓存了已经发出去但还没收到响应的请求。InFlightRequests可以通过配置参数限制每个连接(客户端和kafka之间的连接)最多的缓存的请求数。默认值为5,即每个连接最多缓存5个未响应的请求,超过该数值之后就不能向这个连接发送更多的请求了,除非有缓存的请求收到了响应。通过比较Deque<Request>的size参数大小可以判断对应的node是否已经堆积了很多未响应的消息,如果堆积了很多,说明这个node节点负载比较大或者网络连接有问题,再继续对其发请求会增大超时的可能。
六、元数据的更新
我们使用如下的方式创建了一条消息producerRecord:
1 | ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!"); |
我们只知道主题的名称,对于其他的必要信息一无所知。KafkaProducer要将此消息追加到指定主题的某个分区所对应的leader副本之前,首先需要知道主题的分区数量,然后经过计算得到(或者直接指定)目标分区,之后KafkaProducer需要知道目标分区的leader副本所在的broker节点的地址、端口等信息才能建立连接,最终才能将消息发送到kafka。这一过程需要的信息属于元数据信息。
元数据是指Kafka集群中的元数据,这些元数据记录了集群中有哪些主题,这些主题有哪些分区,每个分区的leader副本分配在哪个节点上,follwer副本分配在哪些节点上,哪些副本在AR,ISR集合中,集群有哪些节点,控制节点又是哪一个等信息。
与此同时,我们知道bootstrap.servers参数只需要配置部分kafka节点的地址即可,不需要配置所有broker节点的地址,因为客户端可以自己发现其他broker节点的地址,这一过程属于元数据相关的更新操作;分区数量及leader副本的分布都会动态地变化,客户端需要动态捕捉这些变化。这里想说的是,在客户端的内部会进行元数据的更新操作(计算元数据都没变过,但是超过一段时间也会自动更新),当客户端需要更新元数据时,会挑选 InFlightRequests 中当前负载最小的节点发送更新元数据请求。
元数据虽然由Sender线程负责更新,但是主线程也需要读取这些信息,因此数据同步问题也要考虑,使用synchronized和final保证。
七、重要的生产者参数
acks: 用来指定分区中必须要有多少个副本收到这条消息,这样生产者才认为消息写入成功- 取值为1 : 只要
leader副本成功写入消息,就会收到kafka的成功响应 - 取值为0: 不需要等待任何服务器响应,写入就认为成功
- 取值为-1或all:需要等待
ISR中的所有副本都成功写入消息,才会收到kafka的成功响应
- 取值为1 : 只要
max.request.size- 限制生产者客户端能发送消息最大值
retires、retry.backoff.ms- 配置生产者重试次数 、 两次重试的时间间隔
max.in.flight.requests.per.connection- 默认值为5,即每个连接最多只能缓存5个未响应的请求。
- 当此参数 > 1 ,则会因为重发而出现错序的问题