
05kafka消费者-上

学习完生产者,下面自然就是消费者。消费者要学习的内容比生产者要多,本篇主要聚焦于消费者/消费组的基本概念以及客户端的基本开发(包括如何订阅主题和分区、如何消费消息)。
一、消费者和消费组
在学习消费者消费消息之前,需要先了解消费者和消费组的关系。
消费者负责订阅kafka的主题,并且可以从订阅的主题上拉取消息。与其他一些消息中间件不同的是:在kafka的消费理念中还有一层消费组的概念,每个消费者都有一个对应的消费组。当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者。
消费者以组的名义订阅主题,主题有多个分区,消费者组中有多个消费者实例,那么消费者实例和分区之间的对应关系是怎样的呢?
换句话说,就是组中的每一个消费者负责那些分区,这个分配关系是如何确定的呢?如下图示例:
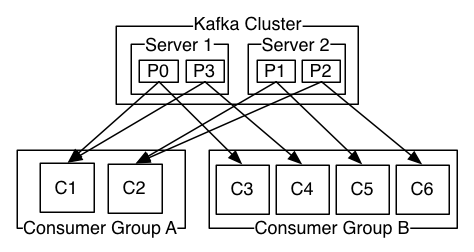
这是kafka的默认规则,分配结果为消费组A的每个消费者分到两个分区,消费组B每一个消费者分到一个分区,两个消费组之间互不影响。
也就是说:消费者组订阅这个主题,意味着主题下的所有分区都会被组中的消费者消费到,如果按照从属关系来说的话就是,主题下的每个分区只从属于组中的一个消费者,不可能出现组中的两个消费者负责同一个分区。
话说回来,假设一个消费组内多个消费者负责同一个分区,那么会有什么问题呢?
我们知道,Kafka它在设计的时候就是要保证分区下消息的顺序,也就是说消息在一个分区中的顺序是怎样的,那么消费者在消费的时候看到的就是什么样的顺序,那么要做到这一点就首先要保证消息是由消费者主动拉取的(pull),其次还要保证一个分区只能由一个消费者负责。
倘若,一个消费组内两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,会造成两个问题:
- 重复消息处理:
C1才读到2,C1还没处理完,C2又可能去读2去处理,则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复 - 不能保证消息顺序:一个线程在处理1,还没处理完,另一个线程已经处理到3,此时1处理完了,那么消费的处理顺序就不对了
下面我们看看当消费组内的消费者个数变化时对应的分区分配演变如下:(默认的RangeAssinor为例)
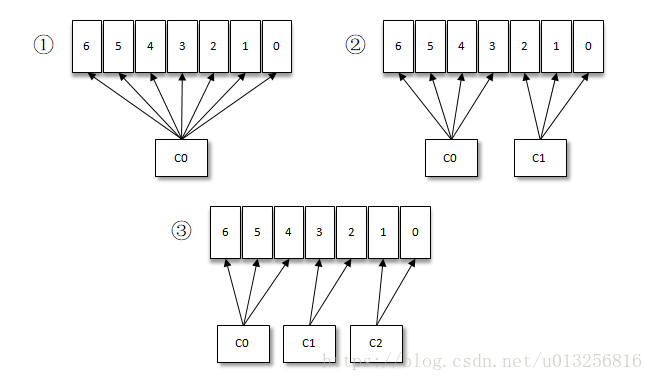
我们可以看到,当增加消费者的时候,每个消费者分到的分区就会动态地减少,可以利用这个消费者-消费组模型来扩展消费能力。但是我们不能一味地增加消费者,如果消费者过多,出现了消费者个数大于分区个数的情况,就会有消费者分配不到任何分区。
此外,kafka同时支持两种消息投递模式也是得益于消费者与消费组模型:点对点(P2P)模式和发布/订阅(Pub/Sub)模式。
简单介绍一下点对点模式:基于队列,消息生产者发送消息到队列,消息消费者从队列中接收消息。
下面简单介绍一下发布订阅模式:定义了如何向一个内容节点发布和订阅消息,这个内容节点成为主题,主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者从主题中订阅消息。主题使得消息的订阅者和发布者互相保持独立,不需要进行接触可保证消息的传递,发布订阅模式在消息的一对多广播时采用。
前面说了,kafka支持这两种模式:
- ⭐如果所有消费者都隶属于同一个消费组,那么所有的消息都会被均衡地投递给每一个消费者,即每条消息只会被一个消费者处理,相当于点对点模式
- ⭐如果所有的消费者都隶属于不同的消费组,那么所有的消息都会被广播给所有的消费者,即每条消息会被所有的消费者处理,相当于发布/订阅模式的应用
每一个消费者只隶属于一个消费组。消息发送时可指定消费者组, 消费者客户端通过group.id配置消费者组名称,默认为空字符串。
二、消费者客户端开发
注意KafkaConsumer是非线程安全的,以下为一个简单的消费者客户端的代码示例:
1 | public class KafkaConsumerAnalysis { |
Kafka的消费逻辑
- 配置消费者客户端参数及创建相应消费者实例
- 订阅主题
- 拉取消息并消费
- 提交消费位移(后面会讲)
- 关闭消费者实例
以上的一些参数配置跟生产者端很类似,这里多一个group.id和client.id两个参数。前者为消费组,后者为标识客户端的id,如果不设置则默认生成一个非空字符串,内容形式如:consumer-1、consumer-2等。
三、订阅主题和分区
消费者可以订阅一个或多个主题,上述示例用
1 | consumer.subscribe(Arrays.asList(topic)); |
来订阅了一个主题。如果前后两次订阅了不同的主题,那么消费者以最后一次的为准。
1 | consumer.subscribe(topic1); |
那么消费者最终订阅的是topic2,而不是topic1,也不是topic1和topic2的并集。
还可以用正则表达式的方式订阅,形如:
1 | consumer.subscribe(Pattern.compile("topic-.*")); |
消费者不仅可以通过KafkaConsumer.subscribe()的方法订阅主题,还可以直接订阅某些主题的特定分区,在KafkaConsumer中提供了assign()方法来实现这些功能。此方法的具体定义为:
1 | public void assign(Collection<TopicPartition> partitions) |
这个方法只接收一个参数partitions,用来指定需要订阅的分区集合。这个TopicPartition类定义的部分内容为:
1 | public final class TopicPartition implements Serializable { |
TopicPartition类中只有两个属性,分别代表分区所属的主题和自身的分区编号,这个类可以和我们通常说的主题-分区的概念映射起来。
具体的使用如下:
1 | consumer.assign(Arrays.asList(new TopicPartition("topic-demo",0))); |
可能会有疑问:如果我们事先不知道主题中有多少个分区怎么办?KafkaConsumer中的partitionsFor()方法可以用来查询指定主题的元数据信息,partitionsFor()方法具体定义为:
1 | public List<PartitionInfo> partitionsFor(String topic) |
PartitionInfo类型即为主题的分区元数据信息,此类的主要结构为:
1 | public class PartitionInfo{ |
我们通过partitionsFor()方法可以订阅主题全部分区的功能:
1 | List<TopicPartition> partitions = new ArrayList<>(); |
上面介绍了三种订阅的方式:集合订阅的方式subscribe(Collection)、正则表达式订阅方式subscribe(Pattern)、
指定分区的订阅方式assign(Collection),分别代表了三种不同的订阅状态:AUTO_TOPICS、AUTO_PATTERN和USER_ASSIGNED(如果没有订阅则状态为NONE)。这三种状态是互斥的,在一个消费者中只能使用其中的一种,否则会报出IllegalStateException异常。
他们之间还有一个区别:subscribe订阅主题时具有自动再平衡(后面会讲)的功能,在多个消费者的情况下可以根据分区策略来自动分配各个消费者与分区的关系,当消费组内的消费者增加或减少时,分区分配关系会自动调整,以实现消费负载均衡及故障自动转移;而assign不具备消费者自动均衡的功能。从源码可以看到subscribe()重载方法里有一个参数类型为ConsumerRebalanceListener,这个是用来设置相应的再均衡监听器的,后面还会再次说明。
四、消息消费
kafka中的消费是基于拉模式的。
消息的消费一般有两种模式:推模式和拉模式。推模式是服务端主动将消息推送给消费者,而拉模式是消费者主动向服务端发起请求来拉取消息。
我们从第二节的代码可以看到,kafka的消息消费是一个不断轮询的过程,消费者所要做的就是重复调用poll方法,而poll方法返回的是订阅的主题或分区上的一组消息。
对于poll而言,如果某些分区中没有可供消费的消息,那么此分区对应的消息拉取的结果就为空;如果所有分区都没有可供消费的消息,那么poll返回空的消息集合。
poll()方法的定义:
1 | public ConsumerRecords<K, V> poll(Duration timeout); |
timeout参数是超时时间参数,用来控制poll的阻塞时间,在消费者的缓冲区中没有可用数据时会发生阻塞。注意参数类型为Duration,他是JDK8中新增的一个与时间有关的类型。可用利用Duration中的ofMillis()、ofSeconds()、ofMinutes()、ofHours等多种不同的方法指定不同的时间单位,灵活性更强。老的方式是:
1 | public ConsumerRecords<K, V> poll(final long timeout); |
明显时间单位只能用固定的毫秒,因此被标注为了@Deprecated,推荐用新的方式。
timeout的设置取决于应用程序对响应速度的要求,比如需要在多长时间内将控制权移交给执行轮询的应用线程。可以直接将timeout设置为0,这样poll方法就会立刻返回,而不管是否已经拉取到消息。
再看在第二节一开始示例的代码中:
1 | while (isRunning.get()) { |
其实它是将订阅的主题中所有的消息都收到了,那么我们能不能以分区的维度进行消费呢?这一点很有用,在手动提交位移时尤为明显。关于提交位移下一节再详述。ConsumerRecords类提供了一个records(TopicPartition)方法来获取消息集中指定分区的消息,此方法的定义为:
1 | public List<ConsumerRecord<K,V>> records(TopicPartition partition) |
下面为按照分区的维度对消息进行消费代码:
1 | while (isRunning.get()) { |
其中,records.partitions()用来获取消息集中所有分区。那我们能不能以主题的维度进行消费呢?ConsumerRecords提供了:
1 | public Iterable<ConsumerRecord<K,V>> records(String topic) |
下面为按照主题的维度对消息进行消费代码:
1 | List<String> topicList = Arrays.asList(topic1,topic2); |
到目前为止,可以简单认为poll方法只是拉取一下消息而已,不过内部逻辑并不简单,它涉及消费位移、消费者协调器、组协调器、消费者的选举、分区分配的分发、再均衡的逻辑、心跳等内容。下面的文章再去继续探讨。