
06kafka消费者-中

下面继续探讨kafka的消费者,正如上篇文章最后所说,消费者的逻辑牵涉到很多内容,并不是简单地死循环获取消息那么简单。本篇文章着重介绍消费者中比较重要的概念:消费位移。
一、消费位移概念
对于kafka中的分区所言,它的每条消息都有唯一的offset,用来表示消息在分区中对应的位置。可以翻译成”偏移量“,也可以翻译为”位移“。这里做个约定:对于消息在分区中的位置,我们将offset称为“偏移量”;对于消费者消费到的位置,将offset称为“位移”或“消费位移”。当然,不区分也是可以的,因为毕竟这个offset是唯一的,一条消息在分区中的offset是固定的。
消费位移需要持久化,为什么呢?
二、消费位移持久化
我们知道,每次调用poll方法时,它返回的时还没有被消费过的消息集(前提时消息已经存储在kafka上了),要做到这一点,就需要记录上一次消费时的消费位移。并且这个消费位移必须持久化保存,而不是单单保存在内存中,否则消费者重启之后就无法知晓之前的消费位移。
再考虑一种情况,当有新的消费者加入时,那么必然有再均衡的动作,对于同一分区而言,它可能在再均衡动作之后分配给新的消费者,如果不持久化消费位移,那么这个新的消费者也无法知晓之前的消费位移。
在旧消费者客户端中,消费位移是存储在zookeeper中的,而在新消费者客户端中,消费位移是存储在kafka内部的主题_consumer_offsets中。这里把消费位移存储起来(持久化)的动作称为“提交”,消费者在消费完消息后需要执行消费位移的提交。
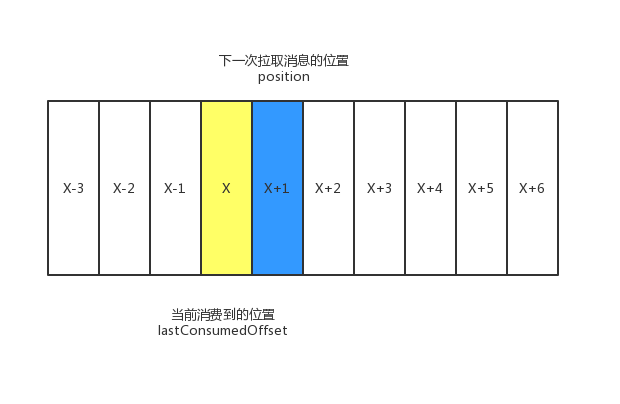
上图中X表示某一次拉取操作中此分区消息的最大消息偏移量,也就是说,此时消费者的消费位移为X,图中用lastConsumedOffset来表示。
⭐不过需要明确的是,当前消费者需要提交的消费位移是X+1而不是X。对应的是图中positition,它表示下一条需要拉取的消息的位置。
此外,消费者中还有一个committed offset的概念,表示已经提交过的消费位移。
KafkaConsumer类提供了position(TopicPartition)和commited(TopicPartition)两个方法来分别获取上面所说的position和committed offset的值。这两个方法的定义如下:
1 | public long position(TopicPartition partition) |
上面提到了三个名词:lastConsumedOffset、committed offset以及positition。他们的关系是:一般情况下,committed offset=positition=lastConsumedOffset+1。不过committed offset与positition并不是一直相同。这个情况下面会体现。
位移的提交时机也有讲究,可能会造成重复消费和消息丢失的现象
- 拉取到消息之后就进行位移提交, 若消费到一半时宕机,则造成消息丢失现象
- 消费完所有消息后在进行位移提交, 若消费到一半时宕机,则造成重复消费现象
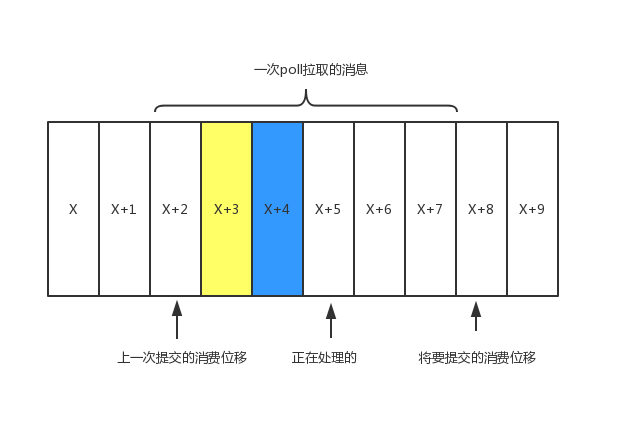
如上图所示,当前poll操作所拉取的消息集为[x+2,x+7],x+2代表上一次提交的消费位移,说明已经完成了x+1之前(包括x+1)的所有消息的消费。x+5表示当前正在处理的位置,如果拉取到消息之后就进行了位移提交,即提交了x+8,那么当前消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+8开始的。也就是说。x+5和x+7之间的消息未能被消费,便发生了消息丢失现象。
再考虑另一种情形,位移提交的动作是在消费完所有拉取到的消息之后才执行的,那么当消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+2开始的,也就是说,x+2和x+4之间的消息又重新消费了一遍,故而发生了重复消费的现象。
三、自动位移提交
Kafka默认的消费位移提交方式是自动提交(定期)。enable.auto.commit默认为true,这个默认的自动提交不是每消费一条消息旧提交一次,而是定期提交;
auto.commit.interval.ms配置提交的周期,默认为5秒。自动提交的动作是在poll()方法的逻辑中完成的,会在每次拉取请求之间检查是否可以进行位移提交。
在默认情况下,消费者每隔5秒会将拉取到的每个分区中最大的消息位移进行提交。自动位移提交的动作是在poll方法的逻辑里面完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一轮轮询的位移。
位移自动提交很简便,免去了复杂的位移提交逻辑,让编码更简洁,但是随之而来的是重复消费和消息丢失的问题。
- 重复消费: 消费到一半时宕机,而尚未提交,则造成重复消费
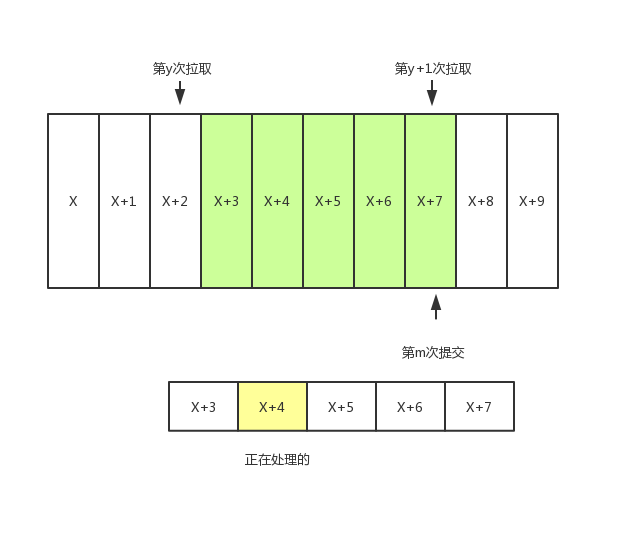
- 消息丢失:如图线程A进行拉取消息到缓存,线程B从缓存中处理逻辑。 若线程B处理到一半时宕机,那么下次恢复时又从【X+7】开始拉取,造成了【x+4】-【X+7】消息的丢失
重复消费比较好理解,因为自动提交是一种延时提交,在自动提交位移前消费者崩溃了,那么必然会从上一次位移提交的地方开始重新消费,我们可以通过减少位移提交的时间间隔来减少重复消息的窗口大小,但不能避免消息重复的问题,还会使位移提交更加频繁。那么如果理解消息丢失呢?
如上图所示,假设线程A不断拉取消息存到本地缓存,比如BlockingQueue中,另一个处理线程B从缓存中读取消息并进行相应的逻辑处理。
现在假设进行到了y+1次拉取,以及第m次位移提交的时候,也就是说X+7之前的位移已经确认提交了,处理线程B还在处理X+4的消息,此时如果线程B发生异常,恢复后会从第m次位移提交处,即X+7的地方开始拉取消息。那么X+3至X+7之间的消息就丢失了。
四、手动提交
可以看出自动提交编码简单但会出现消息丢失和重复消费现象,并且无法做到精确的位移管理,因此Kafka还提供了 手动提交的方式。通常不是拉取到消息就算消费完成了,而是当我们通过这条消息完成一系列业务处理后,才认为消息被成功消费。开启手动提交需要enable.auto.commit设置为false.
手动提交可分为同步提交和异步提交。 即commitSync()和commitAsync()两种方式
以下是同步提交示例:
1 | #拉取所有消息并处理后进行同步提交 |
上面的示例是对拉取的每一条消息做相应的处理,然后对整个消息集做同步提交。也可以改为批量处理+批量提交。
1 | #批量处理+批量提交 |
上面的代码改为:先将消息存入缓存buffer,当消息积累足够多的时候在进行批量的处理和批量提交。以上两个示例都存在重复消费的问题,即如果在业务逻辑处理完之后,并且在同步位移提交之前,程序出现了崩溃,那么待恢复后只能从上一次位移提交的地方拉取消息,由此造成重复消费。
如果想寻求更细粒度、更精准的提交,需要使用另一个含参方法,如下例代码所示:
1 | #带参数的同步位移提交,可控制提交的offset,该案例为每消费一条就提交一次 |
此方法提供了offset参数,用来提交指定分区的位移。无参的commitSync()方法只能提交当前批次对应的position值。如果需要提交一个中间值,比如上述代码中每消费一条消息就提交一次位移,就可以使用这个方法。
实际应用中,很少有这种每消费一条消息就提交一次消费位移的必要场景。commitSync()本身是同步执行的,会耗费一定的性能,更多的时候是按照分区的粒度划分提交位移的界限。
1 | #按分区粒度同步提交消费位移,每处理完一个分区就提交一次 |
异步提交在执行的时候消费者线程不会被阻塞,可能在提交消费位移的结果还未返回之前就开始了新一轮的拉取操作。异步提交可以使消费者的性能得到一定的增强。有三个重载方法:
1 | #异步提交,可指定提交完成后的回调函数 |
其中callback参数,提供了一个异步提交的回调函数,当位移提交完成后会回调OffsetCommitCallback中的onComplete方法。
异步提交也存在重复消费的问题。如果先提交了【X+2】,再提交【X+8】。如果后者提交成功而前者提交失败。 如果此时前者进行重试提交,那么成功后会造成数据的重复消费。
对于异步提交可以设置一个递增的序号维护异步提交的顺序,如当位移提交失败需要重试提交时,对比所提交的位移和维护的序号大小,如果前者小于后者,就不需要再重复提交了。如果两者相等,则可以进行重试提交。
五、控制或关闭消费
KafkaConsumer提供了对消费速度进行控制的方法,在某些应用场景下我们可能需要暂停某些分区的消费而先消费其他分区,当达到一定条件时可以再恢复这些分区的消费。KafkaConsumer提供了暂停pause()和恢复resume()某些分区的消费。
之前的示例中都是使用一个while循环来包裹住poll()方法及相应的消费逻辑,如果优雅地退出这个循环呢?
之前的代码中并不是以while(true)来简单包裹,而是while(isRunning.get())的方式,这样可以通过在其他地方设定isRunning.set(false)来退出while循环。
还有一种方式是调用KafkaConsumer的wakeup()方法,wakeup()方法是KafkaConsumer中唯一可以从其他线程里安全调用的方法(KafkaConsumer是非线程安全的),调用wakeup()方法后可以退出poll()的逻辑,并抛出WakeupException的异常,我们不需要处理它,它只是一种跳出循环的方式。
跳出循环后一定要显式地执行关闭动作以释放运行过程中占用的各种资源,包括内存资源、Socket连接等。KafkaConsumer提供了close()方法来实现关闭:
1 | public void close() |
第二种方法是通过timeout参数来设定关闭方法的最长执行时间,有些内部的关闭逻辑会耗费一定的时间,比如设置了自动提交消费位移,这里还会做一次位移提交的动作。而第一个方法中没有timeout参数,这并不意味着会无限制等待,内部设定最多等待30秒。第三种方法已过时,可以不关心。
那么一个相对比较完整的消费程序可以参考以下的伪代码:
1 | consumer.subscribe(Arrays.asList(topic)); |