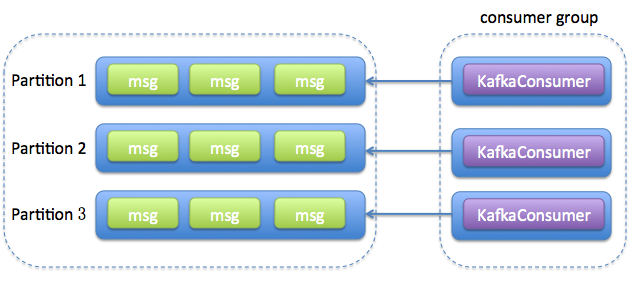
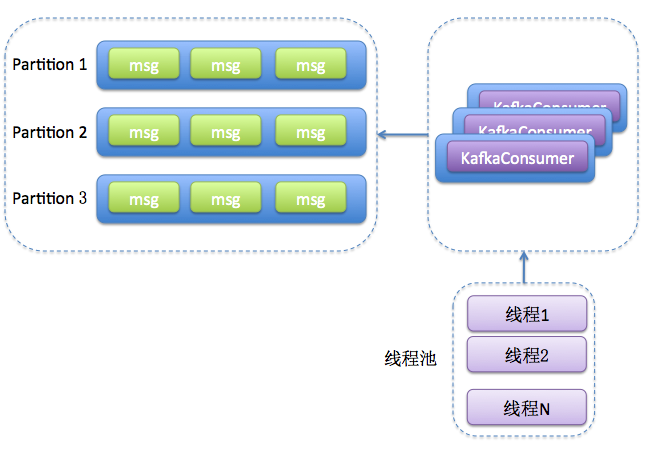
之前学习了如何进行消费位移的提交,正是有了消费位移的持久化,才能使消费者在关闭、崩溃或者遇到再均衡的时候,可以让接替的消费者根据存储的消费位移继续继续进行消费。
一、指定位移消费
当一个新的消费组建立的时候,它根本没有可以查找的消费位移;或者消费组内的一个新消费者订阅了一个新的主题,此时没有可以查找的消费位移;当_consumer_offsets主题中有关这个消费组的位移信息过期而被删除后,他也没有可以查找的消费位移。
在kafka中,每当消费者找不到所记录的消费位移时,就会根据消费者客户端参数auto.offset.reset的配置来决定从何处开始消费,默认值为latest,表示从分区末尾开始消费消息。如果配置成earliest,那么消费者就会从起始处开始消费。如果配置为none,表示当出现查不到消费位移的时候,既不从最新的消息位置处开始消费,也不从最早的消息位置处开始消费,此时会报出NoOffsetForPartitionException异常。
如果能够找到消费位移,那么配置成none也不会出现任何异常。如果配置的不是latest或者earliest或者node,就会报出ConfigException异常。
到目前为止,我们知道消息的拉取时根据poll方法的逻辑来处理的,对于我们来说是一个黑盒,无法精确控制其消费的起始位置。提供的auto.offset.reset参数也只能在找不到位移或者位移越界的情况下粗粒度地从开头或者末尾开始消费。有的时候我们需要一种更细粒度的掌控,可以让我们从特定的位移处开始拉取消息。下面seek方法隆重登场,让我们得以追前消费或回溯消费。
具体定义为:
1 public void seek (TopicPartition partition,long offset)
partition表示分区,offset参数用来指定从分区的哪个位置开始消费。下面为一个示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); consumer.poll(Duration.ofMillis(2000 )); Set<TopicPartition> assignment = consumer.assignment(); System.out.println(assignment); for (TopicPartition tp : assignment) { consumer.seek(tp, 10 ); } while (true ) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000 )); for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value()); } }
⭐⭐如果将第①行改为consumer.poll(Duration.ofMillis(0));,会发现seek()方法并未有任何作用,因为当poll方法的参数为0时,此方法会立刻返回,那么poll方法内部进行分区分配的逻辑就会来不及实施。也就是说,消费者此时并未分配到任何分区,就会导致②中assignment是个空列表,后续的代码不会执行。
那么这里分配的timeout参数设置未多少合适呢?太短则使分配分区的动作失败,太长又有可能造成一些不必要的等待。一个好的解决方法就是判断到分区分配成功为止:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); consumer.poll(Duration.ofMillis(2000 )); Set<TopicPartition> assignment = new HashSet<>(); while (assignment.size == 0 ){ consumer.poll(Duration.ofMillis(100 )); assignment = consumer.assignment(); } System.out.println(assignment); for (TopicPartition tp : assignment) { consumer.seek(tp, 10 ); } while (true ) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000 )); for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value()); } }
如果未分配到分区执行seek()方法,就会报出IllegalStateException异常。如果消费组内的消费者在启动的时候能够找到消费位移,除非发生位移越界,否则auto.offset.reset参数并不会奏效,此时如果想指定从开头或者末尾开始消费,就需要seek()方法的帮助了。下面使从分区末尾开始消费:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); Set<TopicPartition> assignment = new HashSet<>(); while (assignment.size() == 0 ) { consumer.poll(Duration.ofMillis(100 )); assignment = consumer.assignment(); } Map<TopicPartition, Long> offsets = consumer.endOffsets(assignment); for (TopicPartition tp : assignment) { consumer.seek(tp, offsets.get(tp) + 1 ); } System.out.println(assignment); System.out.println(offsets); while (true ) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000 )); for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value()); } }
与endOffsets()对应的就是beginningOffsets()方法。起始KafkaConsumer中直接提供了seekToBeginning()方法和seekToEnd()方法来实现这两个功能。这两个方法的定义为:
1 2 public void seekToBeginning (Collection<TopicPartition> partitions) public void seekToEnd (Collection<TopicPartition> partitions)
当然了,消费位移可以存储在任何介质,比如数据库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 consumer.subscribe(Arrays.asList(topic)); for (TopicPartition tp: assignment){ long offset = getOffsetFromDB(tp); consumer.seek(tp, offset); } while (true ){ ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000 )); for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> record : partitionRecords) { } long lastConsumedOffset = partitionRecords .get(partitionRecords.size() - 1 ).offset(); storeOffsetToDB(partition, lastConsumedOffset+1 ); } }
seek()方法为我们提供了从特定位置读取消息的能力,我们可以通过这个方法来向前跳过若干消息,也可以通过这个方法来向后回溯瑞干消息,这样为消息的消费提供了很大的灵活性。seek()方法也为我们提供了将消费位移保存在外部存储介质的能力,还可以通过再均衡监听器来提供更加精准的消费能力。
二、再均衡
再均衡是指:分区的所属权从一个消费者转移到另一个消费者的行为,它为消费组具备高可用性和伸缩性提供保障,使我们可以既方便又安全地删除消费组内的消费者或者添加消费者。
不过在再均衡发生期间,消费组内的消费者是无法读取消息的,也就是说,在再均衡发生期间的这一小段时间内,消费组会变得不可用。
另外,当一个分区被重新分配给另一个消费者时,消费者当前的状态也会丢失。比如消费者消费完某个分区中的一部分消息时还没有来得及提交消费位移就发生了再均衡操作,之后这个分区又被分配到了消费组内的另一个消费者,原来被消费完的那部分消息又被重新消费一遍,也就是发生了重复消费。
所以,一般情况下,应尽量避免不必要的再均衡的发生。
在之前说明subscribe()方法时提及再均衡监听器ConsumerRebalanceListener,再均衡监听器用来设定再均衡动作前后的一些准备工作或收尾动作。它是一个接口,有两个方法:
1 void onPartitionsRevoked (Collection<TopicPartition> partitions)
这个方法会在再均衡开始之前和消费者停止读取消息之后被调用。可以通过这个回调方法来处理消费位移的提交,以此来避免一些不必要的重复消费现象的发生。partitions表示再均衡前所分配到的分区。
1 void onPartitionsAssigned (Collection<TopicPartition> partitions)
这个方法会在重新分配分区之后和消费者开始读取消费之前被调用。partitions表示再均衡后所分配到的分区。
三、消费者拦截器
生产者有拦截器,消费者也有拦截器,主要在消费到消息或在提交位移时进行一些定制化的操作。
消费者拦截器需要自定义实现org.apache.kafka.clients.consumer.ConsumerInterceptor接口。包含3个方法:
1 2 3 ublic ConsumerRecords<String, String> onConsume (ConsumerRecords<String, String> records) ;public void onCommit (Map<TopicPartition, OffsetAndMetadata> offsets) public void close ()
KafkaConsumer会在poll()方法返回之前调用拦截器的onConsume方法来对消息进行相应的定制化操作,比如修改返回的消息内容、按照某种规则过滤消息。这个方法如果发生异常,那么会被捕获并记录到日志里,但是异常不会向上传递。
KafkaConsumer会在提交消费位移之后调用拦截器的onCommit方法,可以使用这个方法来记录跟踪所提交的位移消息。
在某些业务场景中会对消息设置一个有效期的属性,如果某条消息在既定的时间窗口内无法到达,则被视为无效,它也就不需要再被继续处理了。下面为一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class ConsumerInterceptorTTL implements ConsumerInterceptor <String , String > { private static final long EXPIRE_INTERVAL = 10 * 1000 ; @Override public ConsumerRecords<String, String> onConsume ( ConsumerRecords<String, String> records) System.out.println("before:" + records); long now = System.currentTimeMillis(); Map<TopicPartition, List<ConsumerRecord<String, String>>> newRecords = new HashMap<>(); for (TopicPartition tp : records.partitions()) { List<ConsumerRecord<String, String>> tpRecords = records.records(tp); List<ConsumerRecord<String, String>> newTpRecords = new ArrayList<>(); for (ConsumerRecord<String, String> record : tpRecords) { if (now - record.timestamp() < EXPIRE_INTERVAL) { newTpRecords.add(record); } } if (!newTpRecords.isEmpty()) { newRecords.put(tp, newTpRecords); } } return new ConsumerRecords<>(newRecords); } @Override public void onCommit (Map<TopicPartition, OffsetAndMetadata> offsets) offsets.forEach((tp, offset) -> System.out.println(tp + ":" + offset.offset())); } @Override public void close () } @Override public void configure (Map<String, ?> configs) } }
此外,在消费者中也有拦截链的概念,和生产者的拦截链一样,也是按照interceptor.classes参数配置的拦截器的顺序来一一执行的(配置的时候,各个拦截器之间用逗号隔开)。同样也要提防副作用的发生。如果在拦截器中某个拦截器执行失败,那么下一个拦截器会接着从上一个执行成功的拦截器继续执行。
四、多线程实现
KafkaProducer是线程安全的,KafkaConsumer是非线程安全的。KafkaConsumer中定义了一个acquire()方法,用来检测当前是否只有一个线程在操作,若有其他线程正在操作会抛出ConcurrentModificationException异常。KafkaConsumer的每个公用方法在执行之前都会调用acquire方法,至于wakeup是个例外。
acquire跟我们通常说的锁(synchronized或lock等)不同,它不会造成阻塞等待,我们可以将其看作一个轻量级锁,它仅通过线程操作计数标记的方式来检测线程是否发生了并发操作,以此保证只有一个线程在操作。
KafkaConsumer非线程安全并非意味着我们在消费消息的时候只能以单线程的方式执行,我们可以通过多线程的方式来实现消息消费,多线程的目的是为了提高整体的消费能力。多线程的实现方式有多种,第一种也是最常见的方式:线程封闭,即为每个线程实例化一个KafkaConsumer对象。
一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class FirstMultiConsumerThreadDemo public static final String brokerList = "localhost:9092" ; public static final String topic = "topic-demo" ; public static final String groupId = "group.demo" ; public static Properties initConfig () Properties props = new Properties(); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true ); return props; } public static void main (String[] args) Properties props = initConfig(); int consumerThreadNum = 4 ; for (int i = 0 ; i < consumerThreadNum; i++) { new KafkaConsumerThread(props, topic).start(); } } public static class KafkaConsumerThread extends Thread private KafkaConsumer<String, String> kafkaConsumer; public KafkaConsumerThread (Properties props, String topic) this .kafkaConsumer = new KafkaConsumer<>(props); this .kafkaConsumer.subscribe(Arrays.asList(topic)); } @Override public void run () try { while (true ) { ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100 )); for (ConsumerRecord<String, String> record : records) { System.out.println(record.value()); } } } catch (Exception e) { e.printStackTrace(); } finally { kafkaConsumer.close(); } } } }
如果对消息的处理很快,那么poll拉起的频次也会更高,进而整体消费的性能也会提升;不过,如果消息处理比较慢,比如进行一个事务性操作,或者等待一个RPC的同步相应,那么poll频次就会降低,造成整体消费性能的下降。这边考虑优化,提升整体性能,将处理消息模块改成多线程的实现方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 public class ThirdMultiConsumerThreadDemo public static final String brokerList = "localhost:9092" ; public static final String topic = "topic-demo" ; public static final String groupId = "group.demo" ; public static Properties initConfig () Properties props = new Properties(); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true ); return props; } public static void main (String[] args) Properties props = initConfig(); KafkaConsumerThread consumerThread = new KafkaConsumerThread(props, topic, Runtime.getRuntime().availableProcessors()); consumerThread.start(); } public static class KafkaConsumerThread extends Thread private KafkaConsumer<String, String> kafkaConsumer; private ExecutorService executorService; private int threadNumber; public KafkaConsumerThread (Properties props, String topic, int threadNumber) kafkaConsumer = new KafkaConsumer<>(props); kafkaConsumer.subscribe(Collections.singletonList(topic)); this .threadNumber = threadNumber; executorService = new ThreadPoolExecutor(threadNumber, threadNumber, 0L , TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(1000 ), new ThreadPoolExecutor.CallerRunsPolicy()); } @Override public void run () try { while (true ) { ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100 )); if (!records.isEmpty()) { executorService.submit(new RecordsHandler(records)); } } } catch (Exception e) { e.printStackTrace(); } finally { kafkaConsumer.close(); } } } public static class RecordsHandler extends Thread public final ConsumerRecords<String, String> records; public RecordsHandler (ConsumerRecords<String, String> records) this .records = records; } @Override public void run () for (ConsumerRecord<String, String> record : records) { System.out.println(record.value()); } } } }
RecordsHandler就是用来处理消息的,KafkaConsumerThread类对应的是一个消费线程,里面通过线程池的方式来调用RecordsHandler处理一批批的消息。注意KafkaConsumerThread中的ThreadPoolExecutor里的最后一个参数设置的是CallerRunsPolicy,这样可以防止线程池的总体消费能力根本不上poll拉取的能力,从而导致异常现象的发生。这个方法具有横向扩展能力,可以通过开启多个KafkaConsumerThread实例来进一步提高整体的消费能力。
下表总结了两种方法的优缺点:
方法
优点
缺点
方法1 (每个线程维护一个KafkaConsumer)①方便实现
①更多的TCP连接开销(每个线程都要维护若干个TCP连接)
方法2 (单个(或多个)consumer,多个worker线程)①可独立扩展consumer数和worker数,伸缩性好
①实现麻烦
对于第二种方式,消息的顺序性不能保证,考虑使用一个共享变量offsets来参与提交。每一个处理消息的RecordHandler类在处理完消息后都将对应的消费位移保存到共享变量offsets中(注意,这里的offsers是一个map结构,即<分区,offset>的结构),每次消费完分区消息后,就记录一下。这里为防止出现并发问题,需要对offsers的读写进行加锁处理。